[CL]《Soft Tokens, Hard Truths》N Butt, A Kwiatkowski, I Labiad, J Kempe... [University of Amsterdam] (2025)
连续“软”tokens强化学习训练链式思维,突破离散token限制,实现更丰富推理路径与更强泛化能力。
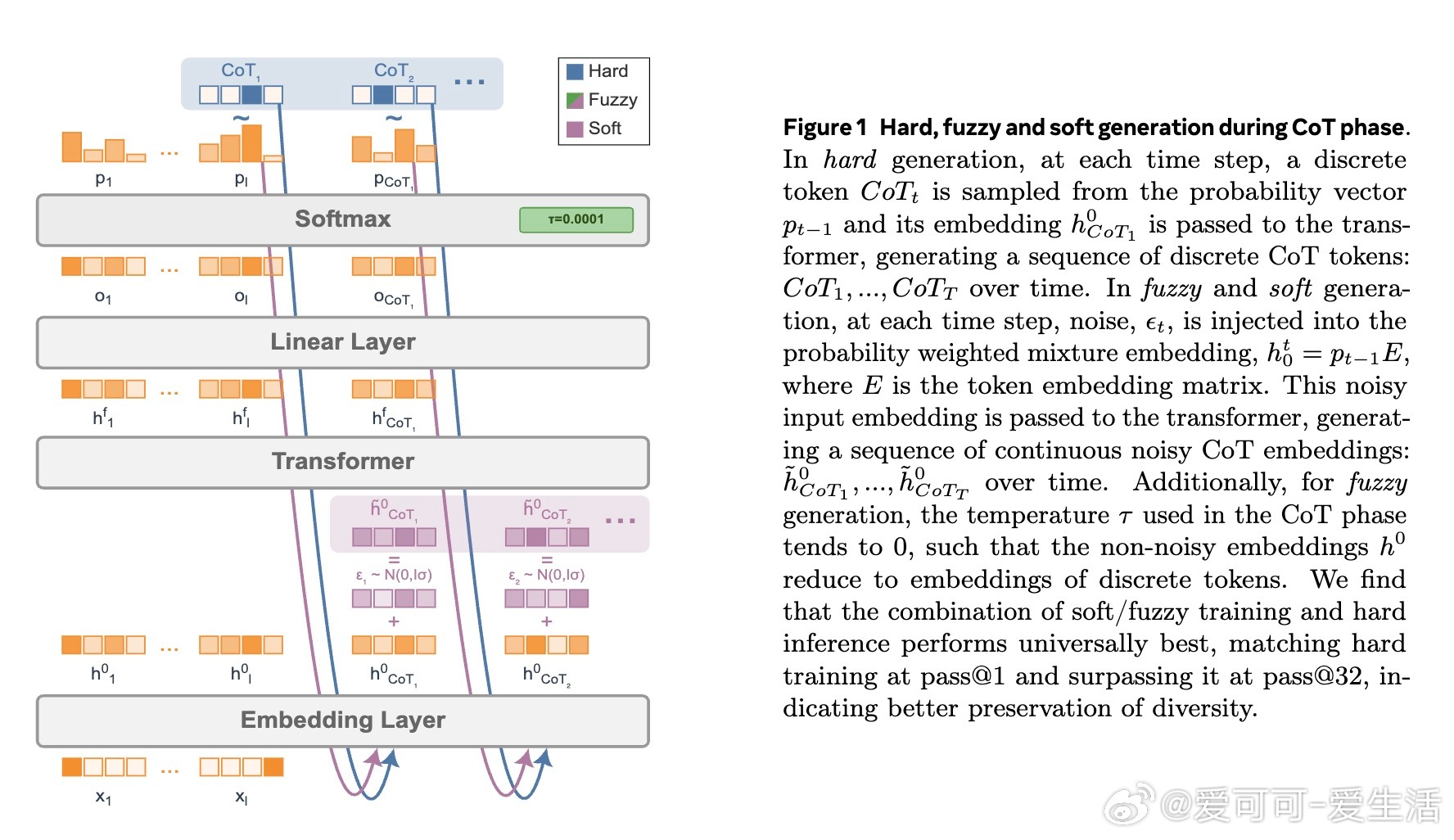
• 传统链式思维(CoT)依赖离散token,推理路径单一、顺序限制表达力;软tokens通过概率混合并注入高斯噪声,模拟多条推理路径叠加,提升表达能力。
• 本文首次提出基于强化学习的连续CoT训练方法,无需蒸馏真实离散CoT,计算开销极低,可扩展至数百token,兼顾效率与规模。
