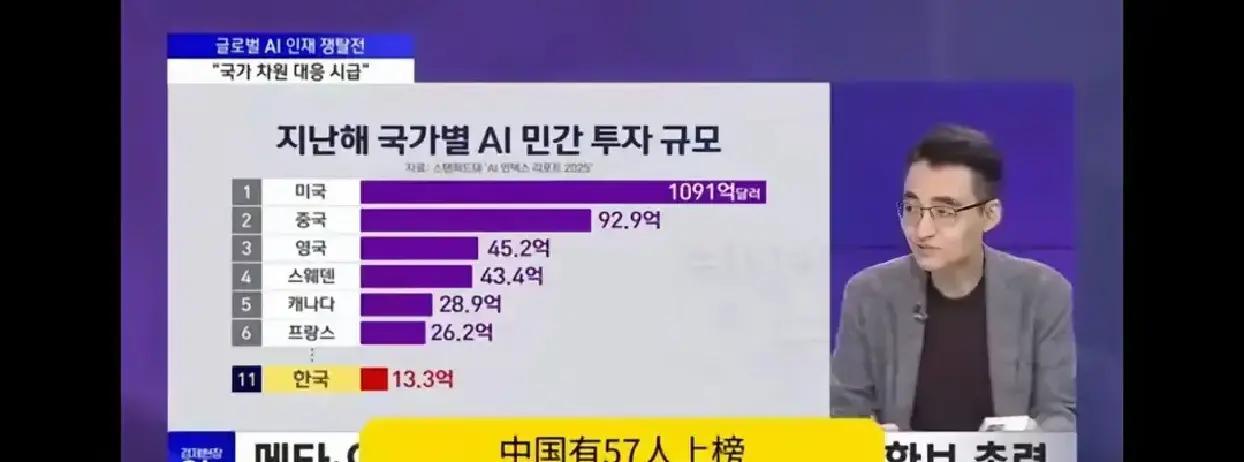
【在 ChatGPT 最初引发冲击三年后,中国缩小了与美国的 AI 差距】(南华早报)三年前的11月30日,美国初创公司OpenAI推出ChatGPT ,这让中国科技行业争相跟上人工智能最新发展的步伐。据知情人士透露,中国政府当局已向包括清华大学教授在内的各界专家发出紧急请求,要求他们就生成式人工智能技术的影响进行简报。中国大型科技公司和雄心勃勃的初创企业竞相推出自己的人工智能聊天机器人和大型语言模型(LLM),并向政府注册,以此阻止美国人工智能服务进入中国超过10亿的互联网用户。在 ChatGPT 发布后的最初几个月里,人们认为对人工智能服务采取封闭式管理是中国最好的策略,直到国内科技公司能够开发出可以与西方人工智能提供商的产品有效竞争的产品为止。即使在 ChatGPT 推出一年多之后,风险投资家朱晓虎仍然表示,他对投资中国开发 LLM(ChatGPT 等生成式人工智能服务背后的技术)的初创公司没有兴趣,因为它们既没有明确的盈利途径,也没有数据来支撑这种业务的蓬勃发展。朱先生因早期投资网约车巨头滴滴出行而闻名,他反问道:“仅仅开发一个法学硕士项目,如何才能赚钱呢?”快进到 2025 年下半年,人们对中国人工智能公司和 LLM 业务的技术能力的预期发生了变化。根据第三方人工智能模型聚合商 OpenRouter 和风险投资公司Andreessen Horowitz最近发布的一份报告,中国的开源人工智能模型占全球该技术总使用量的近 30%。该报告将今年全球开放式LLM使用量的激增归因于中国自主研发系统的日益普及,其中包括阿里云的Qwen系列模型、DeepSeek的V3以及Moonshot AI的Kimi K2 。阿里云是阿里巴巴集团控股有限公司(《南华早报》的母公司)旗下的人工智能和云计算服务部门。这表明中国的开源模式正在赢得全球开发者的信任。像Airbnb这样的美国企业,甚至包括美国科技巨头Meta Platforms,现在都在使用 Qwen。中国人工智能行业的转折点出现在杭州的DeepSeek分别于2024年12月和1月发布了其V3和R1模型,这些模型当时与OpenAI的GPT和Meta的Llama模型不相上下,尽管它们的开发成本仅为这些美国公司的一小部分。百度联合创始人兼CEO李彦宏在2月份表示:“我们从DeepSeek项目中学到的一点是,开源最佳模型可以极大地促进技术普及。”这与他之前认为开源模型不如专有模型的言论截然相反。据里昂证券中国科技研究主管张东尼 (Tony Zhang) 9 月份表示,由于人工智能人才的涌入、技术的快速迭代以及中国大陆人工智能应用的蓬勃发展,中美人工智能差距已从一年多缩小到大约三个月。张先生表示,虽然由于地缘政治问题,中国企业在人工智能项目方面面临先进处理器短缺的问题,但这一限制并未阻碍该技术的发展。这种韧性也体现了中国云服务提供商的远见卓识,他们成功积累了足够多的用于训练的AI芯片。他还补充说,中国国内越来越多的芯片设计公司也在开发用于训练和推理任务的AI处理器。与此同时,华为技术有限公司创始人兼首席执行官任正非表示,美国和中国在人工智能发展方面走的是“不同的方向”。任志强表示,当美国专注于超级计算能力和大型模型,追求通用人工智能和超级人工智能的宏伟目标时,中国则采取了更为务实的做法,利用人工智能解决现实世界的问题。在 ChatGPT 出现之前,自 2017 年北京将人工智能技术列为国家优先事项以来,中国一直将自己视为人工智能领域的领跑者。该计划概述了中国到 2030 年成为人工智能超级大国的路线图。其驱动力源于当时的普遍观点,即中国庞大的数据宝库(被描述为人工智能的化石燃料)将有助于推动经济和产业转型。这一点在“人工智能龙”的崛起中得到了早期验证,其中包括商汤科技、旷视科技、依图科技和云步科技。它们开发了世界领先的计算机视觉技术,为面部识别系统提供了动力。但 ChatGPT 引发的狂热使得这些公司的能力在生成式人工智能时代过时了。ChatGPT 在短短两个月内迅速发展成为用户量约 1 亿的快速增长的消费级 AI 应用,这让中国科技行业陷入了反思的漩涡,他们反思自己是如何错失这一突破的,以及中国在人工智能领域如今落后了多少。