阿里云新技术砍掉82%英伟达需求阿里云用213块GPU干了1192块的活
阿里云秘密武器亮相顶会SOSP:用新技术砍掉82%的英伟达GPU需求。
一时引起不小关注与讨论。【图1】
这项研究由阿里巴巴与北大合作,阿里云CTO周靖人带队。
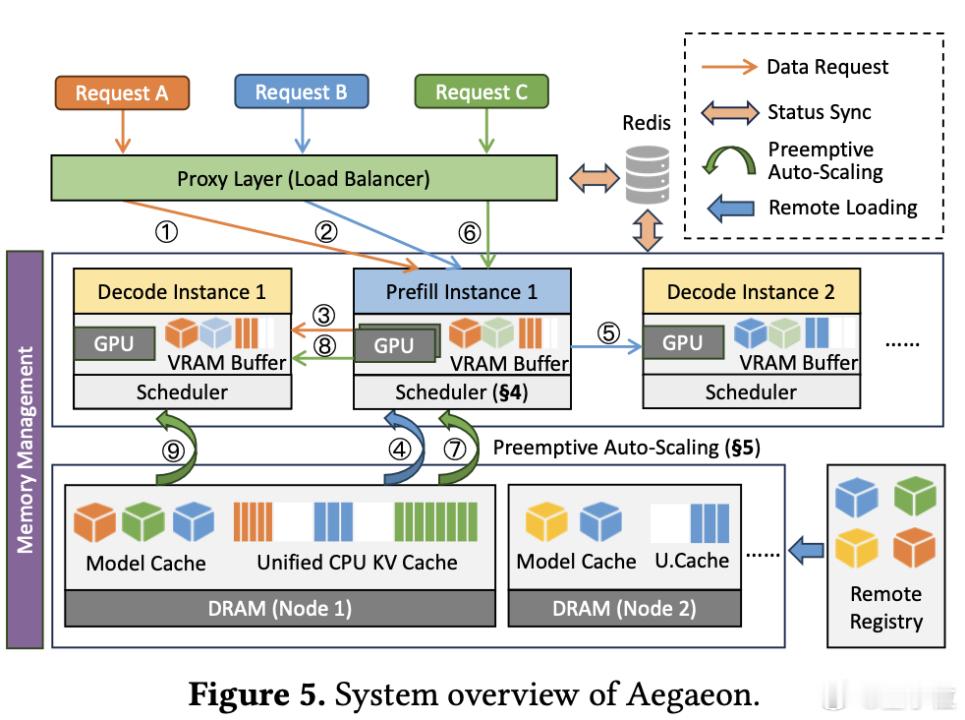
研究提出最新GPU池化系统Aegaeon,用token级别的自动扩缩容技术,硬是把GPU使用量从1192个"瘦身"到213个。【图2】
这项研究出发点在对阿里云自身业务一项观察。
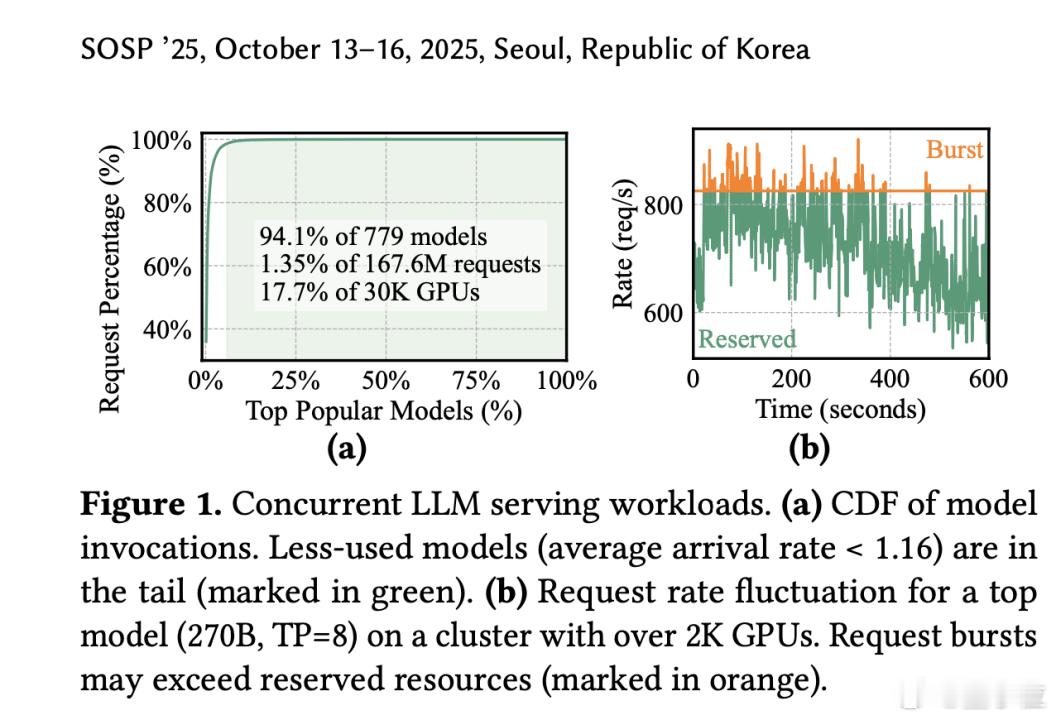
在Model Studio(百炼平台)上,他们发现了一个让人头疼的现象:17.7%的GPU被分配去服务那些几乎没人用的冷门模型,而这些模型只处理了总请求量的1.35%。
