[CL]《Pathways of Thoughts: Multi-Directional Thinking for Long-form Personalized Question Answering》A Salemi, C Li, M Zhang, Q Mei, Z Li... [University of Massachusetts Amherst & Google DeepMind] (2025)
个性化问答迎来新突破:Pathways of Thoughts(PoT)多向思维策略助力长文本个性化回答
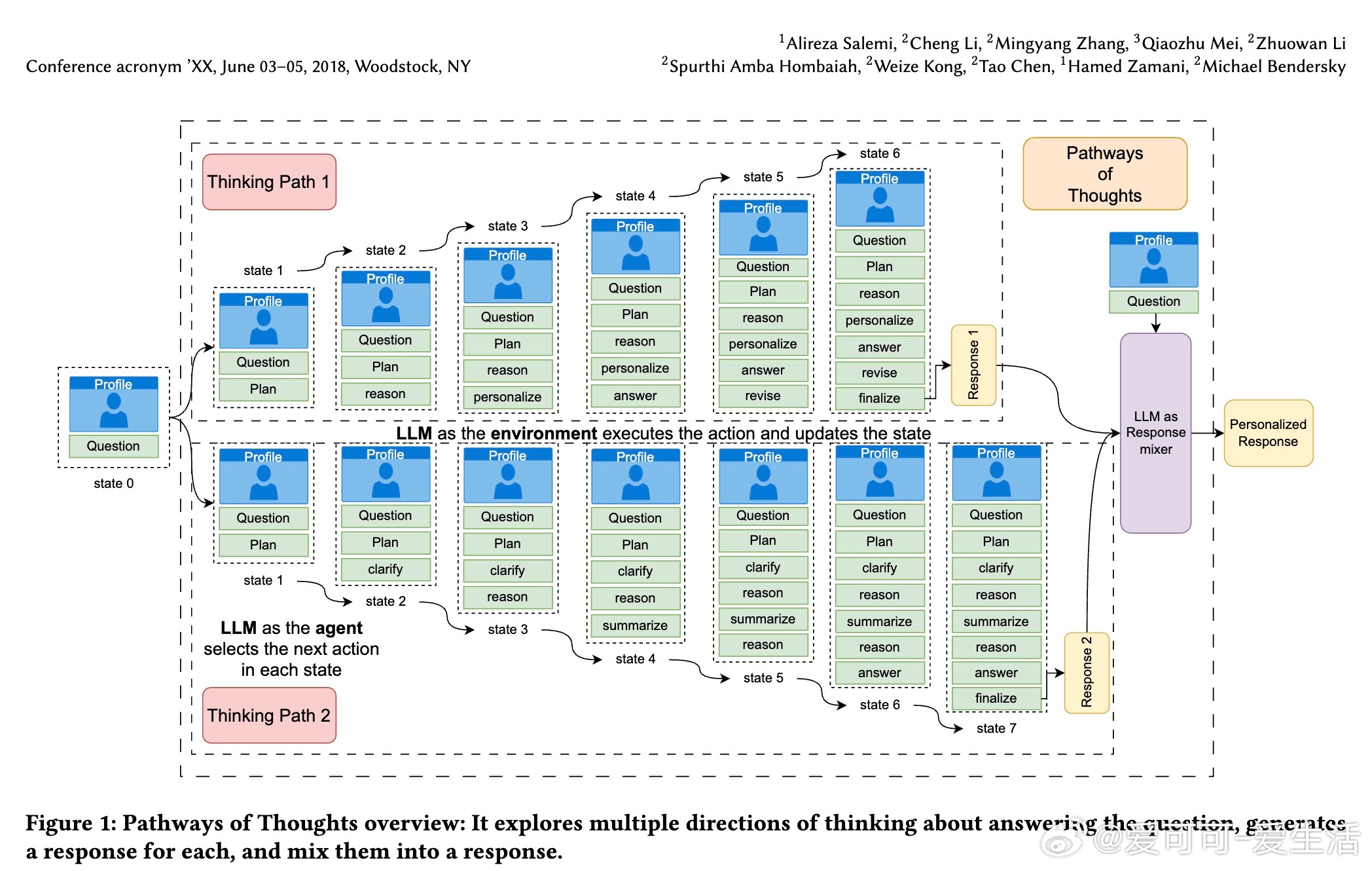
