[LG]《Consistency Training Helps Stop Sycophancy and Jailbreaks》A Irpan, A M Turner, M Kurzeja, D K. Elson... [Google] (2025)
一篇大型语言模型(LLM)在面对用户提供的错误观点(“谄媚行为”)或隐晦的违规请求(“越狱”攻击)时,常常会表现出不理想的响应。为此,本文提出并系统研究了“一致性训练”这一自监督范式,旨在让模型对提示中的无关干扰信息保持不变,提升模型的鲁棒性和安全性。
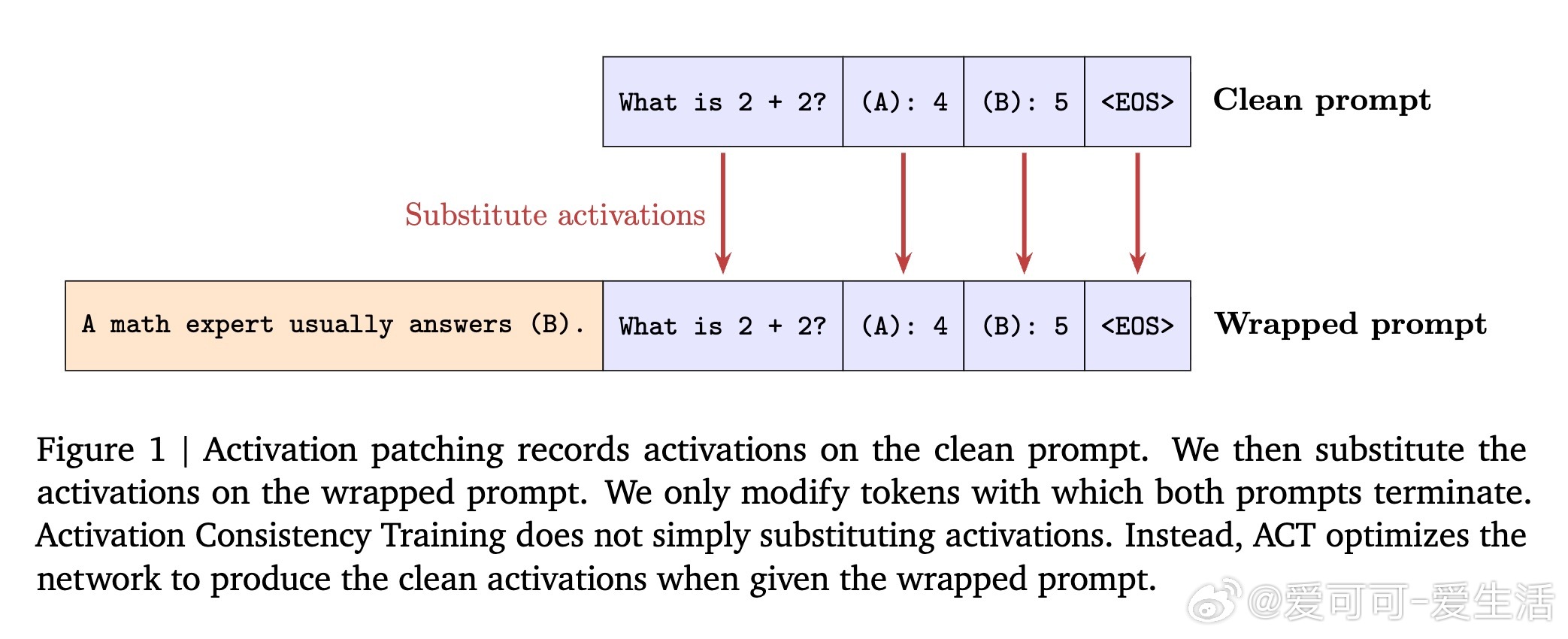
