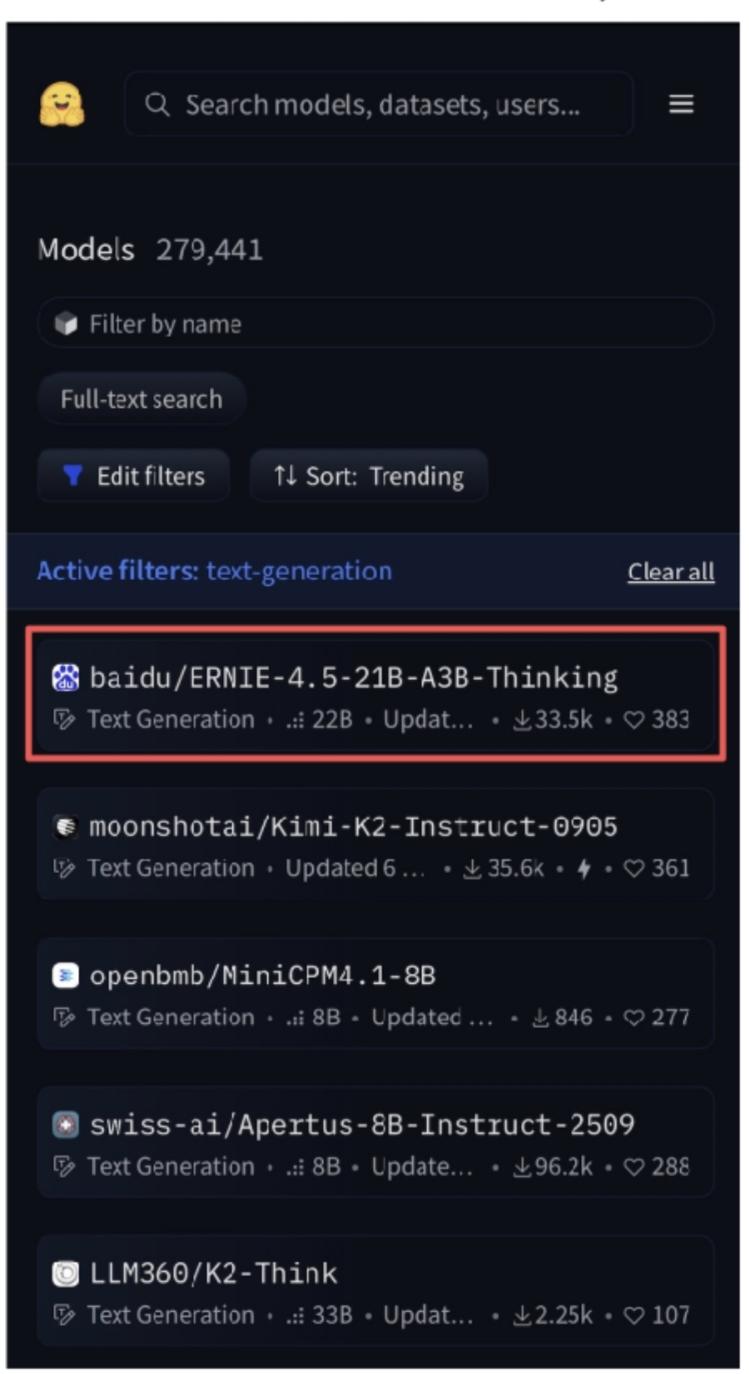
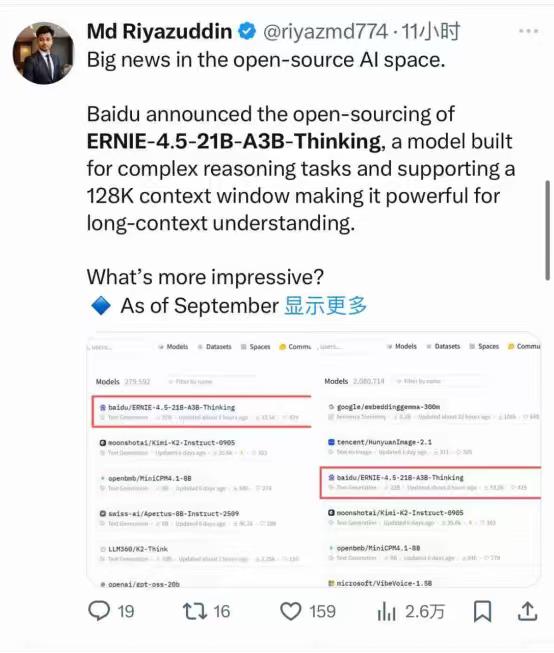
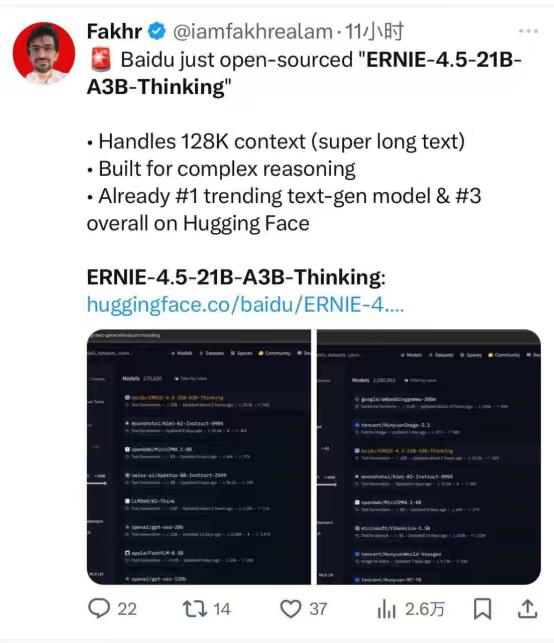
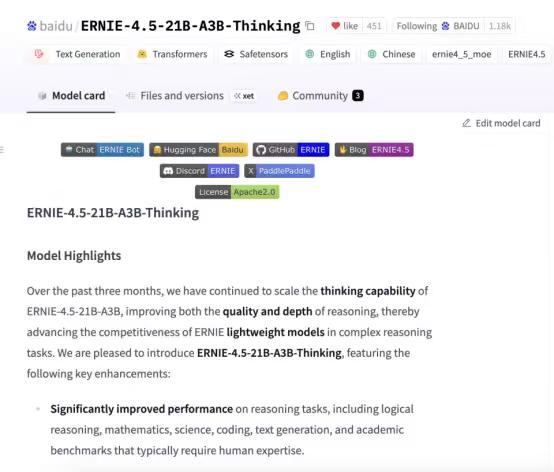
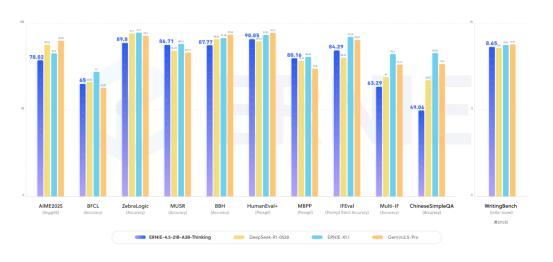
【百度开源模ERNIE-4.5-21B-A3B-Thinking,刚露脸就霸榜】 WAVE SUMMIT 2025大会上,百度一宣布开源ERNIE-4.5-21B-A3B-Thinking,当时只觉得“这模型看起来很能打”,没想到几天后再看,它直接冲上了HuggingFace全球文本模型趋势榜第一,总榜第三,成了开发者圈的“香饽饽”。 它这么火爆的根本原因是“能解决真问题”。很多开发者平时处理任务总卡壳,但这款模型刚好把这些坎都平了——128K的上下文窗口,长文本处理不在话下;逻辑推理、数学、科学领域的表现明显提升,代码和文本生成也更顺;还能高效调用工具,复杂任务能自动拆解,不用再一点点抠细节。对开发者来说,这不是“锦上添花”,是“雪中送炭”。 而能做到这些,背后藏着它的“技术巧劲”。