之前要同时运行这些模型时,要么给每个模型单独分配GP,很多冷门模型的GPU经常空着浪费,要么用旧方法让一个GPU跑2-3个模型(因为GPU 内存不够,跑不了更多),总之资源利用率特别低。
Aegaeon瞄准这一痛点,通过精细化的资源调度,彻底改变了GPU资源分配的游戏规则。
具体来说,在他们统计的779个模型中,有94.1%的模型属于长尾模型,平均每秒请求量不到0.2个。【图3】
与此同时,那些热门模型比如DeepSeek和通义千问虽然请求量大,但也经常出现突发流量,导致预留的GPU资源时而过载、时而闲置。
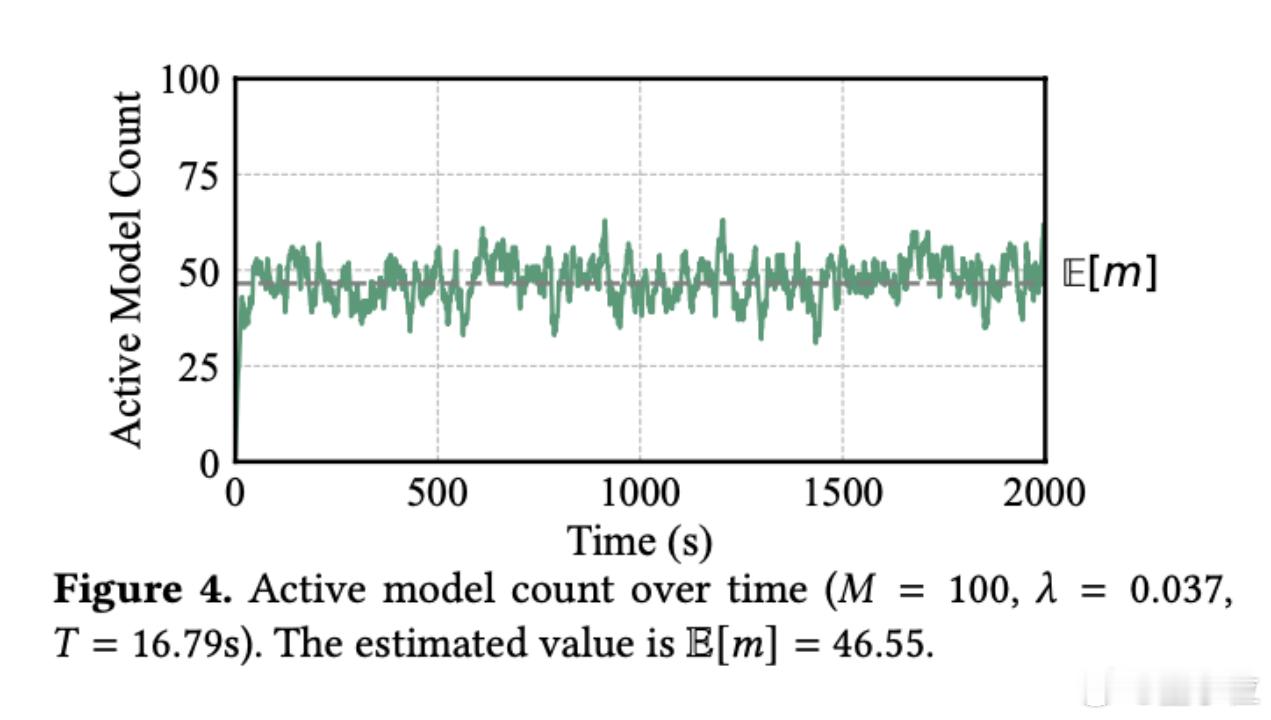
如果按照理想情况计算,单个GPU每秒应该能处理好几个请求,这意味着当前的资源利用率还有超过10倍的优化空间。【图4】
传统的做法是给每个模型分配专用GPU,但这种"一对一"的服务模式在面对大量偶发性请求时,简直就是在烧钱。
