[LG]《Planned Diffusion》D Israel, T Jin, E Cheng, G V d Broeck... [University of California, Los Angeles & MIT CSAIL] (2025)
计划扩散:AI文本生成速度与质量的新平衡
在大型语言模型(LLM)时代,生成文本的速度与质量总是难以兼得。传统的自回归模型(AR)质量上乘,但逐个生成token,延迟高;扩散模型能并行生成,却需多轮迭代才能达到同等连贯性。这种权衡限制了LLM的实用性。今天分享一篇arXiv预印本论文《Planned Diffusion》,它提出了一种创新混合方法,巧妙融合两者优势,显著扩展了速度-质量的Pareto前沿。
核心挑战与创新动机
LLM文本生成面临根本矛盾:捕捉文本依赖需要顺序处理,但现代硬件青睐并行计算。自回归模型擅长前者,却因序列生成造成延迟瓶颈;扩散模型强调后者,但低步数迭代下易失连贯性。论文将文本生成视为“动态并行调度问题”,关键洞见是:token依赖是上下文相关的,许多响应包含语义独立的“span”(如列表项目),这些span可并发生成。例如,回答问题时,定义、描述和位置部分往往独立,可同时填充。这不仅加速生成,还保留了整体连贯性——一个实用而深刻的思考:并非所有token都需严格顺序,智能规划能释放硬件潜力。
Planned Diffusion的工作原理
该方法采用单一统一模型,实现自回归与扩散的平滑切换,分两个阶段:
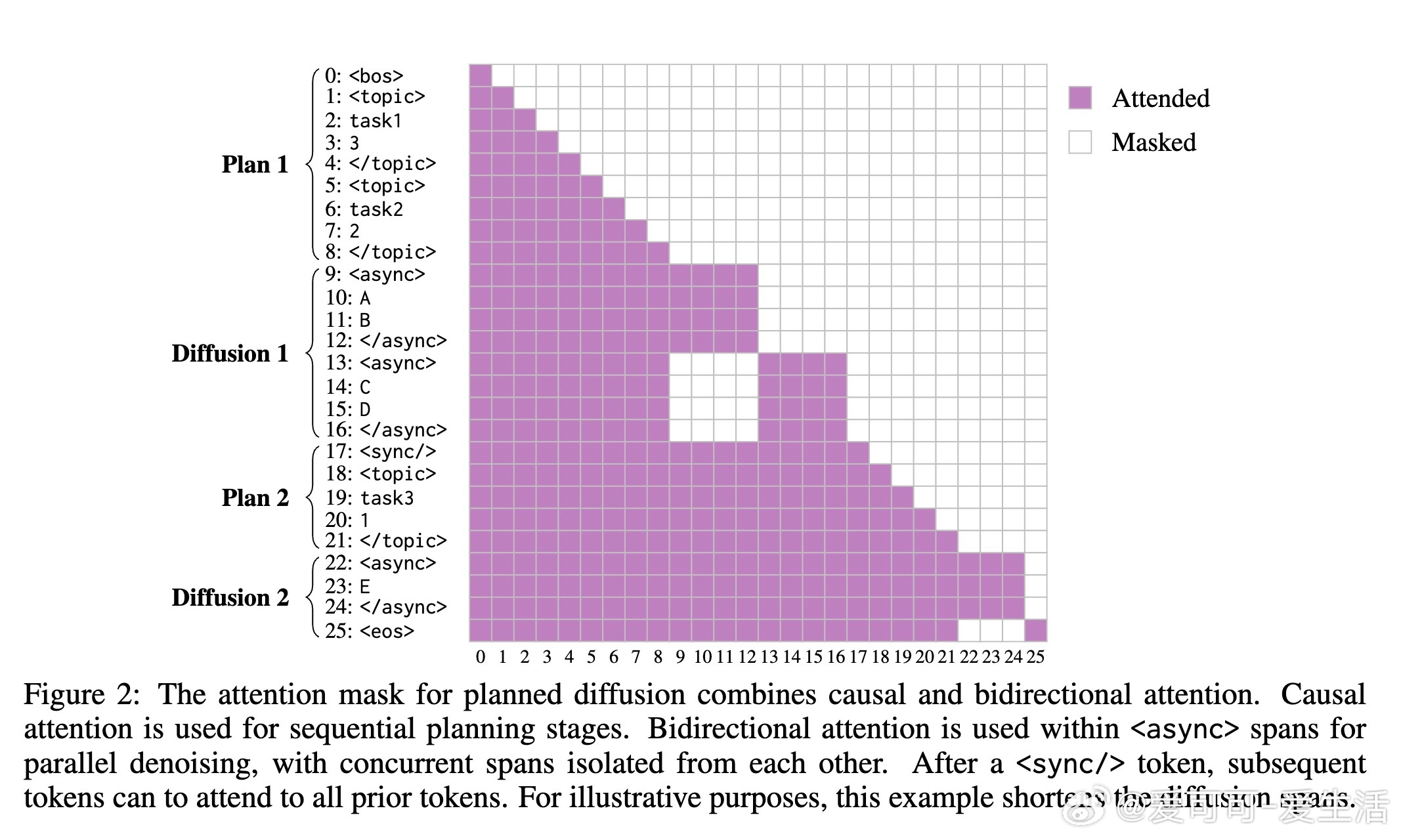