• PoT将大型语言模型(LLM)的推理过程建模为马尔可夫决策过程(MDP),在推理阶段动态选择“规划”、“推理”、“个性化”、“修订”等多种认知操作,探索多条思维路径。
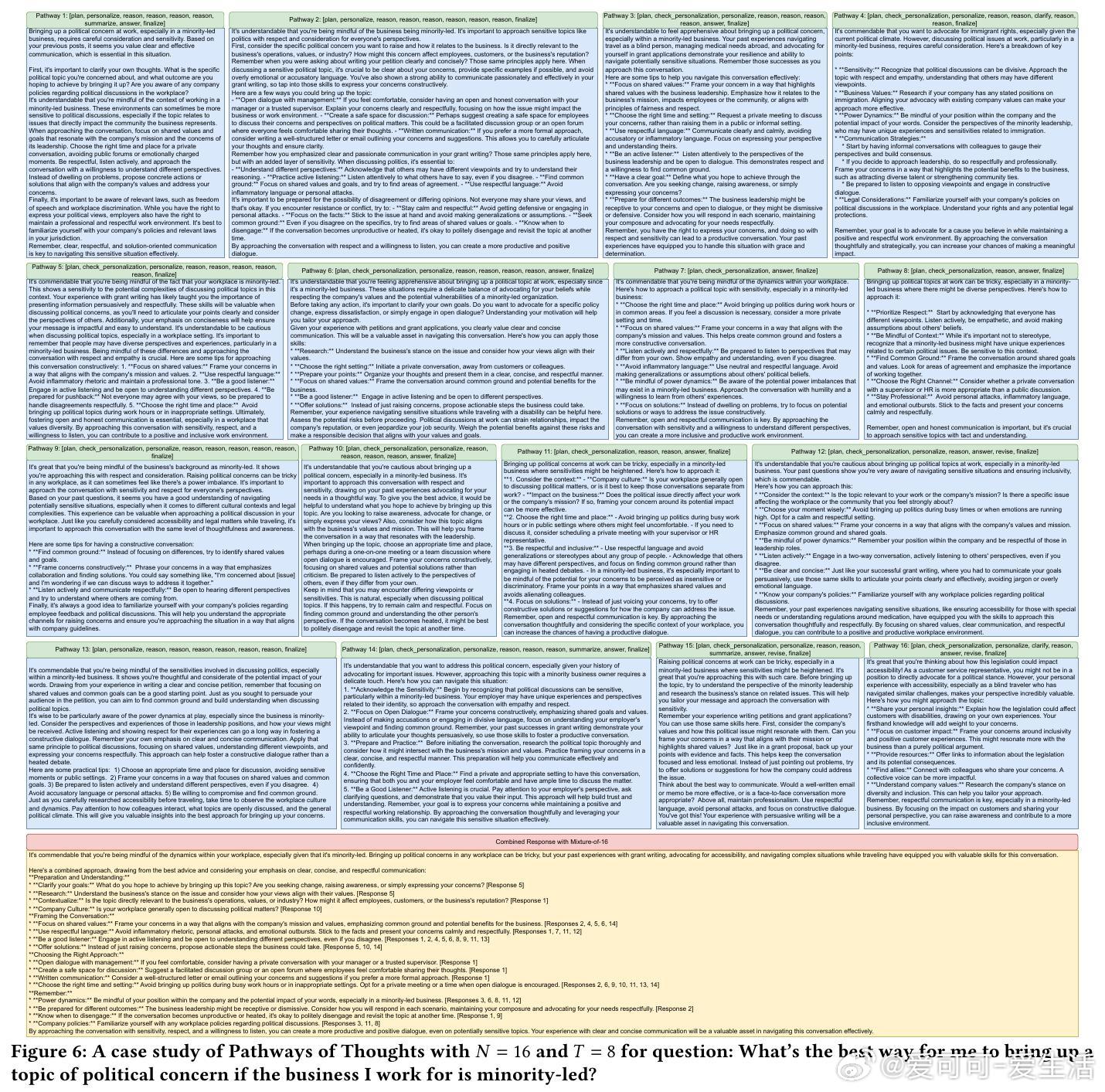
• 多条路径生成风格迥异、视角多元的候选回答,后续通过提取用户偏好重点,采用“混合多答案(Mixture-of-N)”策略将多条路径结果融合,确保最终回答既正确又符合用户背景与喜好。
• 该方法无需对模型进行额外微调,适配任何支持长上下文的LLM,具备强泛化能力,实验证明在LaMP-QA个性化问答基准上,PoT实现最高13.1%相对提升,且66%的人类评测优选PoT回答。