Token级别调度,让GPU"见缝插针"
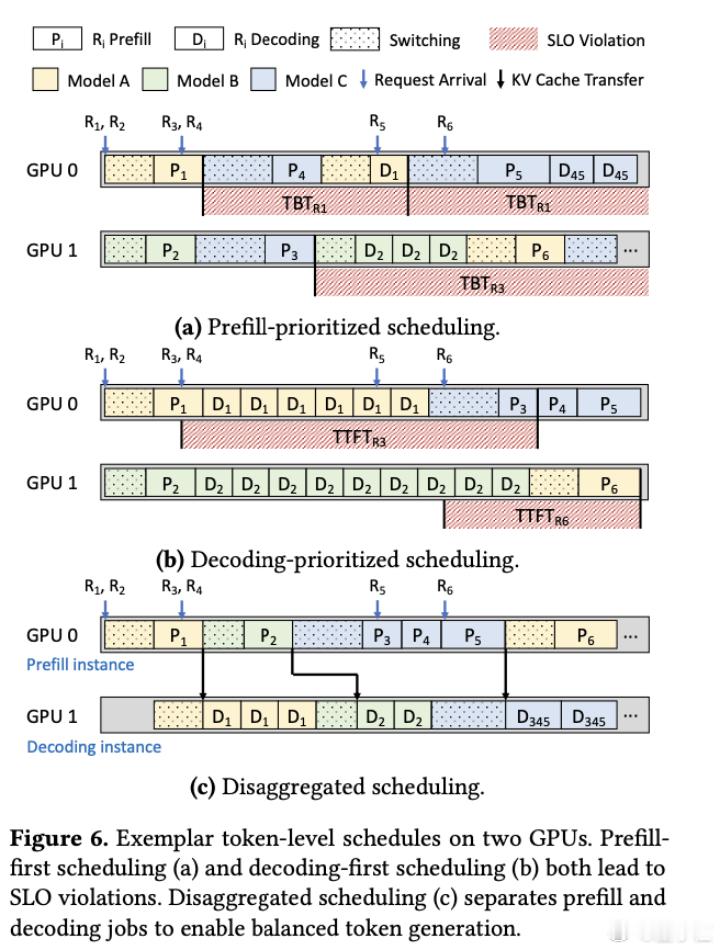
Aegaeon的核心创新在于采用了token级别的自动扩缩容技术,而不是像现有系统那样在请求级别进行调度。
具体来说,系统会在生成每个token时动态决定是否需要切换模型,而不是等到整个请求处理完才考虑切换。
如此一来,可以让让GPU灵活处理多个模型的请求,大大减少了模型之间的等待时间。论文显示,通过这种方式,单个GPU可以同时服务多达7个不同的模型。【图5】
为了实现这个目标,研究团队还进行了一系列底层优化:
- 通过组件复用减少了80%的初始化开销;
- 采用显式内存管理避免了内存碎片;
- 实现了细粒度的KV缓存同步机制,让模型切换时间从几十秒缩短到1秒以内。
整体来看,这些优化将自动扩缩容的开销降低了97%。【图6】
