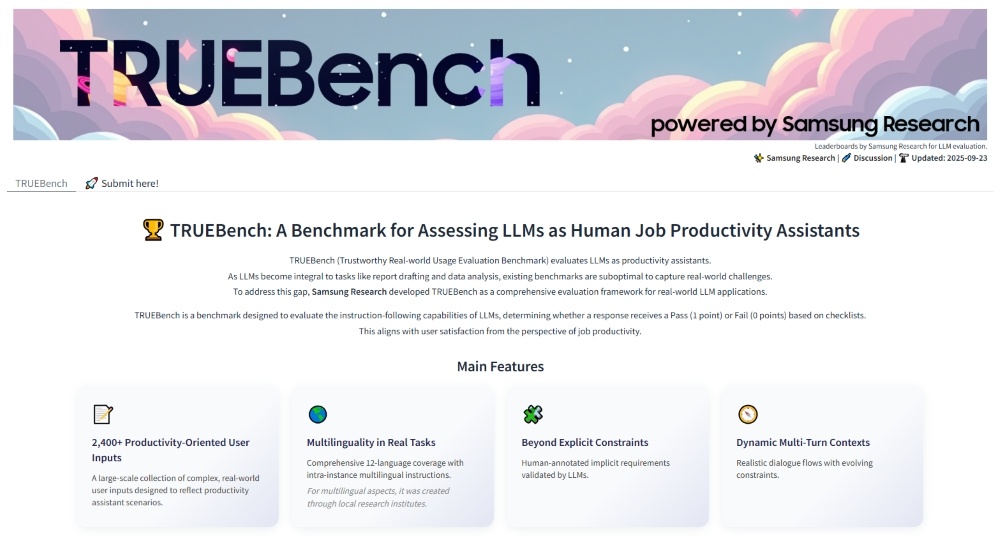
三星电子今天发布了 TRUEBench(可信真实世界使用评估基准),这是三星研究院开发的用于评估人工智能生产力的专有基准。
TRUEBench 提供了一套全面的指标,用于衡量大型语言模型 (LLM) 在实际工作效率应用中的表现。为了确保评估的真实性,它融合了多种对话场景和多语言条件。
TRUEBench 借鉴三星内部人工智能 (AI) 的生产力应用,评估 10 个类别和 46 个子类别中常用的企业任务,例如内容生成、数据分析、摘要和翻译。该基准测试基于由人类和人工智能共同设计和完善的标准,通过人工智能驱动的自动评估,确保评分的可靠性。
三星电子DX部门首席技术官兼三星研究院负责人Paul (Kyungwhoon) Cheun表示:“三星研究院凭借其在现实世界的AI经验,带来了深厚的专业知识和竞争优势。我们期待TRUEBench能够建立生产力的评估标准,并巩固三星的技术领先地位。”
近年来,随着企业采用人工智能完成任务,衡量法学硕士(LLM)效率的需求日益增长。然而,现有的基准主要衡量整体表现,大多以英语为中心,且仅限于单轮问答结构。这限制了它们反映实际工作环境的能力。
为了突破这些限制,TRUEBench 共包含 2,485 个测试集,涵盖 10 个类别和 12 种语言,同时还支持跨语言场景。这些测试集检验了 AI 模型的实际解决问题能力,三星研究院使用的测试集长度范围从最短 8 个字符到超过 20,000 个字符,涵盖了从简单请求到冗长文档摘要的各种任务。
为了评估人工智能模型的性能,必须有明确的标准来判断人工智能的响应是否正确。在现实世界中,并非所有用户意图都会在指令中明确说明。TRUEBench 的设计旨在通过不仅考虑答案的准确性,还考虑满足用户隐性需求的具体条件,从而实现切合实际的评估。
三星研究院通过人机协作验证评估项目。首先,人工注释员创建评估标准,然后人工智能对其进行审核,以检查是否存在错误、矛盾或不必要的约束。之后,人工注释员再次完善标准,并重复此过程以应用越来越精确的评估标准。基于这些交叉验证的标准,对人工智能模型进行自动评估,最大限度地减少主观偏见并确保一致性。此外,每次测试都必须满足所有条件,模型才能通过。这使得跨任务的评分更加详细和精确。
TRUEBench 的数据样本和排行榜已在全球开源平台 Hugging Face 上发布,用户最多可比较五种模型,一目了然地全面比较 AI 模型的性能。此外,还公布了响应结果的平均时长数据,方便同时比较性能和效率。详细信息请访问 TRUEBench Hugging Face 页面:https: //huggingface.co/spaces/SamsungResearch/TRUEBench。