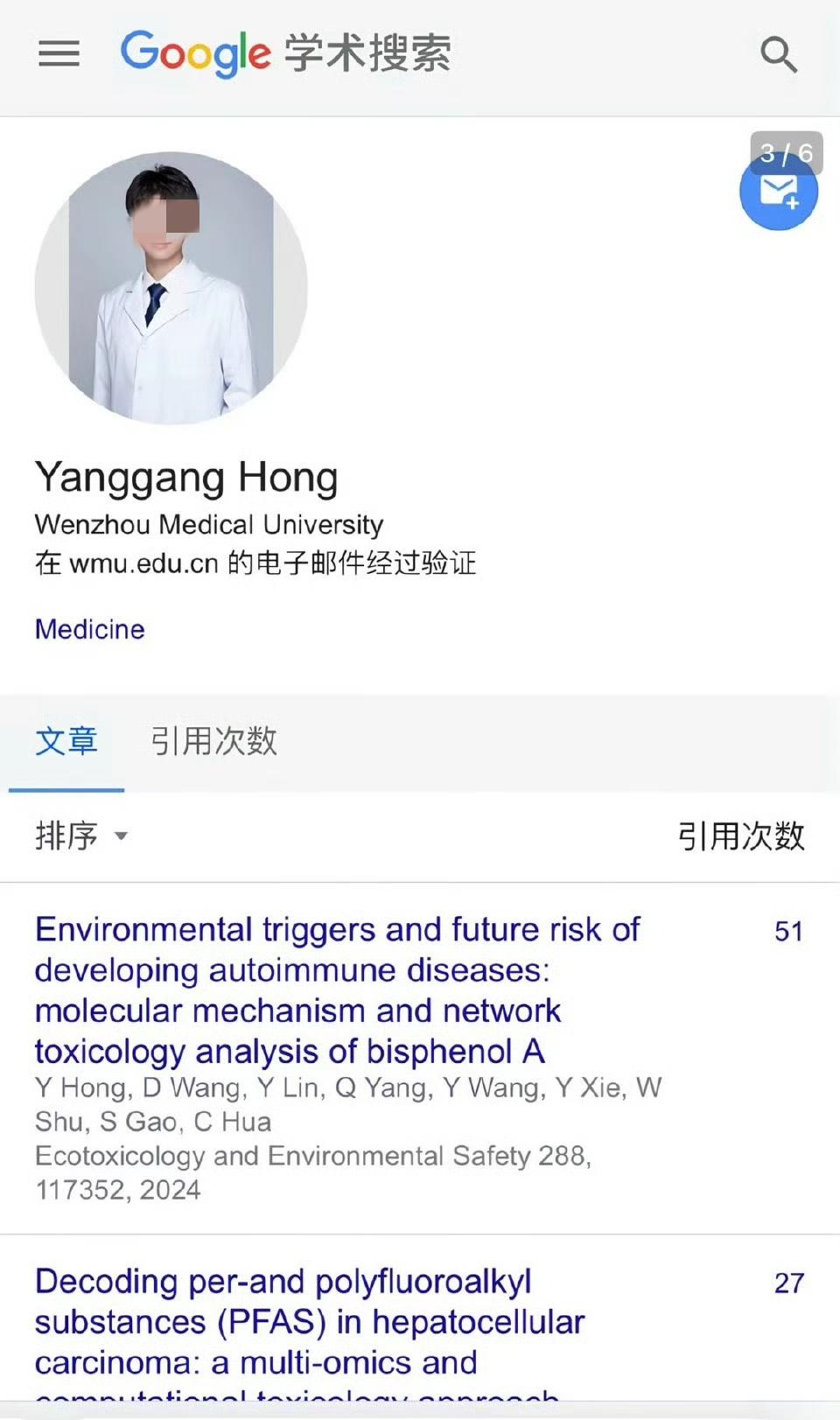
医学生“神迹”背后:当科研沦为数据库“排列组合”的游戏 打开一份公开的学术资料库,记录清晰地显示,温州医科大学一名大四本科生在短短一年内发表了40多篇学术论文。这个远超绝大多数教授和博士生的速度,像一把利剑刺向学术圈的心脏。 舆论开始剧烈发酵。学校内部人员谨慎回应“正在处理”,而行业内的观察者则感到一阵寒意——因为这很可能不是天才的诞生,而是学术“论文工厂”模式,已从暗处蔓延至本科生的日常学习之中。 这些论文采用的孟德尔随机化分析、生物信息学筛选等“时髦”方法,在真正的科研人眼中,其核心操作却是简单的数据排列组合。 01 数据流水线:公共数据库成论文“原料库” 梳理这位学生的论文发现,其研究领域横跨肿瘤、免疫、神经系统疾病等多个方向。看似涉猎广泛,实则方法高度雷同,核心是运用公共数据库与固定分析工具。 以他多次研究的“PFAS(全氟化合物)与癌症关系”为例,论文就像一套模板更换参数:先研究PFAS与肝癌,换成乳腺癌数据,又是一篇新作。 这种模式极度依赖如美国国家健康与营养检查调查(NHANES)这类公开的大型健康数据库。变量极多,研究者可通过穷举、筛选统计上显著的相关性,再为这个“偶然发现”反推一个科学假设。 这种“先有结果,再编问题”的倒置研究,违背了科学探索的基本逻辑。 02 高效率之谜:AI工具与学术“外包”的助推 为何一年能产出40多篇?除了方法模板化,技术进步与灰色产业链提供了“效率”保障。一项调查显示,利用大语言模型,从数据到生成一篇能通过初步查重检测的论文初稿,可能仅需两小时。 更隐秘的推动力来自明码标价的学术服务。在国内社交平台上,不难找到提供“数据挖掘”论文定制服务的广告。甚至有推广文章将这位学生的论文作为成功案例,直言“抓住一个目标,换个疾病就能复制粘贴出多篇文章”,目标客户就是“急需文章”的人群。 03 学术激励与功利主义的双刃剑 一名本科生为何需要如此多的论文?背后是环环相扣的激励体系。温州医科大学设有专项创新创业资金,学生作为第一作者发表SCI论文,可获得数千元奖励。 