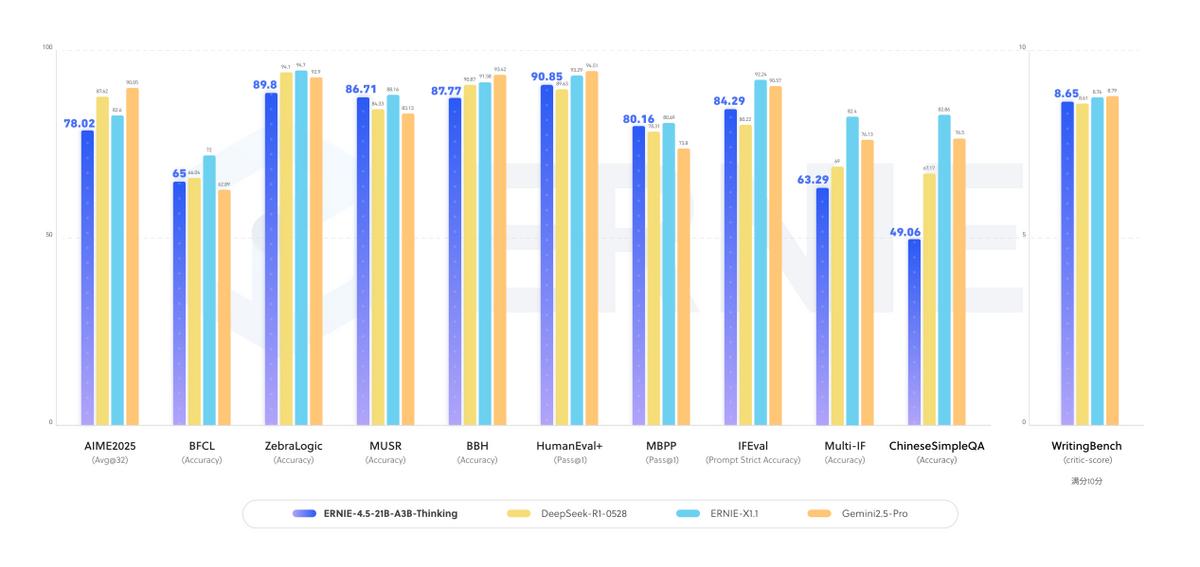
【从基础迭代到全球热捧!百度这款模型改写轻量AI格局】 在AI模型赛道,“堆参数”曾是提升性能的主流思路,但百度最新开源的ERNIE-4.5-21B-A3B-Thinking,却用“迭代升级+效率优化”走出了新路子——它在ERNIE-4.5-21B-A3B基础上,经过指令微调与强化学习训练成深度思考模型,刚亮相2025年WAVESUMMIT深度学习开发者大会,就拿下HuggingFace全球模型趋势榜热度第一、总榜第三的成绩,重新定义了轻量模型的实力上限。 它最颠覆性的突破,在于“参数效率”的革命。不同于传统大模型靠全量参数运行的模式,这款模型采用混合专家(MoE)架构,总参数规模达21B,但每个token仅激活3B。这种“按需激活”的设计,就像给模型装了“智能开关”,只在需要的环节调用对应能力,既避免了资源浪费,又实现了性能跃升——在各项测试中,它的表现紧追业界顶级大尺寸模型,用轻量级规模达到了接近SOTA的智能水平,直接打破了“参数越多性能越强”的固有认知。 对实际应用来说,它的“实用属性”也拉满了。首先是长上下文处理能力,128K的上下文窗口能轻松应对长篇文档分析、多轮复杂对话等场景,不用再担心模型“记不住前文”;其次是全领域能力覆盖,不管是逻辑推理、数学演算、科学原理推导,还是代码生成、文本创作,它都实现了显著提升,甚至能高效调用工具完成自动化处理,满足从日常办公到专业研发的多样化需求。 更关键的是,它把“开源友好”做到了实处。不仅采用允许商业使用的ApacheLicense2.0协议,让个人和企业都能放心用,还在HuggingFace、星河社区等平台同步发布,FastDeploy、vLLM、Transformers等工具也已完成适配——FastDeploy的一键部署和单卡运行功能,更是让普通开发者不用纠结硬件,就能快速落地应用。如今海外开发者自发评测热度持续上升,社区讨论活跃,足以证明这款来自百度的模型,已经凭借技术实力和开源诚意,获得了全球开发者的认可,为轻量AI的发展打开了新空间。