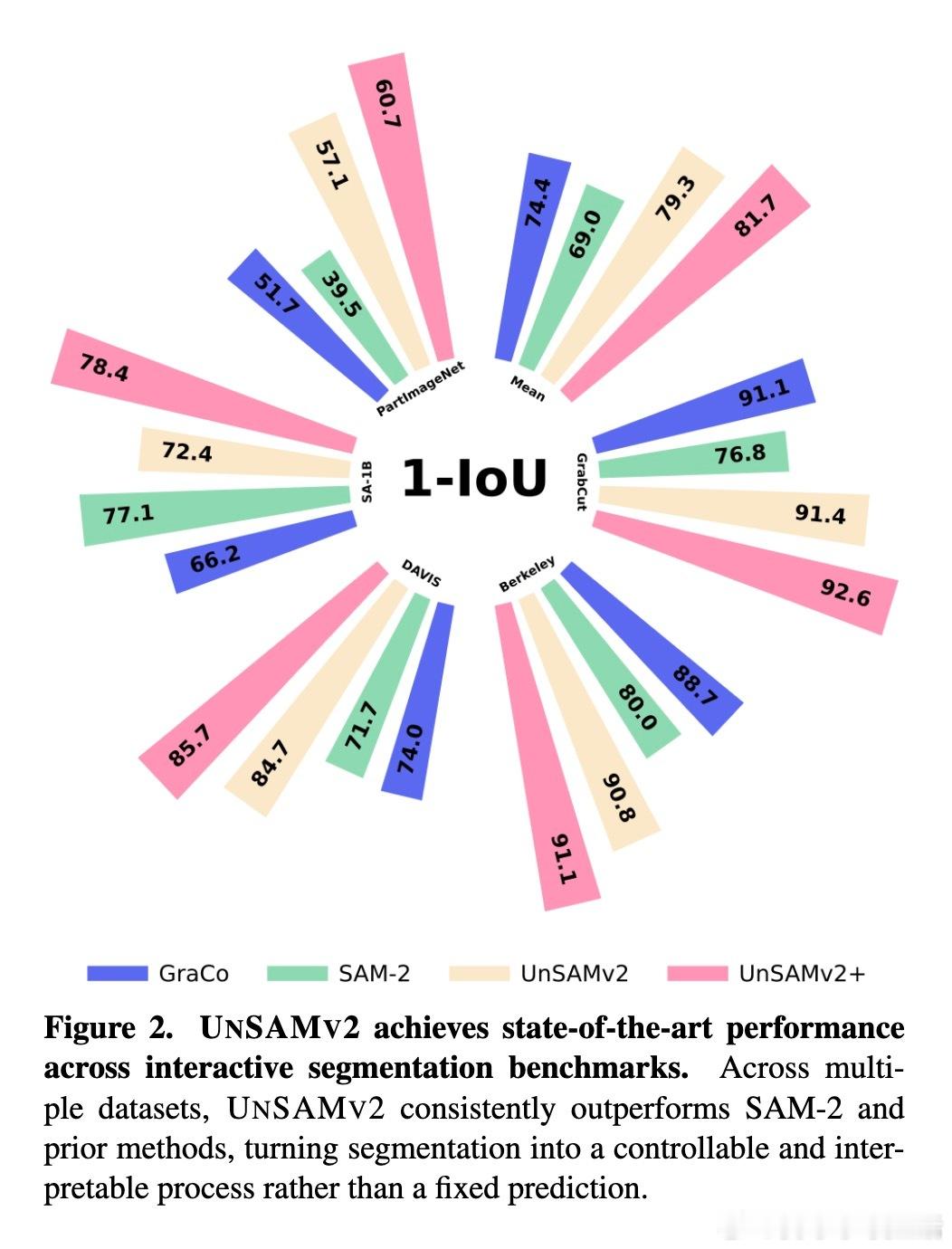
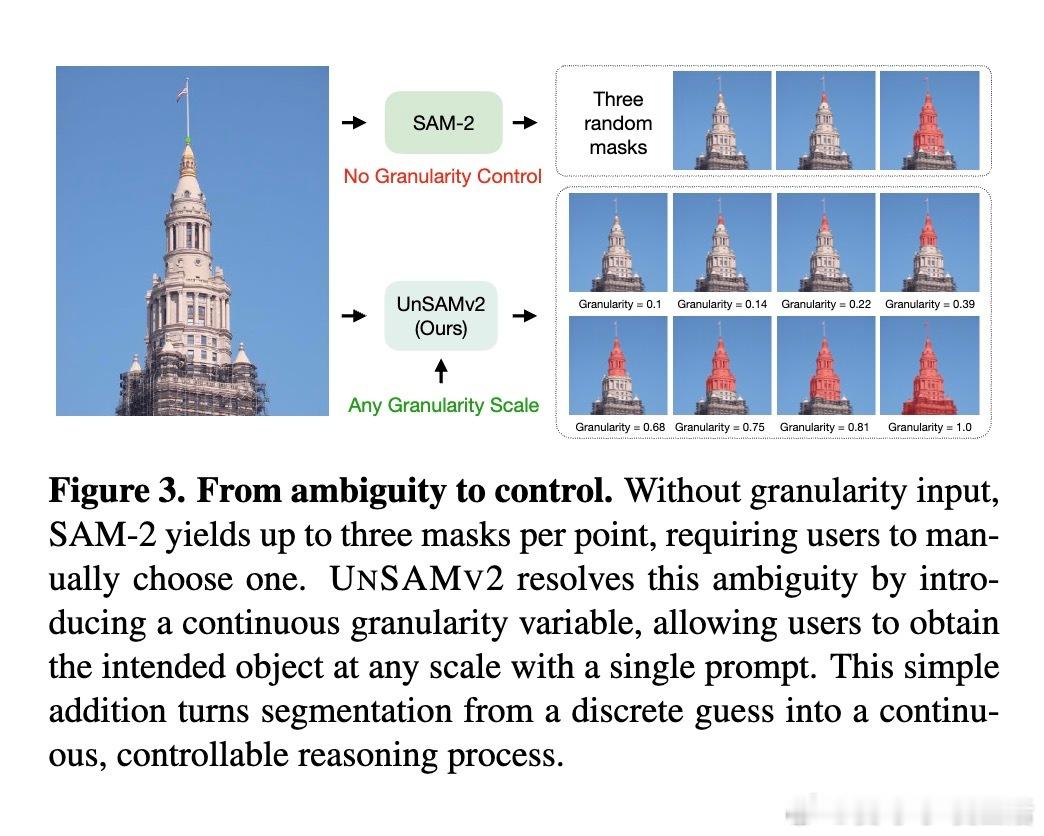
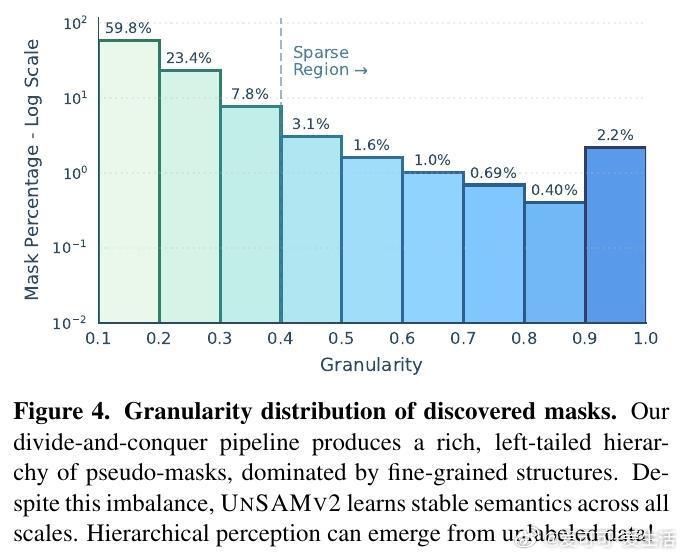
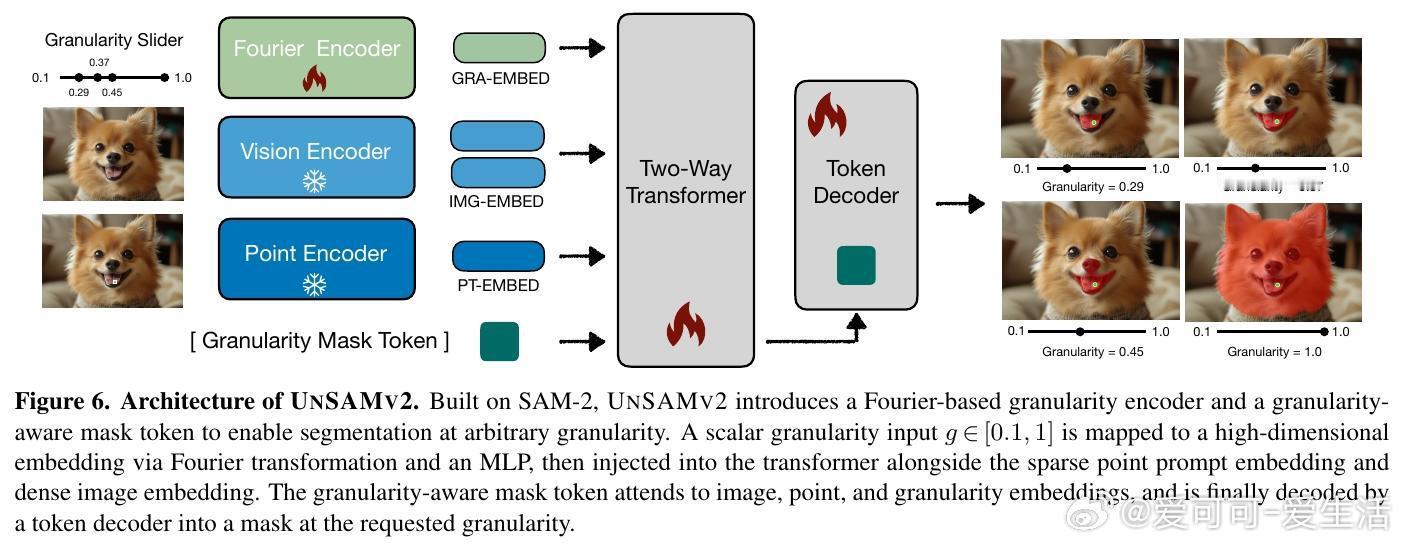
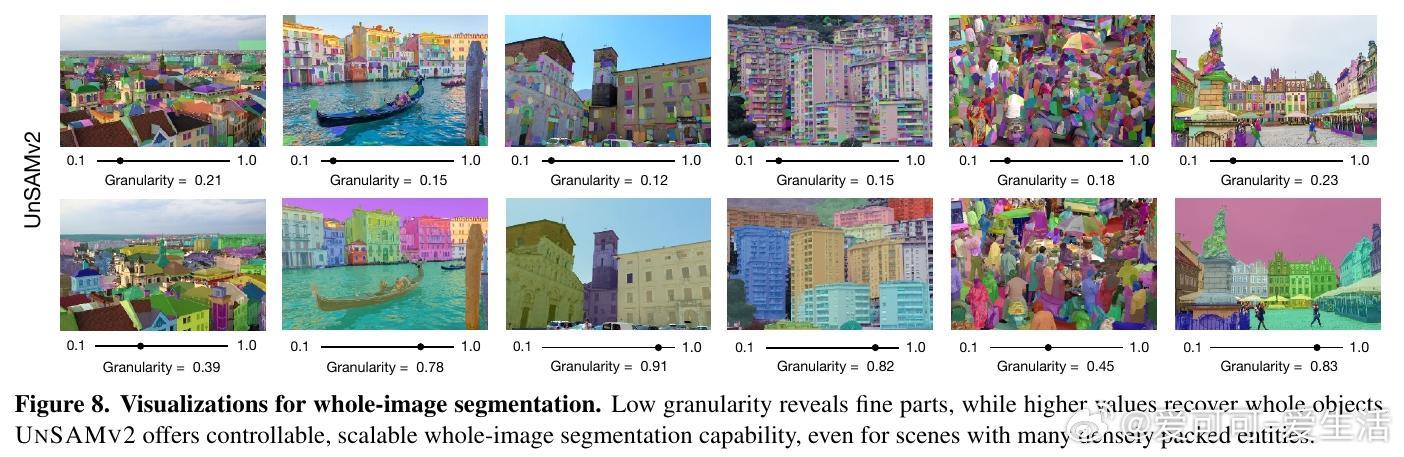
[CV]《UnSAMv2: Self-Supervised Learning Enables Segment Anything at Any Granularity》J Yu, T Darrell, X Wang [UC Berkeley] (2025) UnSAMv2:自监督学习实现任意粒度的“Segment Anything”“什么是物体?”这个问题在视觉认知领域长期争论不休。传统的Segment Anything Model(SAM)系列虽已广受欢迎,但其分割粒度控制能力有限,用户常需通过额外提示或从固定的几个预生成掩码中选择,既繁琐又模糊。