1. 自回归规划阶段:模型顺序生成简短“执行计划”,使用结构化控制标签(如``)将输出分解为条件独立的子span。计划指定每个span的内容主题和长度,捕捉高层次结构,确保后续生成有指导。
2. 并行扩散阶段:基于计划,模型将span初始化为掩码token(如[M]),然后同时去噪生成所有span的内容。扩散过程利用条件独立性,实现真正并行:最长span决定总步数,其他span同步完成。
这一设计巧妙:规划阶段最小化开销(仅几token),扩散阶段最大化并行。论文强调,这是首个纯文本模型,同时训练离散扩散和自回归目标,避免多模型复杂性(如推测解码)。从实现看,他们设计了控制标签语言、合成数据管道(用Gemini标注SlimOrca数据集)和自定义训练目标(结合因果与双向注意力掩码),确保span间隔离与同步(用``标签处理依赖)。推理时,引入KV缓存优化(规划阶段标准缓存,扩散后缓存整个span)和步数比率r(步数=s=r×max长度),允许灵活调控。
举个真实例子:用户问“Aurora Borealis是什么?请简洁。”规划生成三个span(定义、描述、位置),然后并行填充,最终输出连贯响应。这展示了方法如何将复杂生成拆解为高效并行任务,思考深度在于:它不只是加速,而是通过语义结构挖掘内在并行性,推动LLM向更智能调度演进。
实验验证:Pareto最优贸易-off
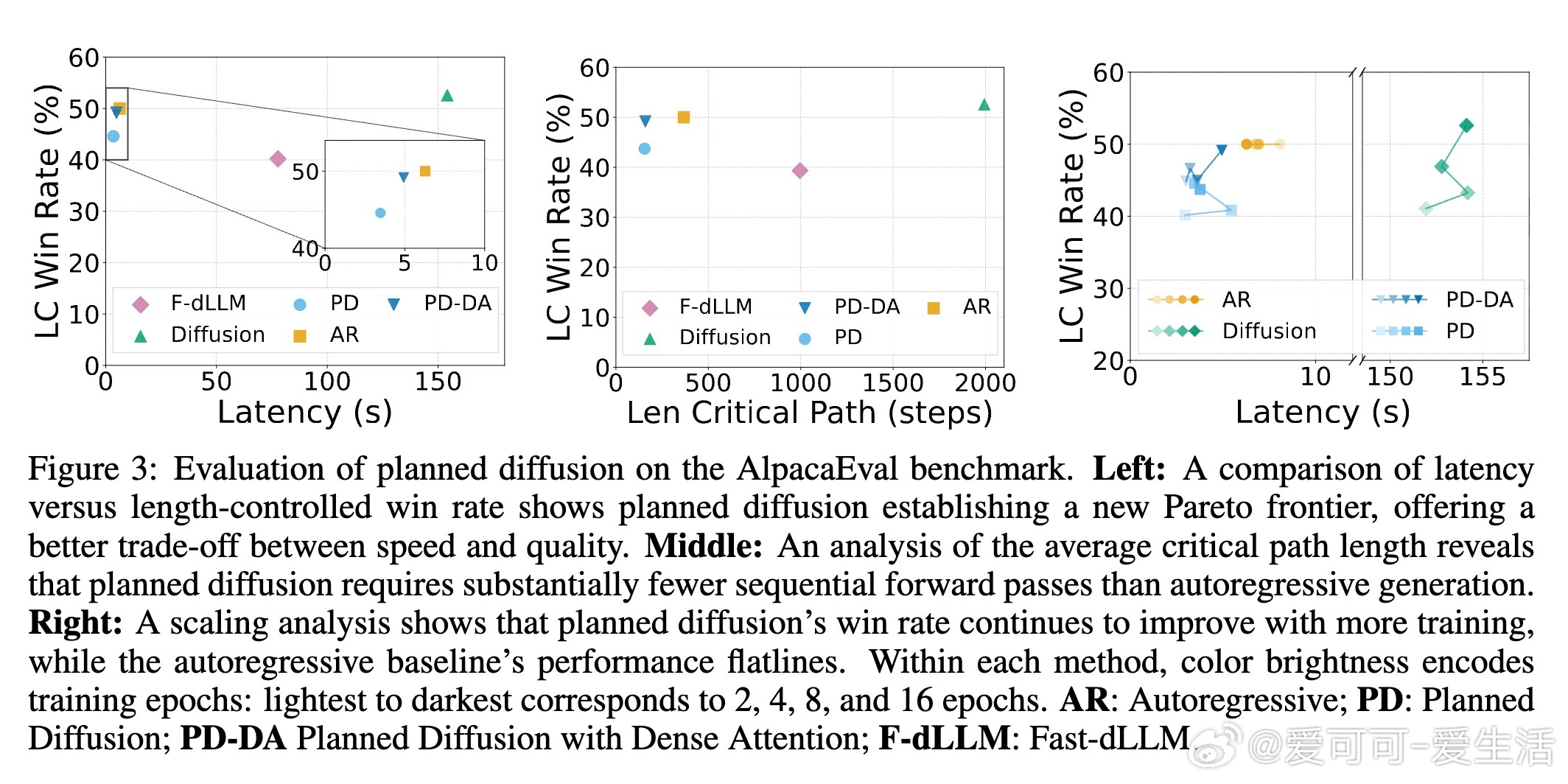
在AlpacaEval基准(805个指令跟随提示)上,基于Dream-7B-Base微调,Planned Diffusion大放异彩。与自回归基线相比,它实现1.27x至1.81x加速,仅质量(长度控制胜率LCWR)下降0.87%至5.4%。具体:
