"全球AI基建进入网络决胜时代:中科曙光全自研scaleFabric以800Gb/s带宽、1微秒延迟实现11.4万卡组网,让中国算力真正跑在中国网络上——当万卡集群成为标配,决定胜负的已不再是芯片数量,而是让算力零损耗传输的那张网。"
全球AI基建正在疯狂提速,算力竞赛的下半场,哨声已经吹响。 “星际之门计划”20个数据中心落地,欧洲80亿欧元砸向智算云,国内算力规模稳居全球第二——这场竞赛的烈度,已经远超几年前的市场预期。 但有一个问题正在浮出水面:卡堆起来了,网跟得上吗? 业内都知道一个数字:稠密模型的通信耗时占10%~20%,到了MoE架构,这个比例直接飙到40%-60%。这意味着,你投几十亿建一个万卡集群,如果网络效率不行,小一半算力都在空转等数据。
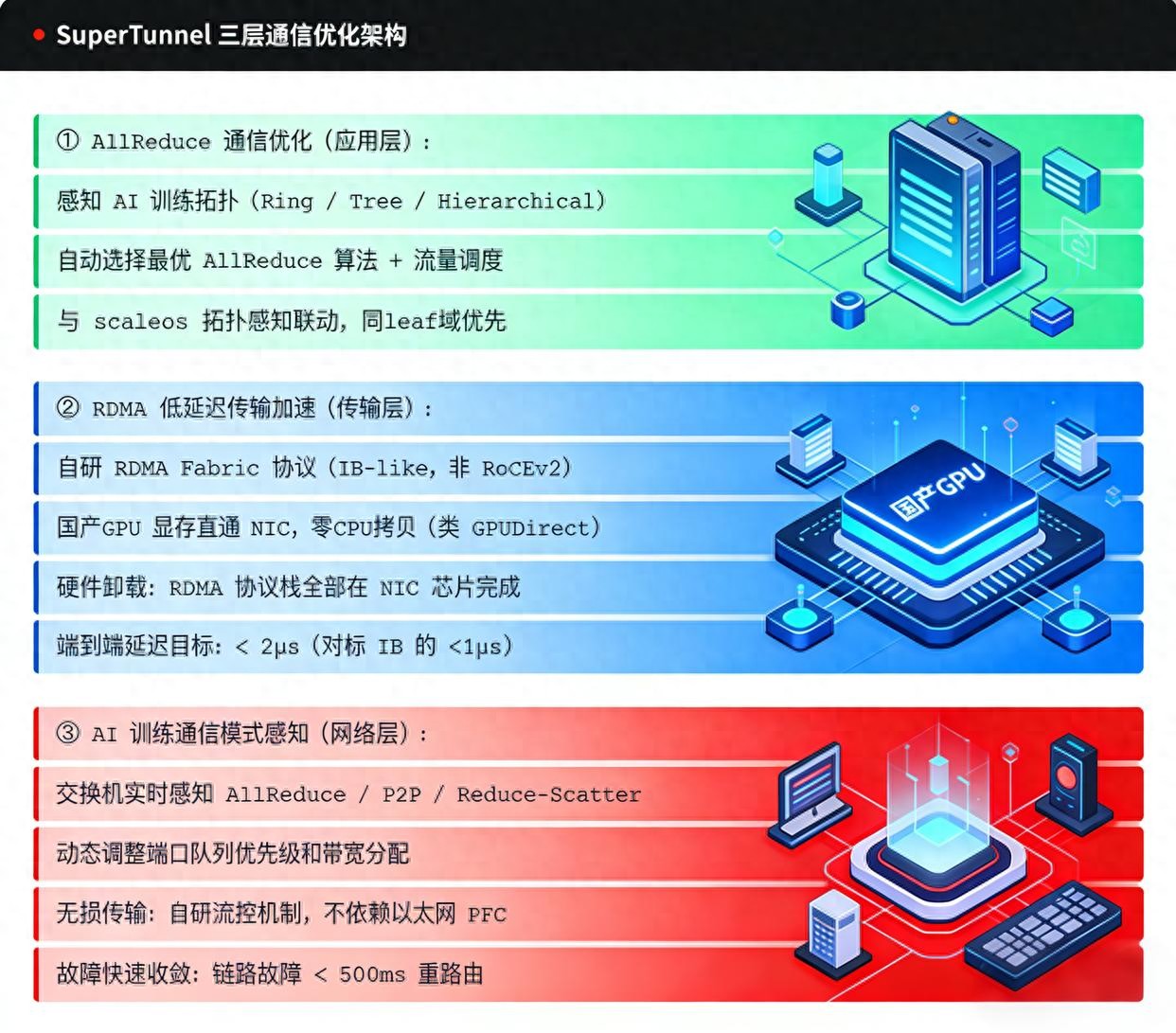
算力竞赛的上半场拼的是单卡性能,下半场拼的是网络效率。这个转折点,已经到了。 所以中科曙光最近发布全自研scaleFabric这件事,值得多说两句。 不是因为它填补了国产原生InfiniBand的空白——虽然确实填补了,而是因为它切中了这轮竞赛的真正赛点:当算力规模堆到一定程度,决定集群价值的,不再是堆了多少卡,而是让算力“跑起来”的那张网。 看数据:800Gb/s单端口带宽,端到端延迟低于1微秒,单子网集群可扩展至11.4万张卡,网络成本较进口IB降低约30%。更关键的是落地——国家超算互联网核心节点,36小时完成3套万卡集群部署,稳定运行超10个月,服务超10000名用户。
在高速网络领域,一直有两条路线:InfiniBand精准高效但被海外垄断,RoCE依托以太网但需要复杂优化才能接近“无损”。过去国内用户没有选择——要么接受RoCE的性能折中,要么忍受IB的高昂成本和供应限制。
曙光的解法很直接:自己造一条路。历时三年,从112G SerDes IP到上层管理软件,100%全栈自研,既继承IB技术优势,又实现自主可控。三年时间,把“中国算力跑在中国网络上”从愿景变成现实。 回头看这轮全球基建竞赛,其实释放了一个明确信号:AI基础设施的竞争,已经从“有没有算力”进入到“算力好不好用”的阶段。而在这个阶段,网络不再是算力的配角,而是核心变量。 中国信通院已经在联合中科曙光等单位推进智算网络行业标准制定。这意味着,中国团队正在从市场参与者转向规则制定者。 毕竟,算力规模全球第二这个位置,想坐稳靠的不是数字,是能让算力真正跑起来的那张网。