现在不少大模型总想着堆参数,好像参数越多越厉害,但这款模型走了另一条路:用混合专家(MoE)架构,总参数210亿,可每次只激活30亿。简单说就是不用让整个模型“满负荷跑”,既降低了运行成本,又跑出了接近顶级大模型的性能。像给开发者配了个“高效助手”,干活快还不费资源,中小团队也能轻松用得起。 更让开发者安心的是,百度这次的开源“没套路”。用的是Apache License 2.0协议,允许商业使用——不管是个人做研究,还是企业落地项目,都不用担心版权问题。 而且模型一发布,就同步上了HuggingFace、星河社区这些常用平台,FastDeploy、vLLM、Transformers这些工具也适配好了,直接加载就能用。 特别是FastDeploy的一键部署,哪怕是刚入门的开发者也能搭起推理服务,不用再在环境配置上耗几天。 连海外开发者都忍不住“自来水”——有人在社区发评测视频,热度直接炸裂,这种不用官方推,大家主动帮着传播的热度,才是真的认可。 从 WAVE SUMMIT 大会上的“一眼心动”,到HuggingFace上的“全球登顶”,这款模型的爆火其实很简单:它没搞虚头巴脑的参数竞赛,而是盯着开发者的真实需求,把“好用、好部署、敢商用”做到了实处。 对国产AI来说,这或许也是一条更扎实的路——不用靠噱头吸引关注,靠解决问题的硬实力,照样能在全球舞台上站稳脚。 百度 AI大模型