为此,UnSAMv2提出了一种自监督学习框架,能在无需人工标注的情况下,实现从细粒度部分到整体物体的任意连续粒度分割。其核心创新包括:1. 粒度感知的分而治之策略:利用无监督方法(如MaskCut的归一化割)发现实例掩码,并递归合并细粒度部分,形成层次化伪标签,赋予每个掩码一个连续的粒度标量,反映其在部分-整体层级中的相对尺度。2. 粒度编码与解码架构:在基于SAM-2的基础上,设计了傅里叶特征映射的粒度编码模块和一个粒度感知的掩码Token,使模型能根据单点提示和连续粒度输入,预测对应粒度的掩码,实现分割的连续可控。3. 高效且轻量的训练:仅用6,000张无标签图像,训练4小时(2个A100 GPU),微调解码器部分参数(0.02%增量),即可显著提升SAM-2性能。4. 广泛验证与领先表现:在超过11个基准测试(包括交互式分割、整体图像分割和视频分割)中,UnSAMv2均超越SAM-2和之前的先进方法。关键指标NoC90从5.69降至4.75,1-IoU从58.0%提升至73.1%,AR1000从49.6升至68.3,充分证明了自监督的粒度学习潜力。5. 深入启示:传统监督训练强加的人为物体定义限制了模型对视觉层次结构的理解。UnSAMv2通过无监督学习从图像统计中发现层级关系,将分割从离散预测转变为连续、可解释的推理过程,为视觉基础模型注入了新的灵活性和表达能力。6. 实用价值:用户只需单点点击并调节粒度滑块,即可快速得到所需层级的掩码,极大提升了交互效率和分割灵活性,适应多种下游任务如部件分析、实例聚合或大规模区域编辑。总结来说,UnSAMv2突破了现有分割模型受限于固定粒度和人工标注的瓶颈,展现了自监督学习在视觉分割层次理解上的巨大潜力,推动了“Segment Anything”向任意粒度、连续可控方向迈进。项目主页:yujunwei04.github.io/UnSAMv2-Project-Page/ 论文链接:arxiv.org/abs/2511.13714