当时黯淡的前景甚至促使网络安全公司360安全技术创始人、与中国政府关系密切的行业资深人士周鸿毅在2023年的中国发展论坛上告诉听众,中国在开发类似ChatGPT的技术方面比美国落后两到三年。2024年,中国大陆媒体盛赞中国新一代“人工智能四小龙”的崛起,这重新燃起了人们的乐观情绪。这些“人工智能四小龙”包括登月科技、百川科技、MiniMax科技和智普科技,它们都获得了来自各方投资者的巨额资金。DeepSeek 和阿里云的 Qwen 的开源开发方式鼓励了中国人工智能初创企业追求进一步创新,尽管它们无法获得来自美国领先供应商英伟达和AMD 的先进图形处理单元。“开源是挑战者的工具,”中国人工智能专家、乔治·华盛顿大学政治学助理教授丁杰表示,“如果你看看谷歌为什么决定开源其安卓操作系统,就会发现那是因为当时苹果的操作系统占据主导地位。”封闭式人工智能系统就像专有软件,其提供商控制访问权限,决定提供哪些功能,并阻止对底层源代码或模型权重(即编码其“智能”的变量)的检查或修改。开放模型开发者则公开发布其权重,通常还会附带概述其训练过程的技术论文,允许用户根据自身需求部署和微调这些权重。然而,DeepSeek的成功并未保证其他AI创业公司也能一帆风顺。百川和01.AI等公司退出了AI模型市场,因为它们不愿再向用户收取费用来使用其质量低劣的产品。在 Moonshot AI 于 7 月发布 Kimi K2 模型之前,其他 AI 巨头几乎没有发布任何令人振奋的消息。随后,国际知名的智普人工智能(Z.ai)发布了 GLM-4.5 模型,其强大的编码能力给程序员们留下了深刻的印象。10 月,Z.ai发布了新的旗舰模型GLM-4.6,编码能力更加强大。“从DeepSeek R1发布到GLM 4.5发布,我们等了这么久,”智普人工智能全球运营负责人李子轩表示,“我们被低估了,尤其是在中国,而在美国则完全被忽视了。”MiniMax 于 6 月推出了 M1 型号,转向开源模式,随后在 10 月推出了 M2 型号,这使得该公司作为一家前沿的开源模式公司,在国际上备受瞩目。据旧金山风险投资公司 Creative Ventures 的普通合伙人 James Wang 称,Moonshot AI 和 MiniMax 的新模型帮助他们重回董事会,而他们从未完全离开过董事会。王先生预计,DeepSeek 的下一代旗舰模型发布后,将继续保持中国领先的人工智能初创公司的地位。他表示,开源模型的发布热潮表明,“中国生态系统现在有了自己的竞争格局,模型公司竞相争夺主导地位”。其他相关行业的公司也开始寻求创建自己的开源模式。其中包括社交媒体平台RedNote、外卖巨头美团以及智能手机和电动汽车制造商小米。据中国开源人工智能专家 Nathan Lambert 和 Florian Brand 称,阿里云的 Qwen 系列模型战略比其他任何中国人工智能实验室都更接近美国大型科技公司的模式。该公司发布了众多不同规模的开源模型,涵盖了从视觉和编码模型到图像和视频生成模型的整个技术栈。人工智能研究员兼作家 Sebastian Raschka 表示,阿里云的Qwen3系列模型和 DeepSeek 的 R1 是今年最值得关注的开源模型发布,因为它们性能强大,而且具有多种尺寸,非常实用。过去三年,中国人工智能公司取得了长足进步,这似乎表明 OpenAI 和Anthropic都曾公开谴责从 DeepSeek 到智普人工智能等中国人工智能公司存在所谓的安全风险。美国总统唐纳德·特朗普的政府在 6 月份宣布了一项人工智能行动计划,该计划强调在全球范围内推广美国的人工智能技术,部分原因是应对人们认为中国在开源领域占据主导地位的情况。因此,硅谷和华盛顿现在提出的问题与三年前在中国讨论的问题相同:我们是否正在输掉人工智能竞赛?华为的任正非上个月在上海的一次活动上表示,“中国人工智能工程师不再羡慕国外的同行”。但他同时指出,中国在吸引全球人才方面仍然落后于美国,这需要中国大陆更加开放。在特朗普决定批准英伟达向中国出口 H200 芯片之后,美国长期以来对先进半导体出口的限制也开始放松。风险投资家朱在本周的一个播客节目中表示,中国现在有望在十年内超越美国,成为人工智能领域的领头羊,这主要是因为中国大陆更快地建设了电网和数据中心基础设施。朱表示:“人工智能竞争实际上是数据中心和电力供应的竞争,而中国在这方面具有显著优势。”