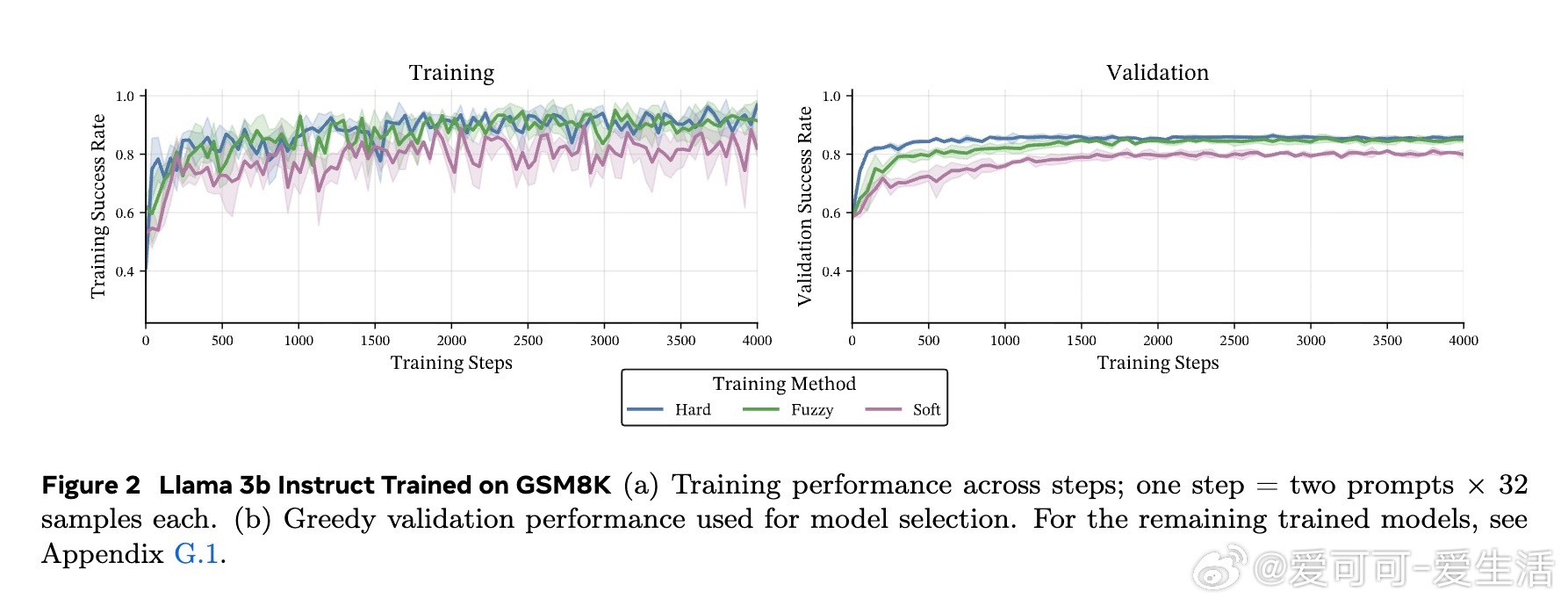
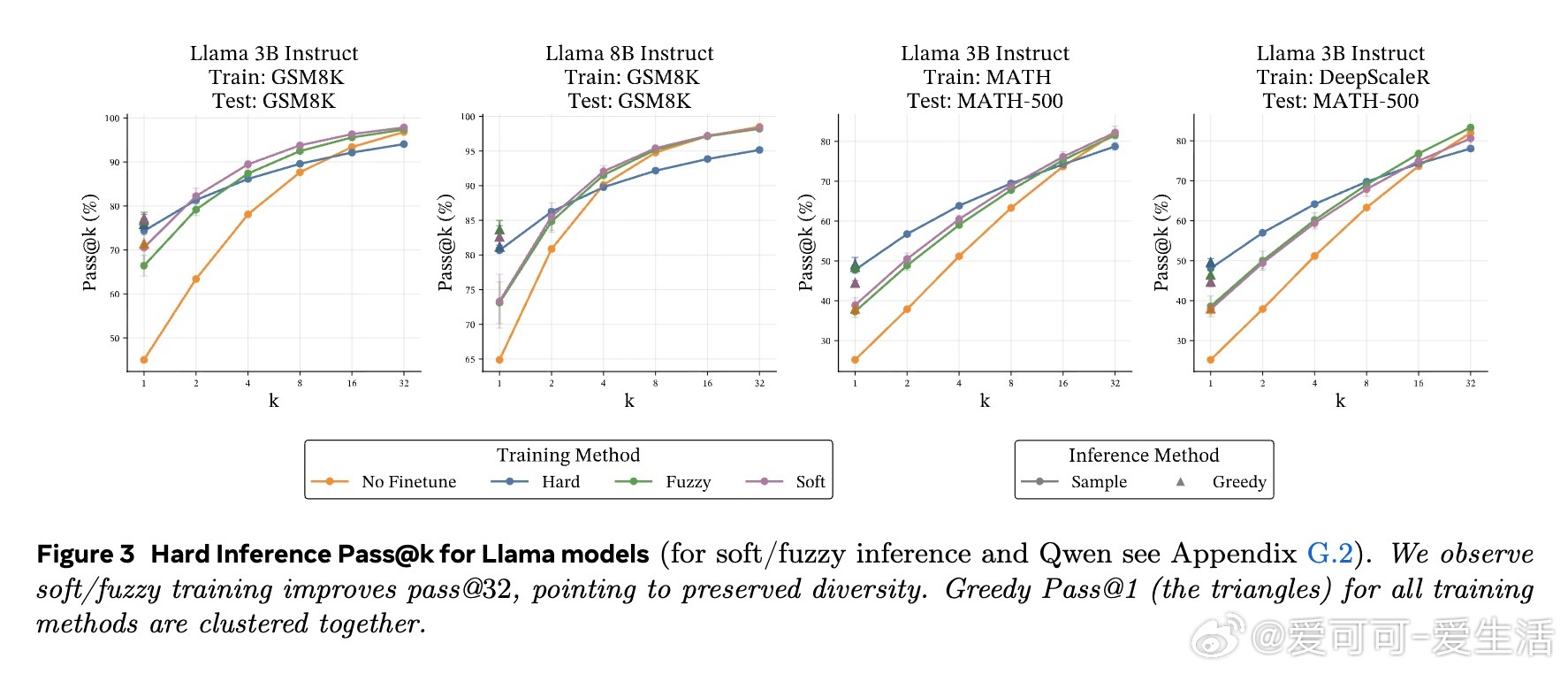
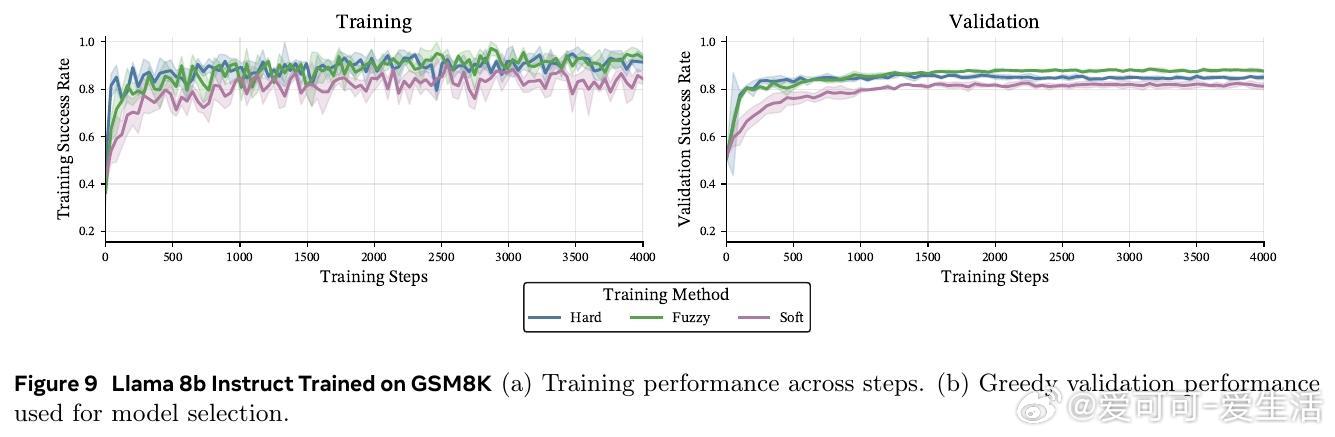
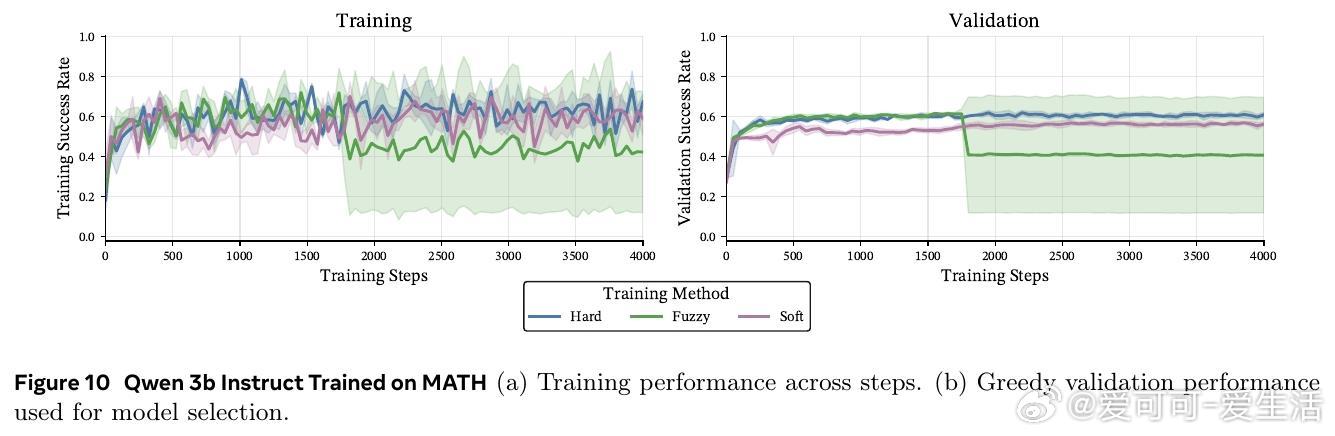