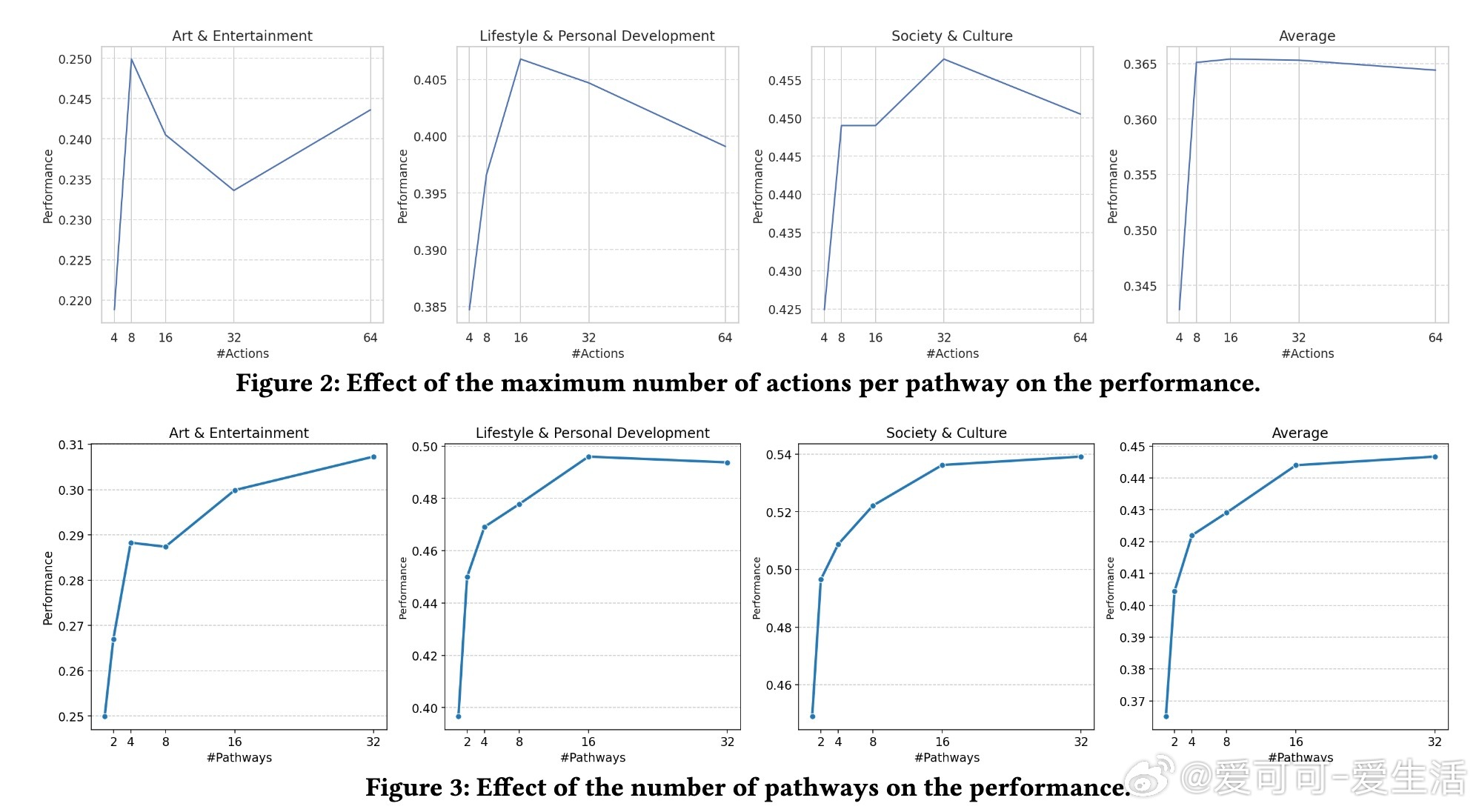
• 设计上,PoT通过两种多样化路径生成方式实现多角度思考:一是通过调整用户历史上下文子集,二是提高规划环节采样温度;多路径间相互补充,避免单一路径思维局限。
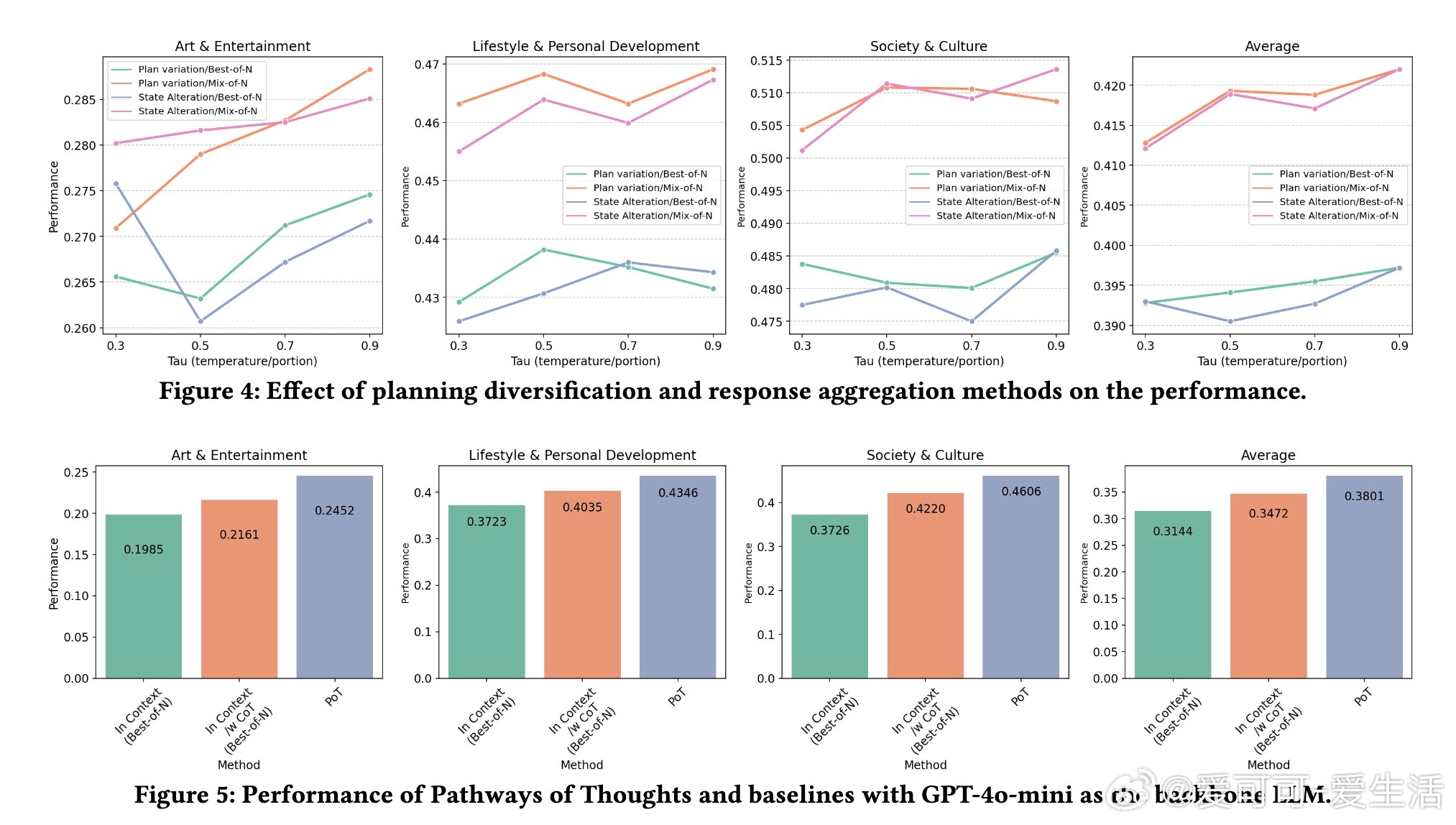
• 研究还发现,路径长度约8步最优,路径数越多性能提升趋缓,表明存在思维多样性的边际效应;“混合多答案”融合优于“最佳答案选取”,更接近人类综合判断。
• 该方法在艺术娱乐、生活方式、社会文化三大领域均表现出色,且成功迁移至多种LLM(如Gemini 1.5 Pro、GPT-4o-mini),显示其稳健性和广泛适用性。
心得:
1. 个性化问答的正确性标准并非单一客观事实,而是需结合用户背景、隐含偏好实现深度对齐,单纯输入上下文难以满足。
2. 模型推理过程若能模拟人类多样化思考路径,逐步探索不同解决策略,并通过融合综合,能显著提升个性化响应质量。
3. 推理计算资源的有效利用(如多路径、多步骤)比单纯扩展模型参数更能提升复杂任务表现,尤其适合开放式文本生成场景。
了解更多🔗arxiv.org/abs/2509.19094
人工智能大语言模型个性化问答多路径推理自然语言处理