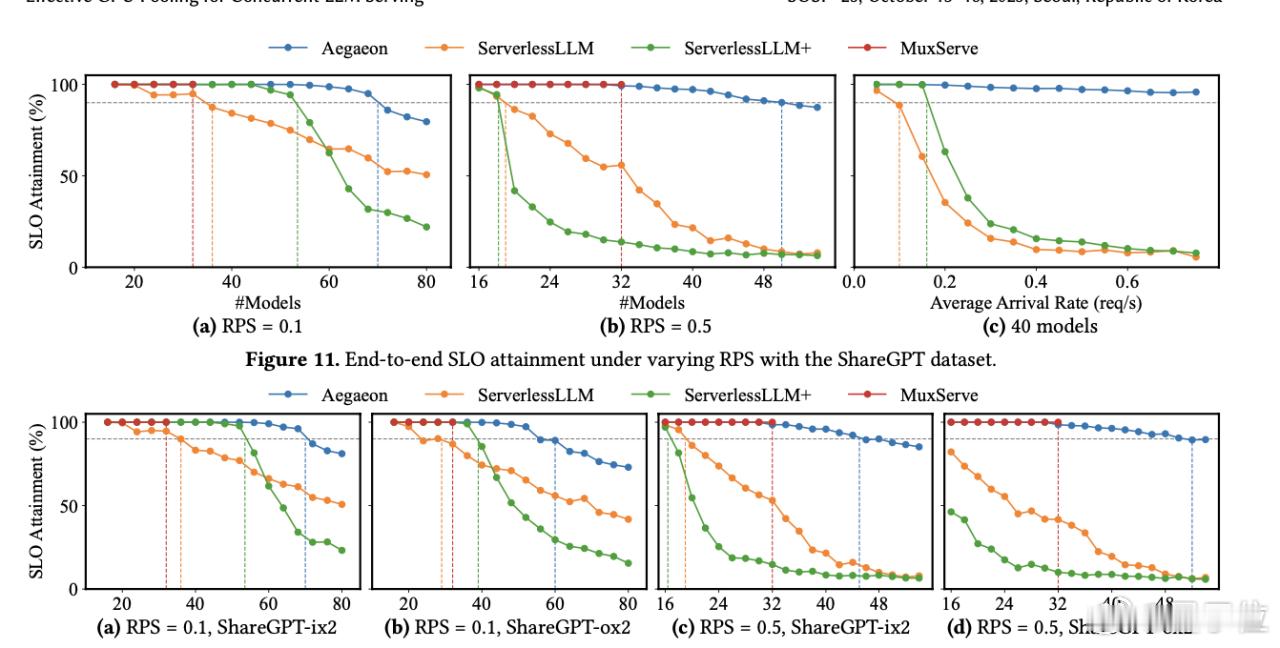
Aegaeon展现出最高可达9倍的性能提升,最低也有1.5倍,计算资源得到了极大的优化。
根据论文数据,与现有的ServerlessLLM和MuxServe等系统相比,Aegaeon能够支撑2-2.5倍的请求到达率,有效吞吐量(goodput)提升了1.5到9倍。在测试环境中,使用16块H800 GPU的集群,系统成功服务了从6B到72B参数规模的多个模型。【图7】
更重要的是,这套系统已经在阿里云百炼平台进行了超过3个月的生产环境测试。
在实际部署中,它服务了47个不同规模的模型,包括28个1.8B-7B的小模型和19个32B-72B的大模型。GPU利用率从之前的13.3%-33.9%提升到了48.1%,期间没有出现任何SLO违规或服务中断。【图8】
论文地址: