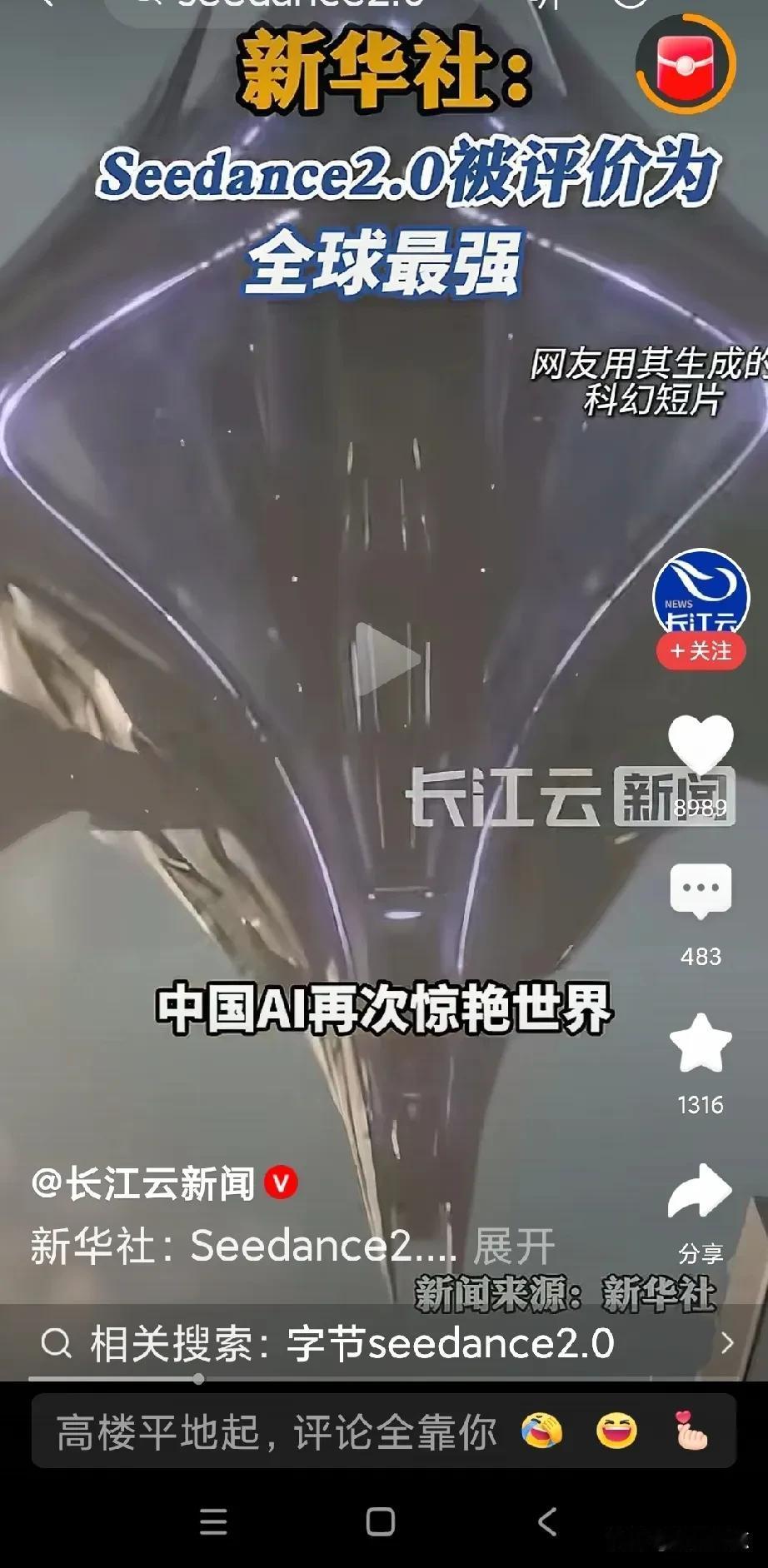
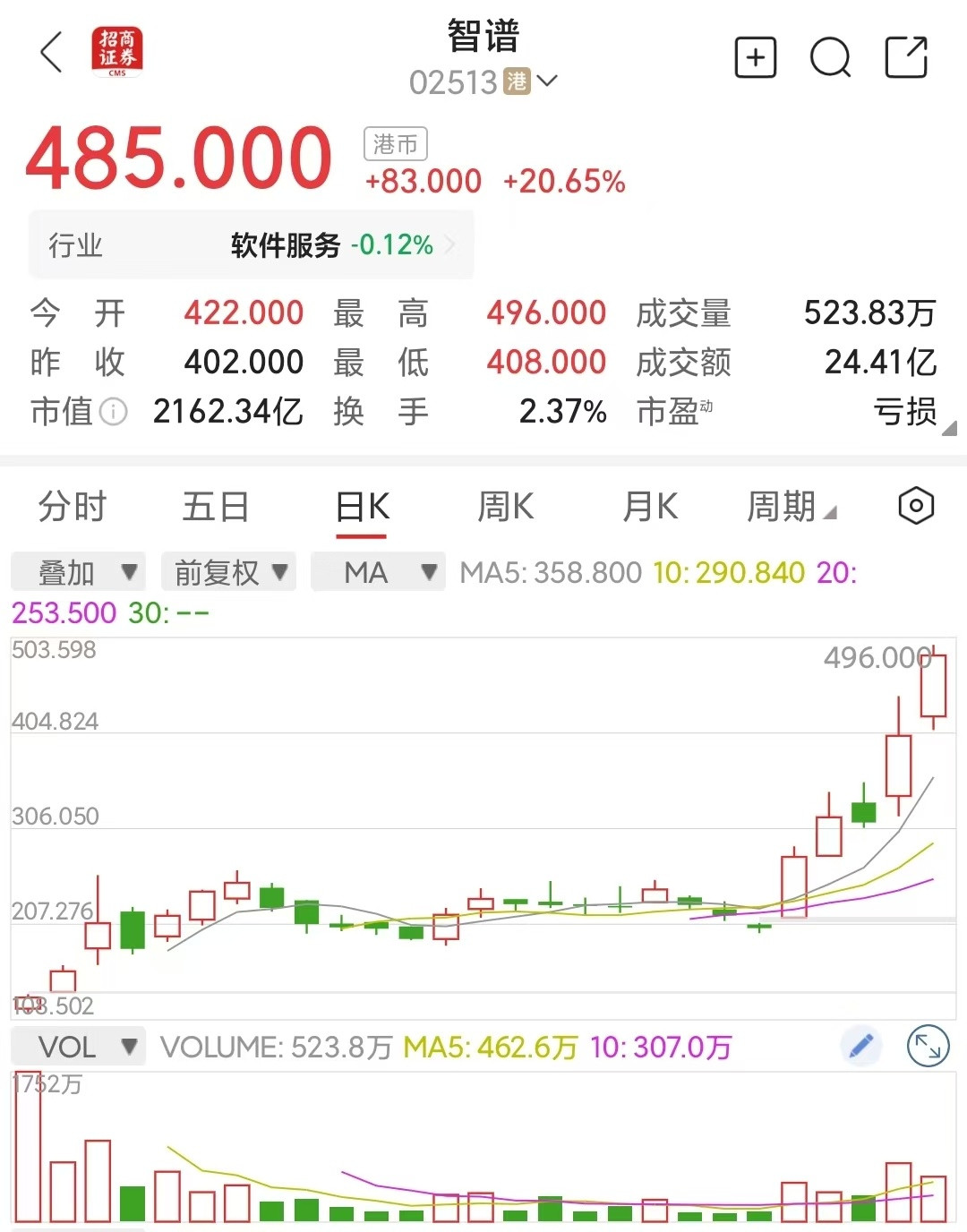
让美国各界又震惊的是我国的AI总算力资源不到美国的1/5,我国2025年的Deepseek,2026年的Seedance,2027又会蹦出来哪个?这下老美牛逼吹不下去了 要知道老美这些年一直在AI领域吹得天花乱坠,说自己垄断了全球算力,说其他国家再怎么追也赶不上,结果没想到,咱们用着不到他们五分之一的算力,却在大模型领域一路逆势突围,这事儿直接打了不少美国政客和科技巨头的脸。 可能很多人不清楚总算力意味着什么,简单说就是AI发展的“燃料”,算力越多,理论上能支撑的大模型训练、技术突破就越多。 老美这些年砸了海量的钱在算力基建上,高盛的数据显示,2025到2027年,他们几家科技巨头在AI基础设施上的投入就预计高达1.4万亿美元,光英伟达一家的股价就涨了十几倍,市值一度超过德国全年的GDP,说他们把AI泡沫吹到天上都不为过。可即便这样,他们也没料到,咱们能用这么少的“燃料”,跑出这么快的速度。 最让美国措手不及的,就是咱们国内不断冒出来的优质大模型。2025年的时候,Deepseek横空出世,可能有人对这个模型不太熟悉,但它的实力是真的能打,作为幻方量化孵化的AI先锋,它不光在中文理解上远超很多国际同类产品,还靠着独特的技术架构,把训练成本降到了传统模型的十分之一,甚至能适配十几种国产芯片,在政务、金融领域都落地得风生水起,当时就让不少美国科技圈的人直呼不可思议。 没人能想到,在算力有限的情况下,咱们能做出性价比这么高、实用性这么强的大模型,更没人想到,这仅仅是个开始。 就在美国还在琢磨怎么应对Deepseek带来的冲击时,2026年,Seedance又悄然崛起,进一步打破了他们的认知。要知道老美一直觉得,咱们的大模型只能在中文场景发力,在多模态、复杂推理这些高端领域根本不是他们的对手,可Seedance的出现,直接打破了这个偏见。 更值得一提的是,咱们的大模型发展,走的是和美国完全不同的路子,他们靠砸钱堆算力、堆参数,搞封闭生态,而咱们则是走开源路线,把技术开放给更多开发者,同时深耕工业、政务这些实际应用场景,用场景反馈来优化模型。 这也让咱们的大模型迭代速度越来越快,实用性也越来越强。很多人不知道的是,咱们2026年AI大模型的Tokens消耗量,同比增长已经超过了10倍,增速甚至略快于全球平均水平。 现在美国各界最慌的,其实不是当下的差距,而是看不到咱们的上限,更猜不到2027年咱们还会蹦出来哪个厉害的大模型。要知道老美的AI发展,现在已经陷入了一个尴尬的境地,他们的投资规模越来越大,但回报却迟迟跟不上,OpenAI上半年收入四十多亿美元,净亏损却高达一百多亿美元,很多AI企业烧了大量的钱,最终却因为技术突破不及预期而破产。 