[LG]《Performative Thinking? The Brittle Correlation Between CoT Length and Problem Complexity》V Palod, K Valmeekam, K Stechly, S Kambhampati [Arizona State University & Yale University] (2025)
中大型语言模型(LLM)推理链长度与实际问题复杂度的关联远比直觉复杂。基于对A*搜索算法解迷宫任务的严格实验发现:
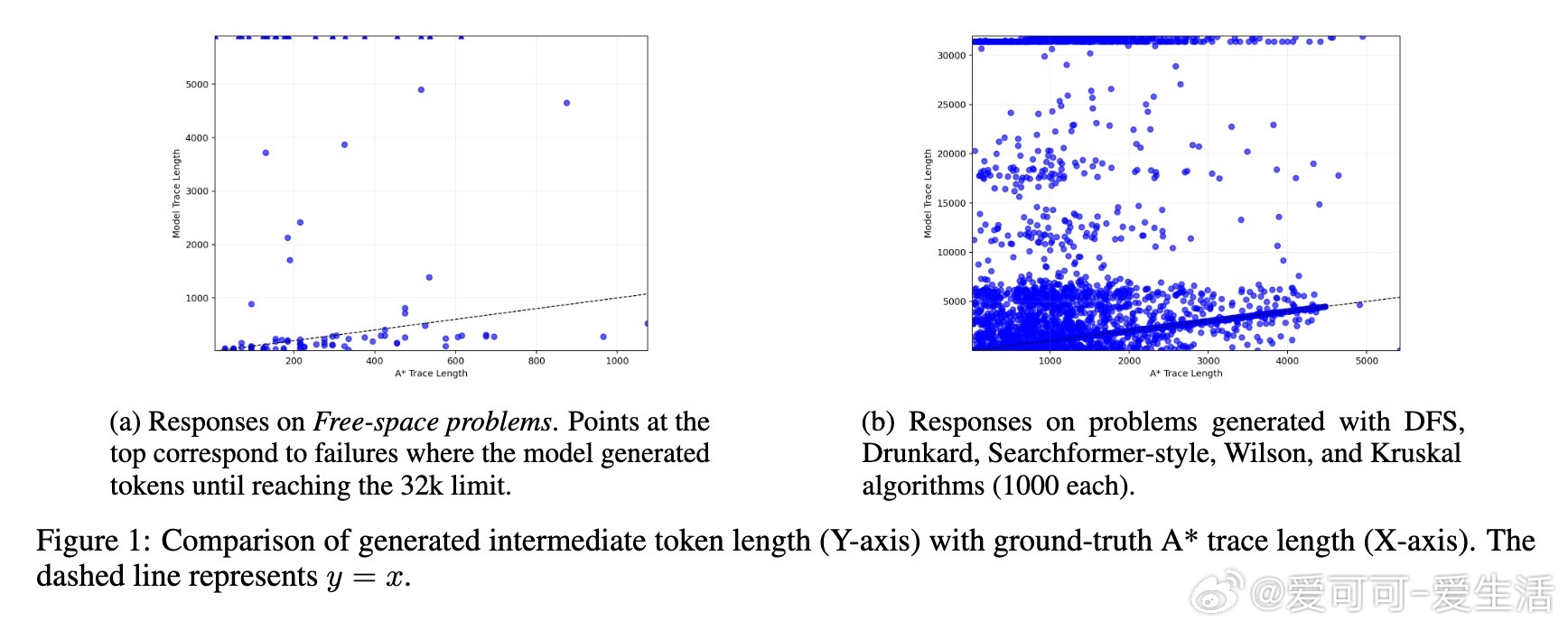
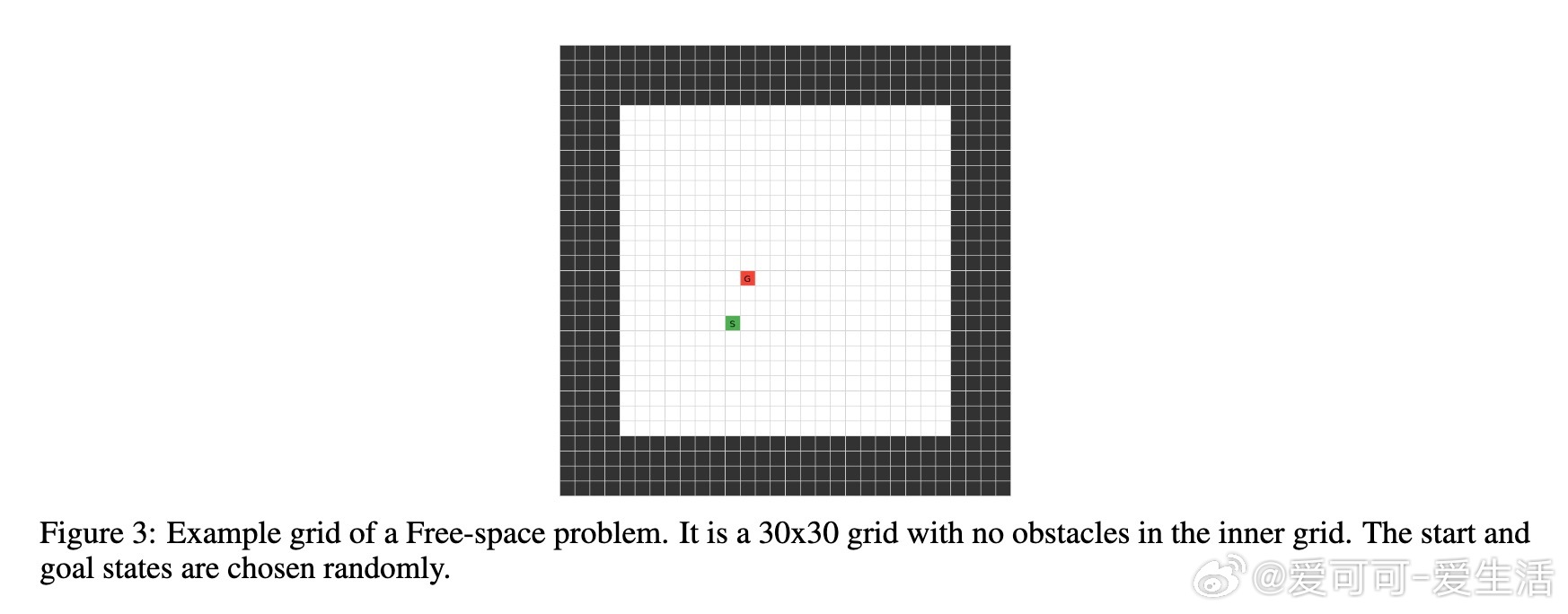
• 训练自零的Transformer在最简单的无障碍路径规划任务中,推理链(中间token序列)长度往往异常冗长,且多次无法给出有效解答,质疑“推理长度即思考时间”的假设。
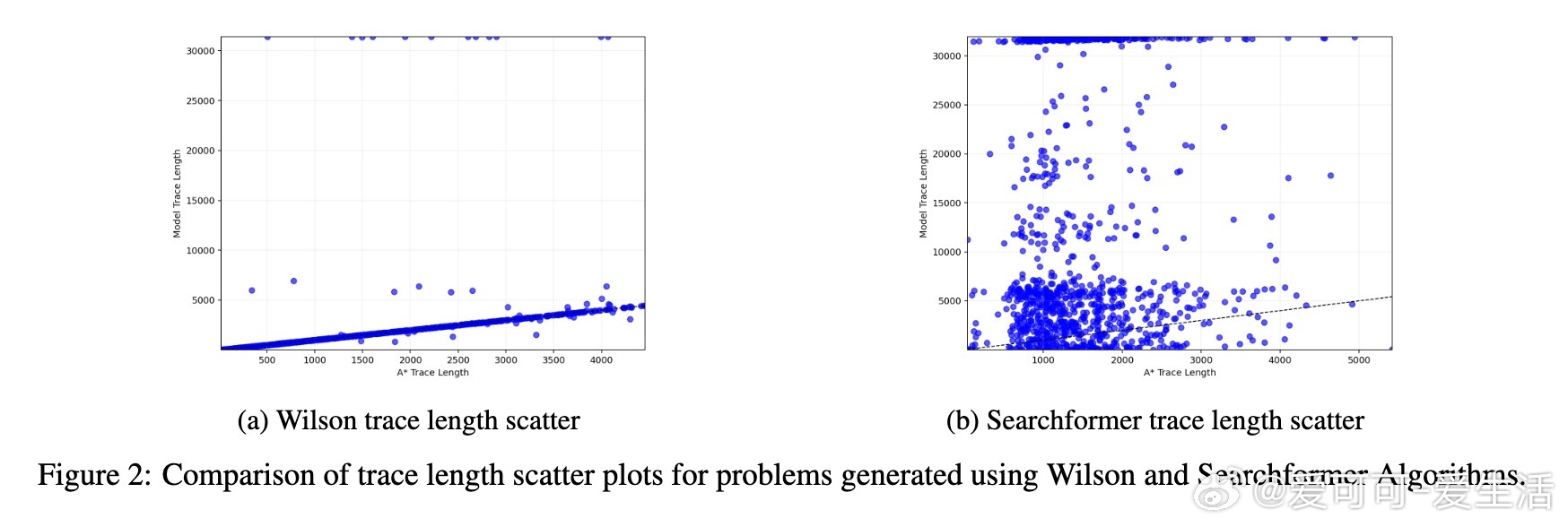
• 在训练分布内(如Wilson算法生成的迷宫)测试时,推理链长度与A*算法的操作数间存在一定弱相关,但这更多体现为对训练数据的近似回忆,而非真正的问题难度适应性计算。
• 一旦测试任务分布远离训练样本(如Searchformer风格迷宫),推理链长度与问题复杂度完全脱钩,显示模型并未根据实际计算需求调整推理长度。
心得:
1. 模型生成的中间推理步骤并非体现“思考”本质,而是训练数据分布的反映,推理长度无法作为任务难度的可靠指标。
2. 过度依赖链式推理长度来衡量模型推理能力存在误导风险,需警惕“推理时间即计算成本”的表面印象。
3. 要深入理解和解释大型模型的推理机制,应采用更严谨、可验证的实验设计,避免简单类人化比喻。
研究使用了多种迷宫生成算法,构建了精细可控的评测体系,训练了约3.8亿参数的Qwen2.5变体模型,确保结论具有高度信服力和可复现性。
详情见🔗arxiv.org/abs/2509.07339
人工智能大模型推理链式思维模型解释机器学习