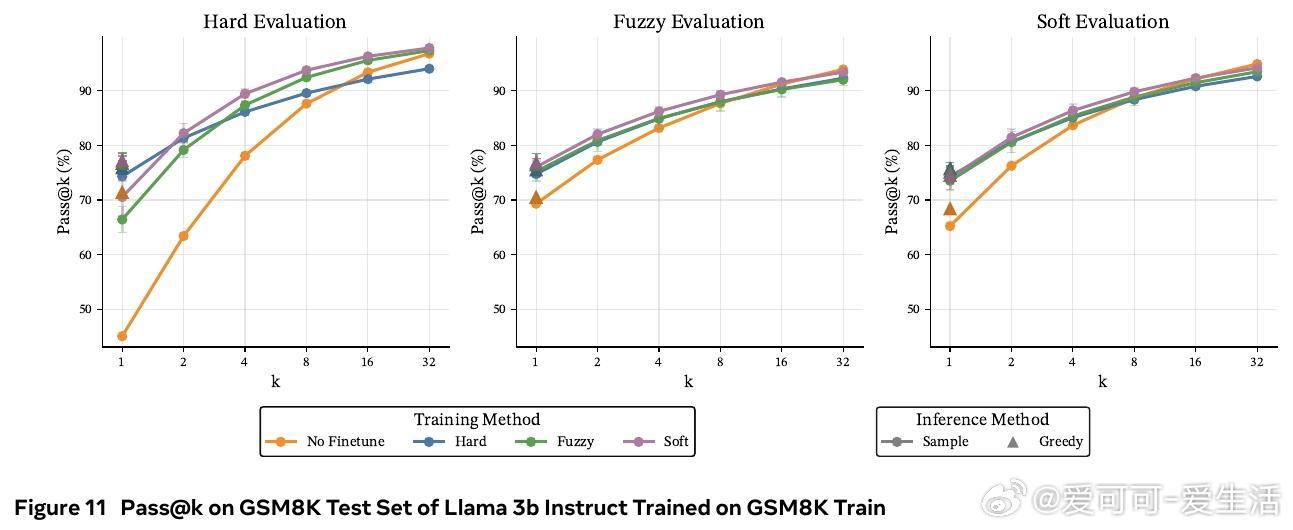
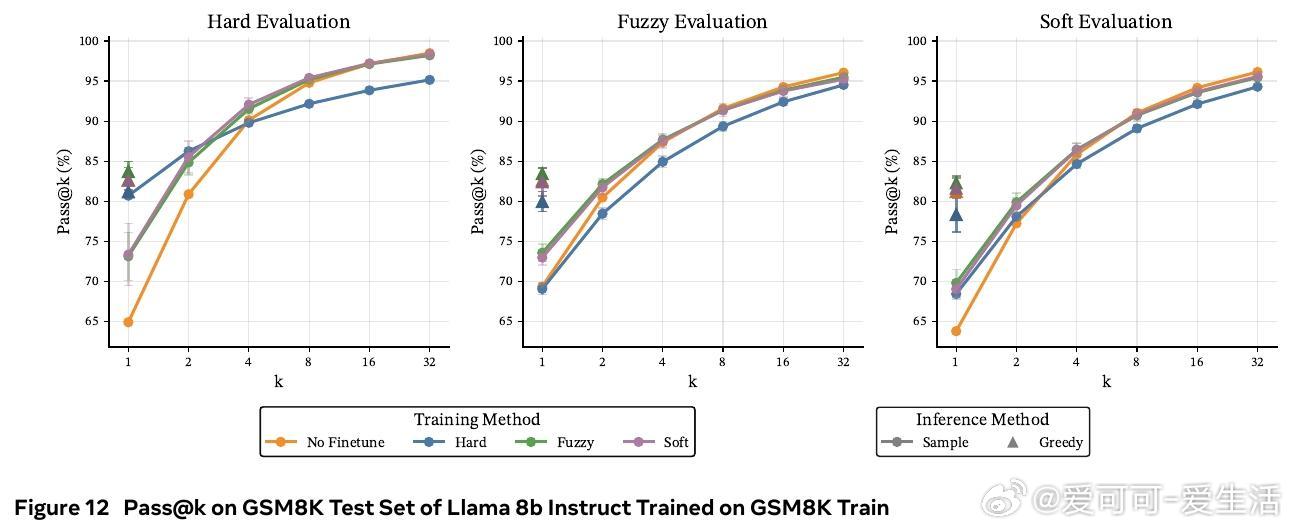
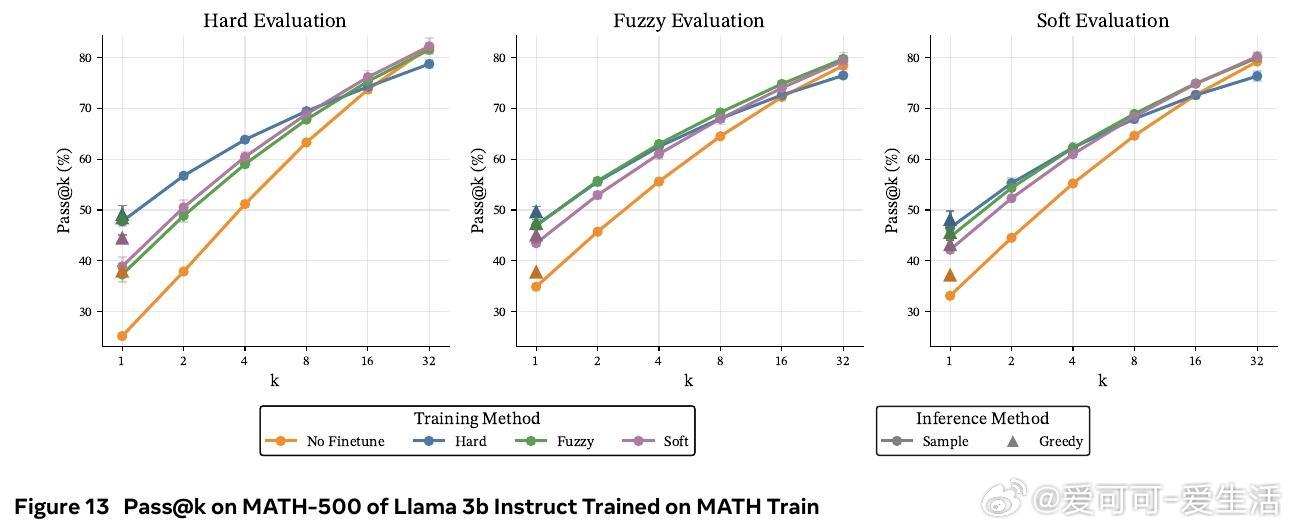
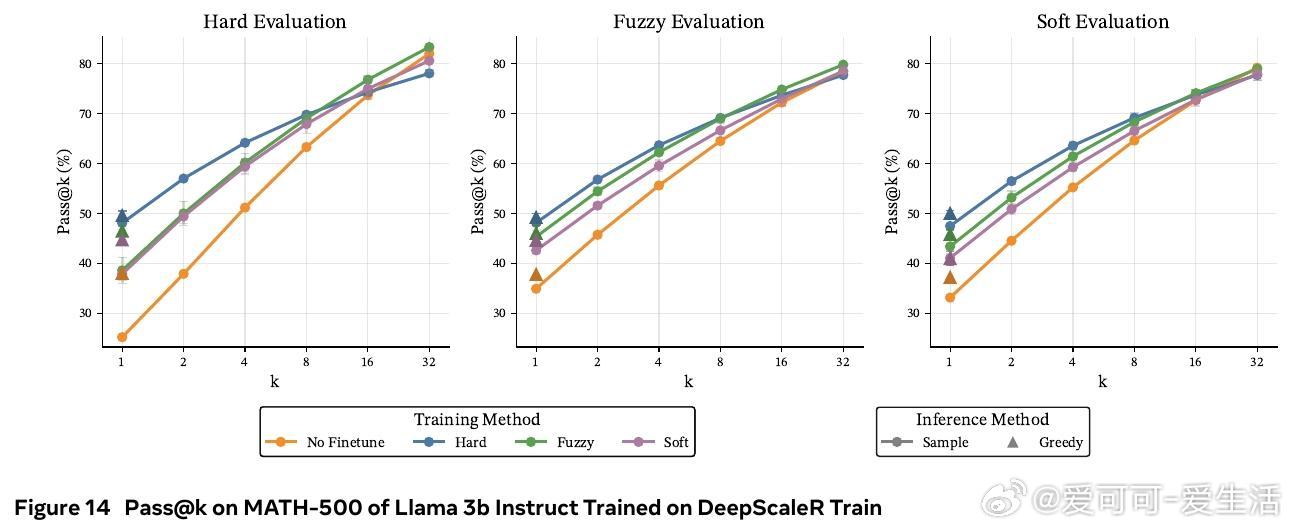