更关键的是,他们的资金循环模式暗藏风险,英伟达投资OpenAI,OpenAI再向甲骨文购买算力,甲骨文又回头买英伟达的芯片,这种“左脚踩右脚”的操作,一旦某个环节出问题,整个链条都可能崩塌。 反观咱们,虽然总算力不如美国,但咱们的优势越来越明显,国家AI大基金持续发力,国产芯片也在不断突破,电力资源更是充足,能为算力中心提供稳定保障,更重要的是,咱们的大模型接地气,能真正落地到各行各业,创造实际价值,而不是像美国那样,只停留在资本炒作和参数比拼上。 老美这些年吹的“AI遥遥领先”,现在看来更像是自欺欺人,他们的泡沫越吹越大,而咱们则在一步步稳扎稳打,用实力打破他们的垄断神话。或许有人会说,咱们的高端芯片还有短板,但谁也不能否认,咱们的进步速度,已经超出了所有人的预期。 如今,越来越多的美国机构开始减持AI概念股,华尔街关于AI泡沫破裂的警告声也越来越响,曾经不可一世的英伟达,也开始面临估值过高的质疑。 而咱们,在2025年有Deepseek、2026年有Seedance之后,2027年又会带来怎样的惊喜?会不会有新的大模型横空出世,进一步缩小和美国的差距,甚至实现反超? 老美的AI泡沫,到底会在什么时候彻底破裂?欢迎大家在评论区留下自己的观点,一起聊聊中美AI的发展格局,说说你心中2027年最值得期待的中国AI大模型会是谁。