- 标准版(PD):1.81x加速,LCWR 44.6%(vs. AR 50.0%),关键路径缩短2.8x(155步 vs. 367步),因多span并行。
- 稠密注意力变体(PD-DA):1.27x加速,LCWR 49.2%,更友好硬件(全双向注意力,提升GPU利用率)。
- 对比:纯扩散质量最高(52.6%),但延迟25x;Fast-dLLM加速版质量仅40.2%,PD胜其22.4x。
缩放分析显示,PD随训练epoch增加持续优化(2-16 epoch,LCWR升3.5-4.3%),而AR基线 plateau。额外消融验证规划机制可靠:移除主题标签质量暴跌(31.4%),移除同步标签加速至2.08s(质量仅降1.5%)。长度预测准确(峰值在1.0缩放因子),步数比率r和置信阈值τ提供运行时旋钮,实现平滑贸易-off(如r=0.75, τ=0.9下,LCWR 39.5%,延迟3.2s)。
这些结果不仅量化了效率提升,还揭示思考:PD的并行性源于语义洞察,而非盲目加速;它与现有扩散优化(如KV缓存、快速采样)正交,可进一步叠加。未来,这可能启发更高效的LLM架构,尤其在实时应用如聊天机器人中。
为什么值得关注?
Planned Diffusion不是简单混合,而是对LLM生成范式的深刻重构。它证明,智能规划能桥接顺序依赖与并行计算,开启更快、高质量文本生成新时代。对于研究者和开发者,这提供了一个可扩展框架:最小设计、可靠机制、易调参。想象一下,AI响应时间缩短近2倍,却几乎不损质量——这将极大提升用户体验,推动LLM从实验室走向日常。
论文链接:arxiv.org/abs/2510.18087