对于面临升学、评奖、保研压力的医学生,论文是硬通货。当“发表”本身成为目标,而高质量的原创性实验研究周期长、失败率高时,利用公共数据快速“灌水”便成了一条高风险但高回报的捷径。 04 泛滥与反制:“论文工厂”已冲击国际期刊 这种“快速生产的科学”已在全球泛滥,并引起了国际学术出版界的警惕。知名出版集团Frontiers指出,这类低质量、重复性的研究正让期刊系统不堪重负。 基于NHANES数据库的“垃圾论文”在2021-2024年间暴增,其中超过92%的第一作者来自中国机构。 作为反制,Frontiers等出版商已出台严厉新规:仅基于公共数据库、缺乏独立数据验证的孟德尔随机化研究,将在初审阶段直接拒稿。政策实施后,相关投稿量骤降。 05 并非孤例:本科生“逆天履历”频现与反思 近年来,类似引发争议的本科生“学术明星”并非个例。2025年7月,川北医学院一名学生因简历中声称以第一作者在顶级期刊发表多篇论文而受到关注。学校核查后发现,其成果表述存在不严谨和自夸之嫌,并对其进行了批评教育。 这些事件共同反映出在学术评价体系下,部分学生可能存在的浮躁心态和对科研成果的过度包装。 值得对比的是,一些高校通过跨学科团队、导师精心指导和真实实验,也能培养出产出高质量成果的本科生团队。例如沈阳医学院、广东医科大学的本科生,能在扎实实验基础上于权威期刊发表论文。这证明,鼓励科研与坚守质量并非不可兼得。 深夜的实验室里,仍有学生在为一次失败的实验数据反复核对。而在网络的另一端,一篇基于数据库“挖掘”出的新论文可能正在被快速生成。 学术出版商的拦截措施是一道外部防火墙,但更根本的,需要从学术评价的指挥棒上进行反思。当数量不再是唯一标准,当扎实的实验与漫长的探索重新获得应有的尊重,“一周一篇”的学术神话才会失去滋生的土壤。 真正的科学发现,永远无法从数据的排列组合中自动涌现。它源于对未知的好奇、对假设的耐心验证,以及在无数次失败后依然闪烁的求真之光。医疗数据科学 医学科研 科研新模式 混的医学生 医学数据乱象 科研数据集 智能医学科研