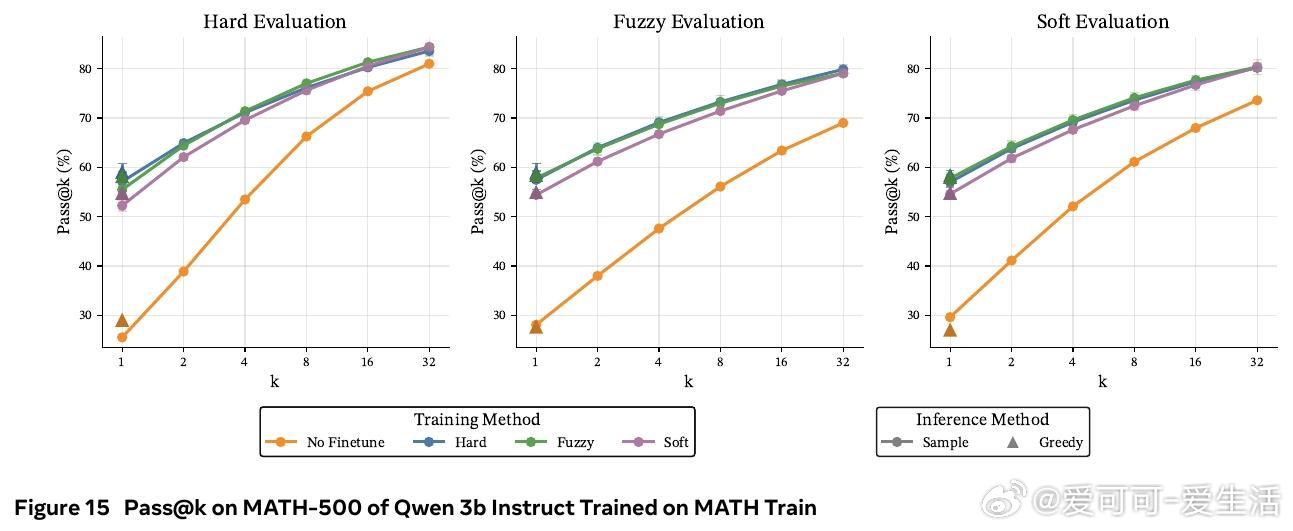
• 在数学推理基准(GSM8K、MATH-500、OlympiadBench)及多种模型(Llama 3B/8B,Qwen 3B)上,软token训练在pass• 训练时采用软tokens,推理时依旧使用离散tokens,兼具软训练优