当AI大模型算力跨入万卡集群时代,网络互联不再是后台配角,而是决定算力效能的核心命脉。RDMA技术作为高速互联的关键,正从幕后走到台前,而国产厂商突破海外垄断的IB路线,成为补全AI产业链的关键一战。
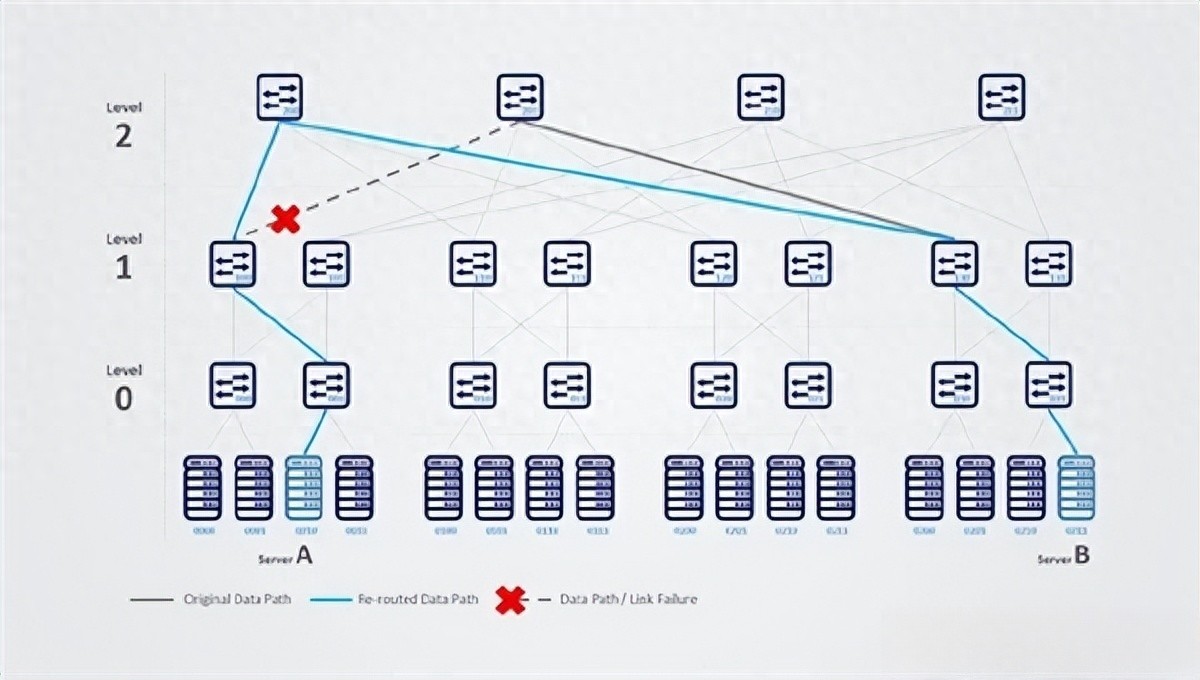
一、万卡智算逼疯网络:RDMA成必争之地 过去十年,AI算力的提升主要依赖单卡性能迭代,但当模型参数突破万亿级别,单卡算力再强也无法支撑训练需求,万卡级集群成为标配。此时,集群内数万节点的数据传输效率,直接决定了整体算力的发挥水平。 这就好比一支百万大军,每个士兵的单兵作战能力再强,如果后勤补给线拥堵,整体战斗力也会大打折扣。RDMA技术的核心价值,就是让节点间的数据传输绕过操作系统内核,直接访问内存,把CPU从繁琐的数据中转工作中解放出来,相当于给大军打通了直达前线的高速补给线。 万卡时代的网络瓶颈本质是“算力协同效率”的竞争,而非单节点算力。据行业测算,网络延迟每增加100ns,模型训练效率可能下降5%-8%,这是此前中小集群从未遇到过的量级挑战。
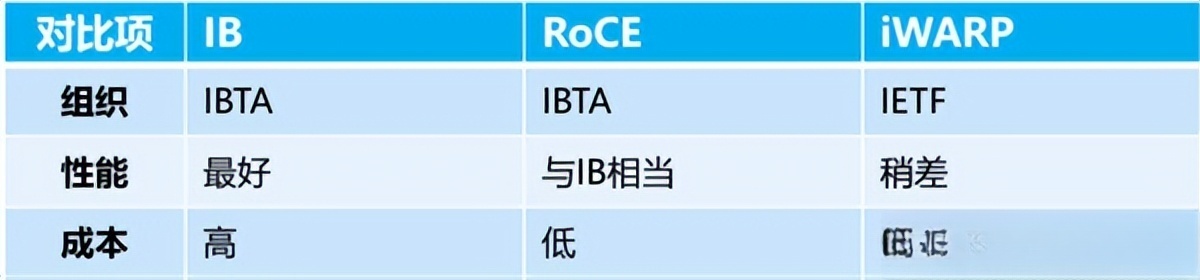
二、IB与RoCE的硬核对决:不止是性能差 当前RDMA技术主要有三大路线,其中iWARP性能最弱已逐渐被淘汰,市场主要被IB和RoCE瓜分。IB是业内公认的顶配方案,性能顶尖但被英伟达旗下的Mellanox垄断;RoCE则被视为IB的低成本替代,也是国内厂商此前的主要布局方向。 但在万卡级集群场景下,RoCE的先天缺陷被无限放大。从带宽看,最新IB网络已达400G,而国内RoCE最高仅200G,差了整整一代;从延迟看,IB交换机做到“收到即发”,延迟低至100ns,RoCE则需要“存储转发”,延迟高达300-500ns。 服务器集群场景 / 蓝色科技感的服务器机柜与网络连线场景图 。
三、国产突围:为何IB才是终极解 既然RoCE能满足中小集群需求,为什么国内厂商还要冒险布局IB?答案很简单:RoCE的性能天花板是由其基于TCP/IP的底层架构决定的,即使投入再多研发资源,也无法在万卡级集群上追平IB的原生无损优势。 国产IB的布局,本质是跳过“跟随式优化”,直接切入技术本源,构建自主可控的高性能互联生态。IB协议本身是开放的,符合IBTA国际标准,且兼容英伟达的主流技术路线,这意味着国产IB产品无需推倒重来,只需在芯片、交换机等硬件层面实现自主研发,就能快速融入现有智算生态。
随着国内头部厂商纷纷布局国产IB,相信在不久的将来,我们就能看到自主研发的IB网络支撑起万亿参数模型的训练,补全中国AI计算产业链的关键一环。