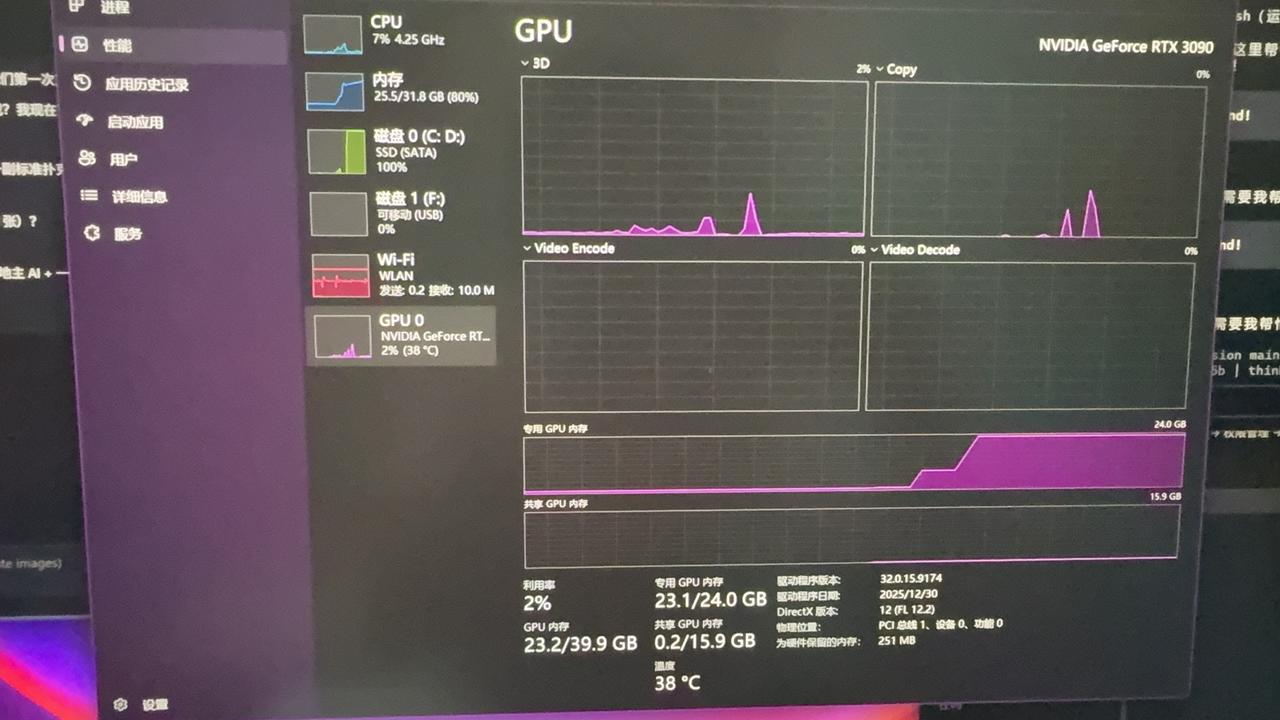
ollama和lm studio 作为openClaw的本地模型对比和感受: 1.我的另一台window电脑是win11运行内存32G,显卡RTX3090的24G显存,装了openclaw。 2.先试了ollama本地加载qwen3.5-27B、35B以及glm-4.7-flash,又试了lm studio来加载这三个本地模型,在本地随便跑的时候速度都很快,但是用openclaw加载这些本地模型后,明显速度慢了很多,甚至很慢,每次回答要等2-3分钟。后来去查了了一下,原来大家都一样,原因在于上下文的token太长,还有thinking 思考也需要时间,还有包括你加载了很多skills和其他文件。 3.要是显卡有限,比如我的3090,使用本地模型来跑openclaw,建议使用lm studio来加载,在lm studio里将可调节参数设置显卡和运行内存同时加载模型,将思考thinking关闭 这样能提升模型调用速度,可以将3分钟缩减到1分钟甚至更快的反应回答速度,所以当运行内存较大时也是一种优势。相反ollama是预设参数,不方便改参数,在windows 上是默认使用显卡的,导致运行内存闲置。 4.还想更快就加载14B或者9B的本地模型 5.当然硬件有限的情况,还是购买套餐吧,Token管饱