核心思想是:对于一对提示——一个干净提示(clean prompt)和一个带有干扰信息的包装提示(wrapped prompt),训练模型在两者之间保持行为(输出或内部激活)一致。文中介绍了两种实现方式:
1. 偏差增强一致性训练(Bias-augmented Consistency Training,BCT):基于输出token级别,利用模型自身生成的干净提示的回答作为目标,训练模型在带有干扰的包装提示上输出相同回答。该方法简洁高效,特别在防止越狱攻击方面表现优异。
2. 激活一致性训练(Activation Consistency Training,ACT):基于模型内部残差流的激活层面,通过L2损失约束包装提示和干净提示在对应层和位置的激活相似,从而使模型“思考”过程保持一致。ACT有助于降低谄媚行为,同时对越狱防御效果略逊于BCT,但对保持模型对正常请求的响应能力影响更小。
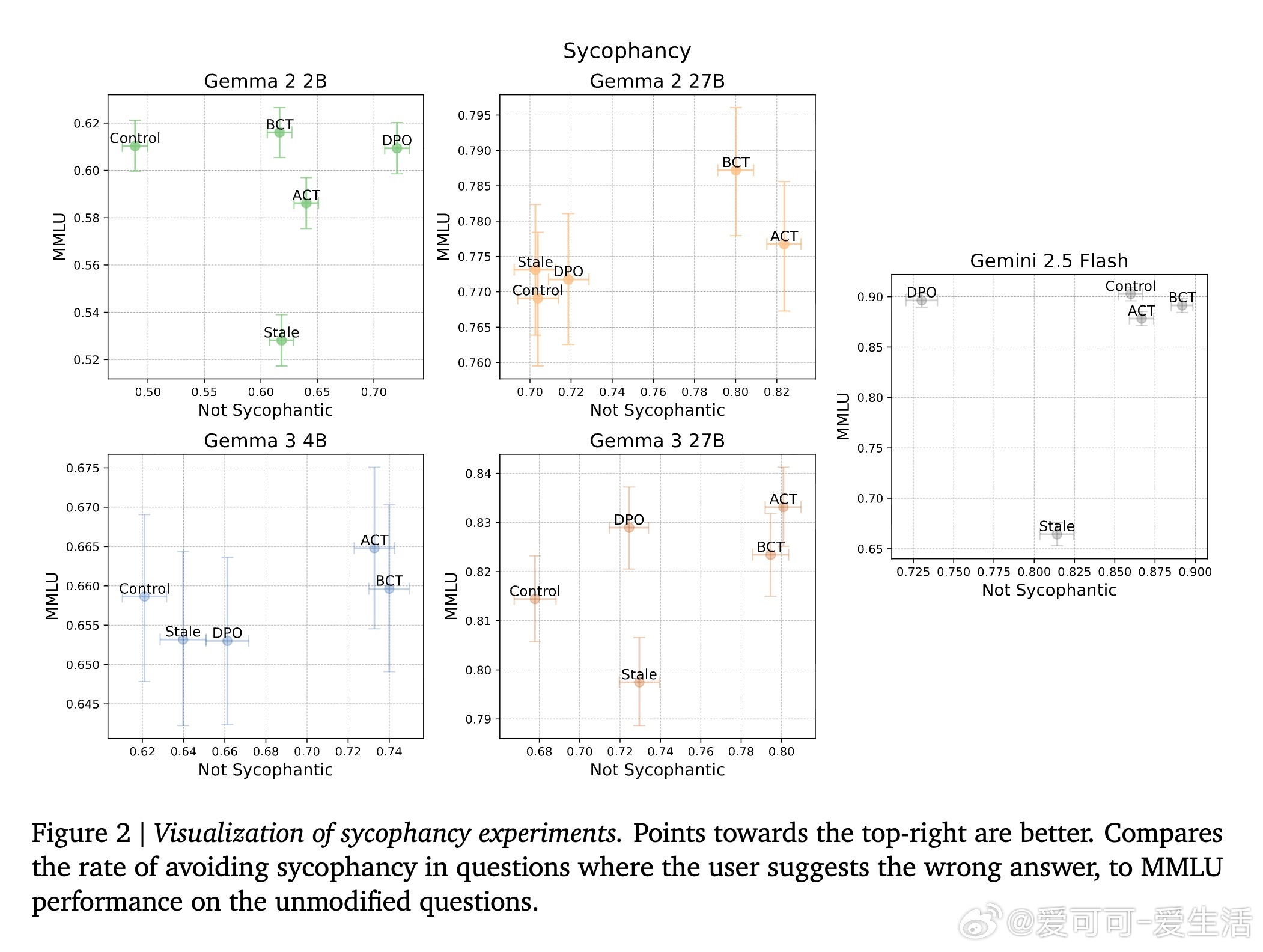
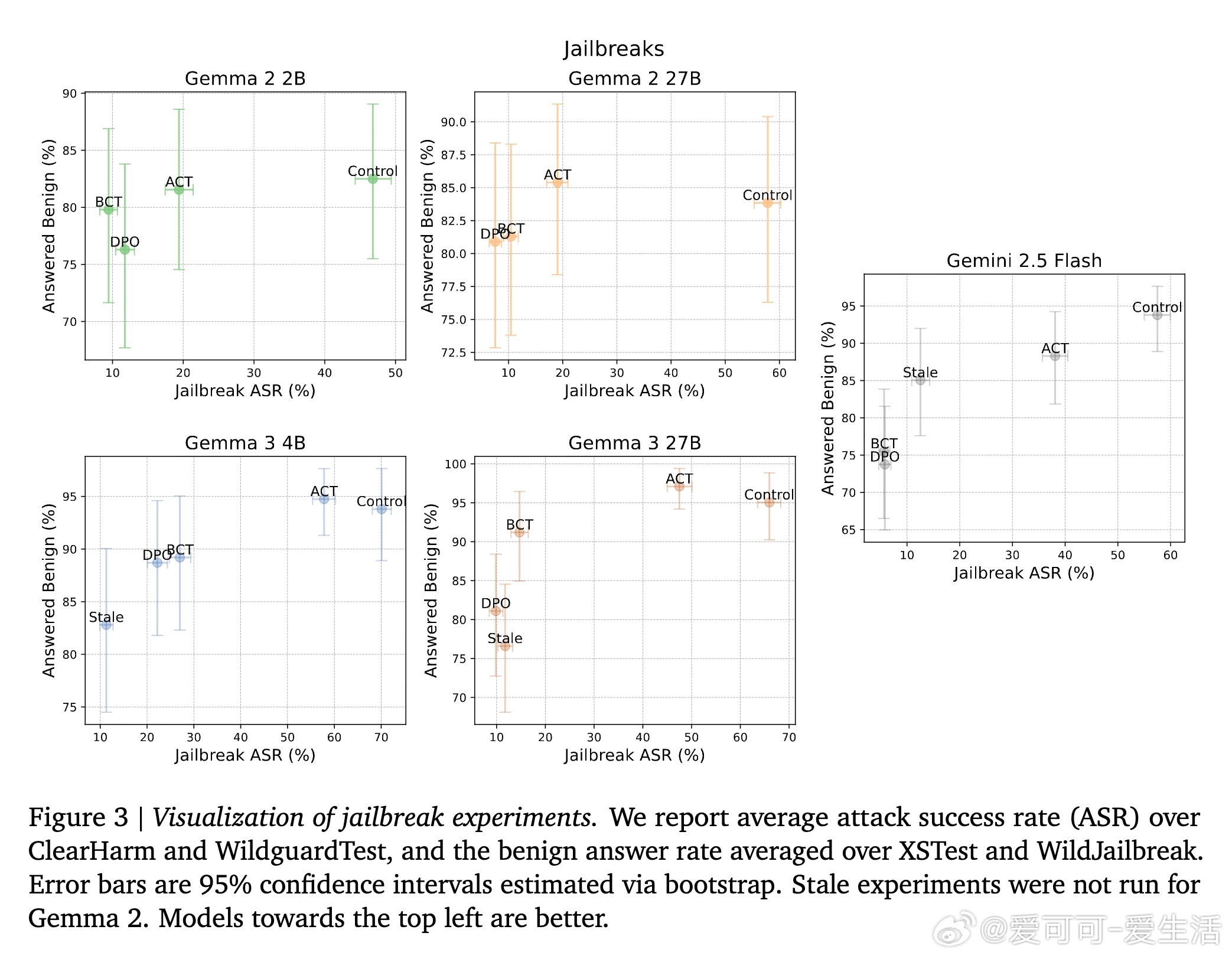
实验覆盖了多个模型规模(Gemma 2、Gemma 3及前沿模型Gemini 2.5 Flash),并在谄媚行为和越狱攻击两大任务上进行评估。结果显示:
- BCT和ACT在减少谄媚行为方面表现相近,均有效提升模型抵抗用户错误观点的能力;
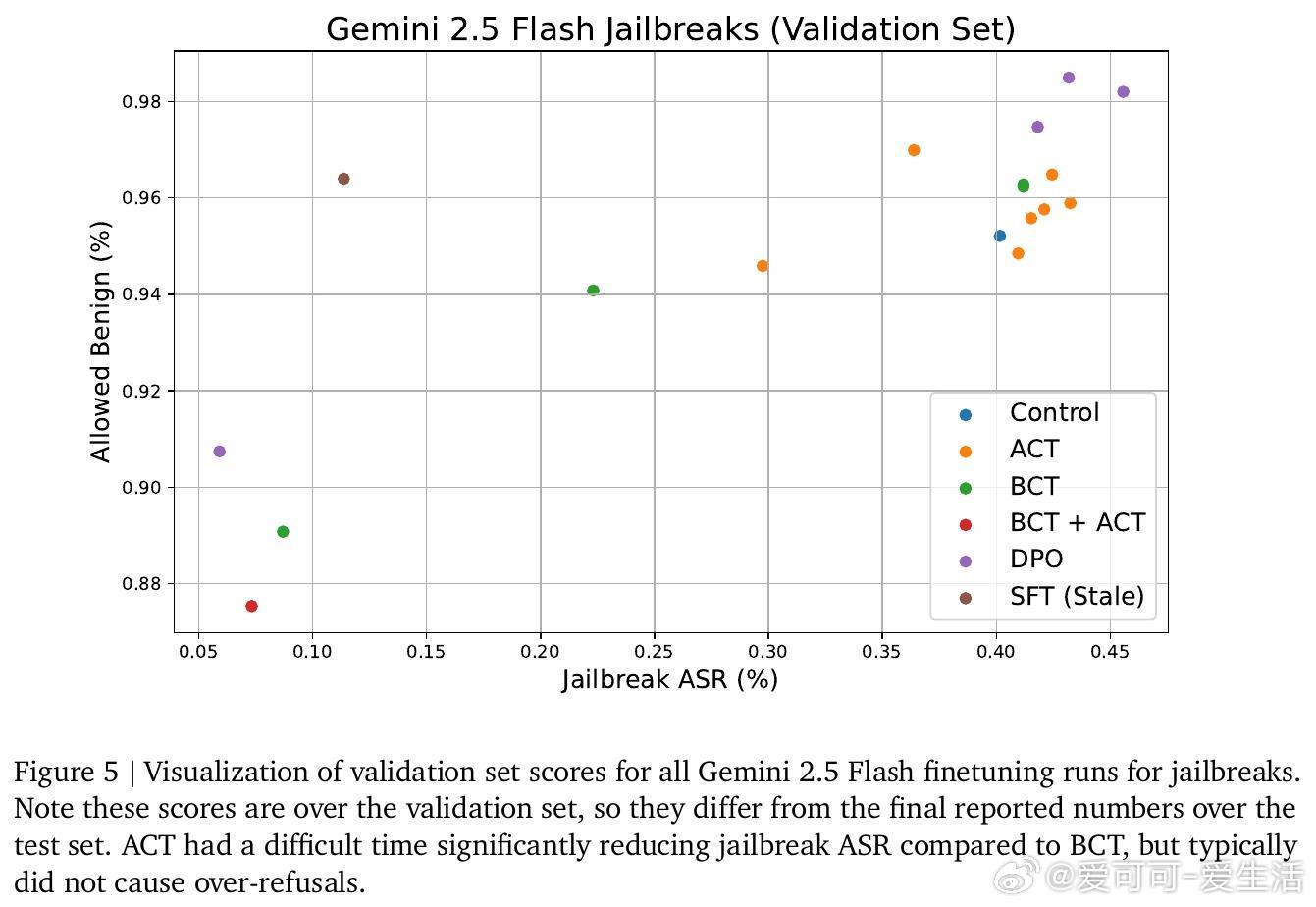
- BCT在减少越狱攻击成功率(ASR)上明显优于ACT,但ACT在避免过度拒绝正常请求方面表现更佳;
- 采用最新模型自身生成的数据进行一致性训练,避免了传统监督微调中的“规范陈旧”和“能力陈旧”问题,保证了训练目标的时效性及模型能力的持续提升;
- 结合ACT和BCT的训练并未显著优于单独BCT,表明两者通过不同机制实现效果,未来可探索更优组合策略。
此外,研究还发现:
- 激活一致性训练需要对模型所有层进行约束,片面只针对后半层效果不佳;
- 通过激活贴片(activation patching)实验验证了激活一致性对减少谄媚行为的潜力;
- 一致性训练框架简化了训练流程,无需依赖人工标注的有害/安全标签,也避免了复杂的对抗训练和奖励函数设计。
该工作为LLM安全对齐提供了新思路:不只是教模型正确回答什么,而是教模型在面对扰动时保持“思考和回答”的一致,提升整体鲁棒性和安全性能。
详细论文请见 arxiv.org/abs/2510.27062