势与标准部署便利性,避免了软推理时性能下降的现实问题。
• 软token训练更好地保持了基础模型在领域外任务(HellaSwag、MMLU、ARC)上的表现,避免了离散CoT训练带来的过拟合与性能退化。
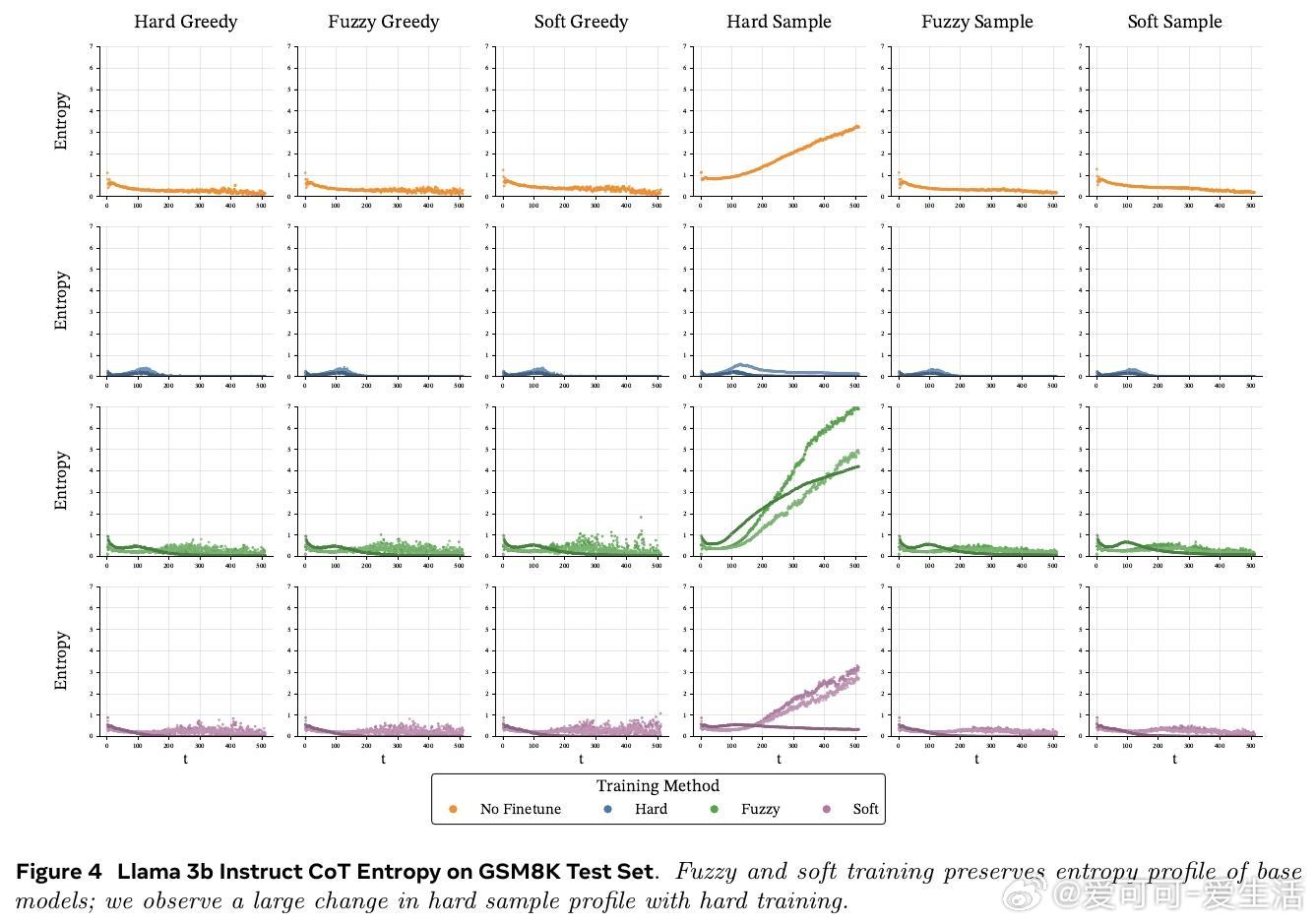
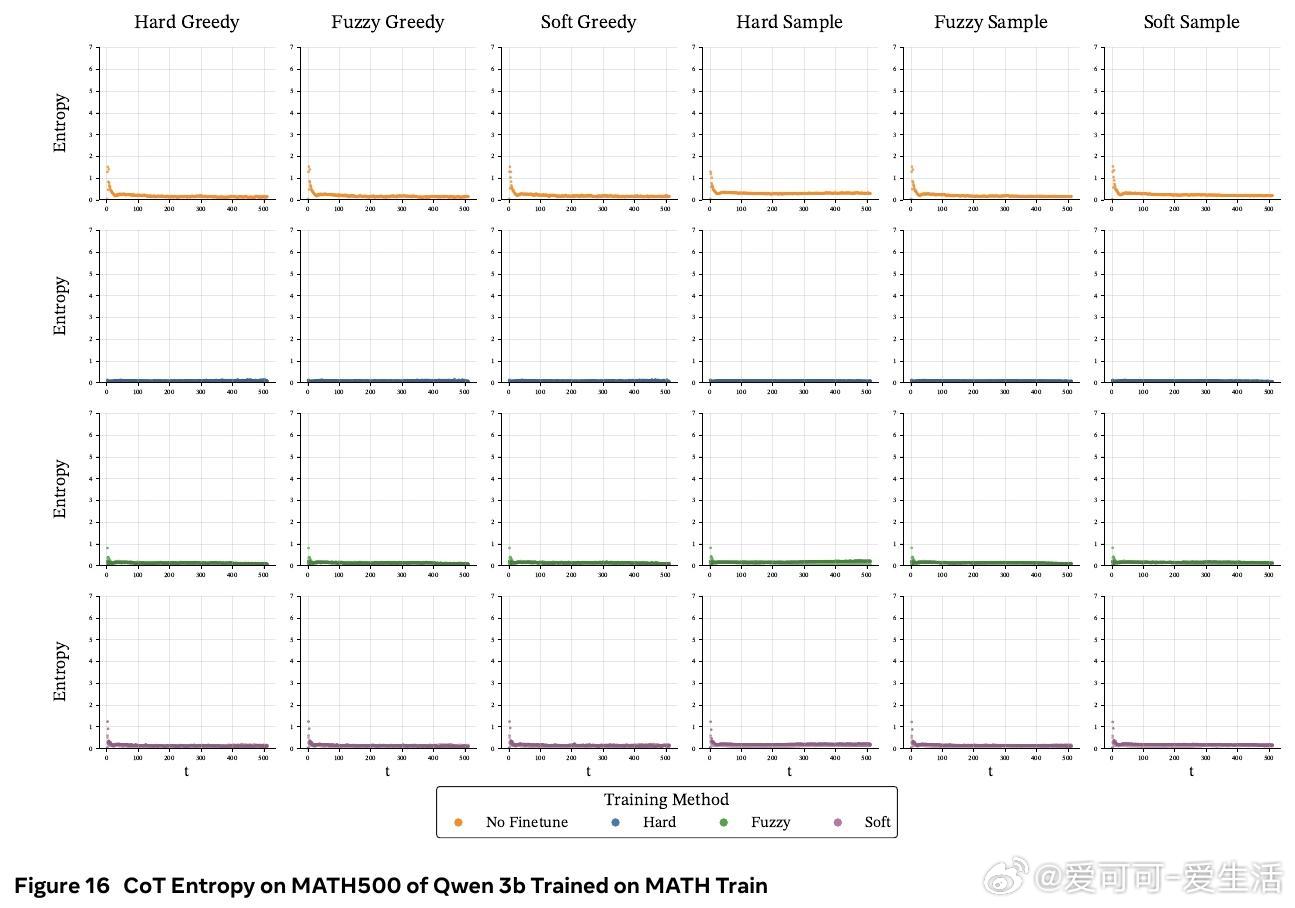
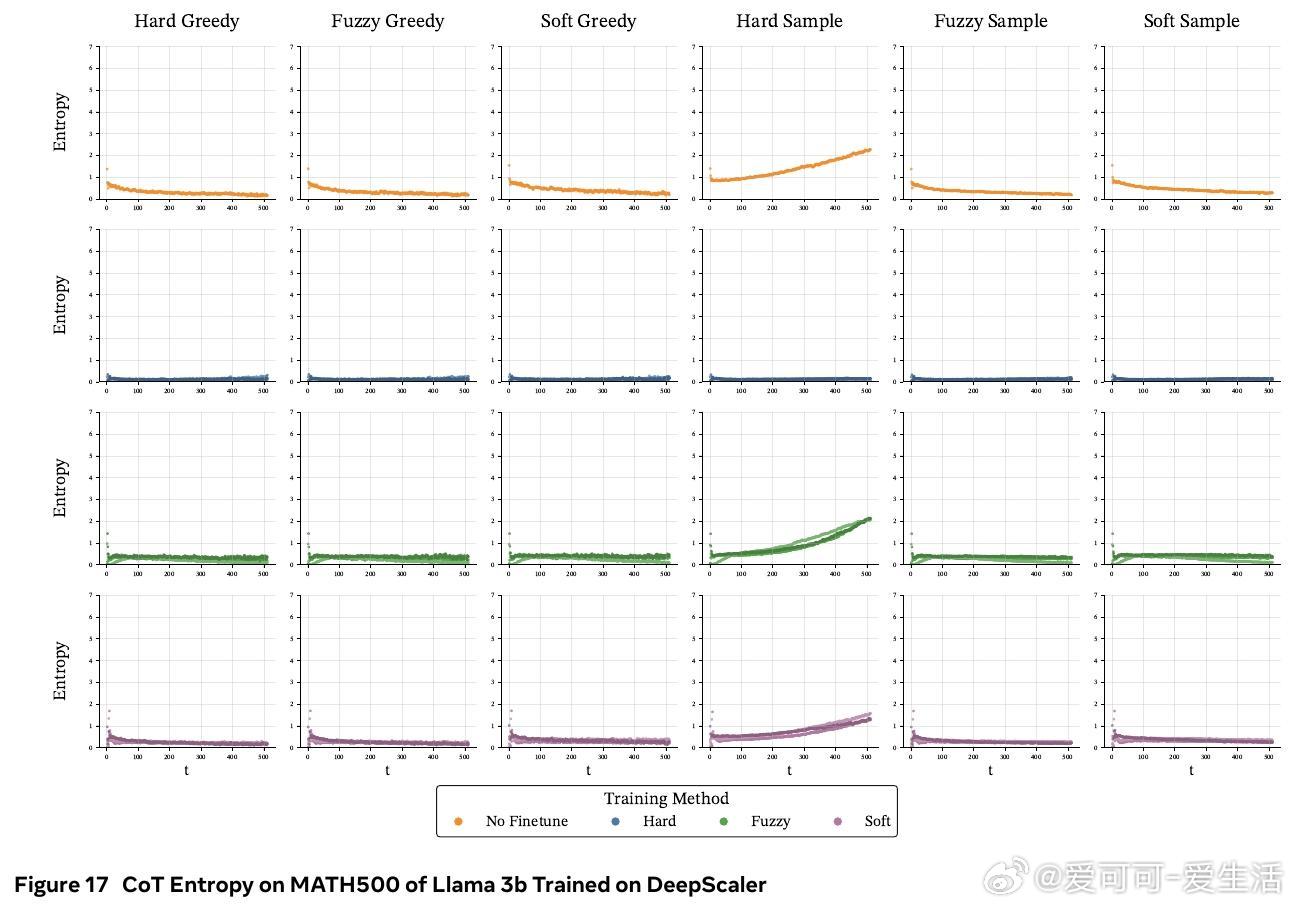
• 熵分析显示,软训练保留了基础模型的高熵特性,避免离散训练导致的过度自信、路径多样性下降和性能崩溃。
心得:
1. 连续token的引入打破推理路径单一限制,通过概率混合和噪声探索,增大模型对多条推理路径的覆盖面,实现更丰富的思考过程。
2. 强化学习为训练连续CoT提供了有效工具,避免了传统全程反向传播的巨大计算负担,实用且可扩展。
3. 训练与推理解耦设计(软训练、硬推理)兼顾了理论创新和实际部署需求,强调模型演进应兼顾应用可行性。
🔗arxiv.org/abs/2509.19170
大语言模型链式思维连续Tokens强化学习模型泛化