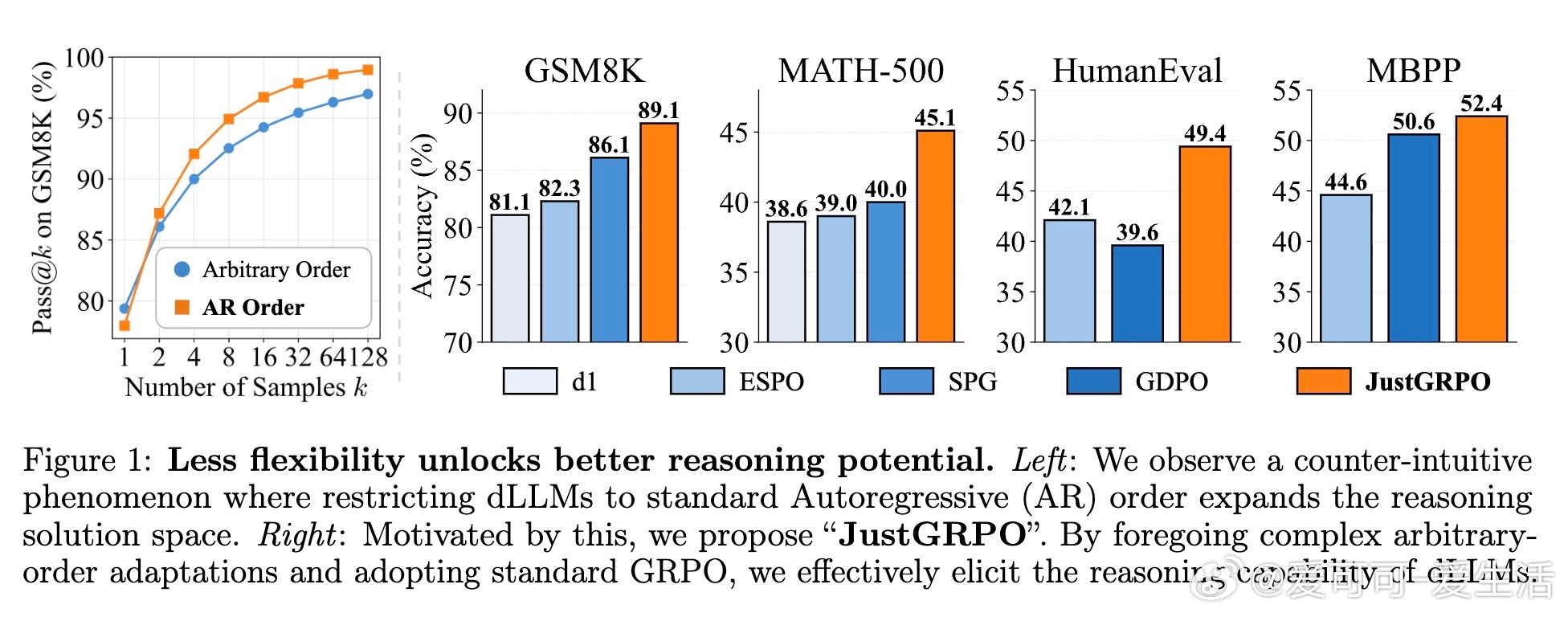
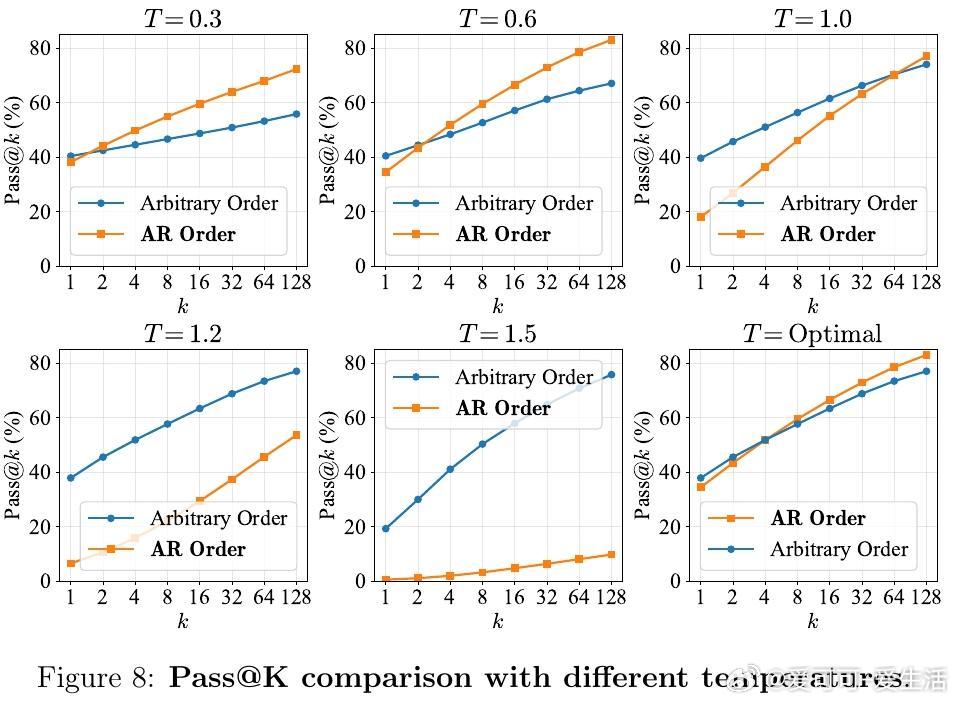
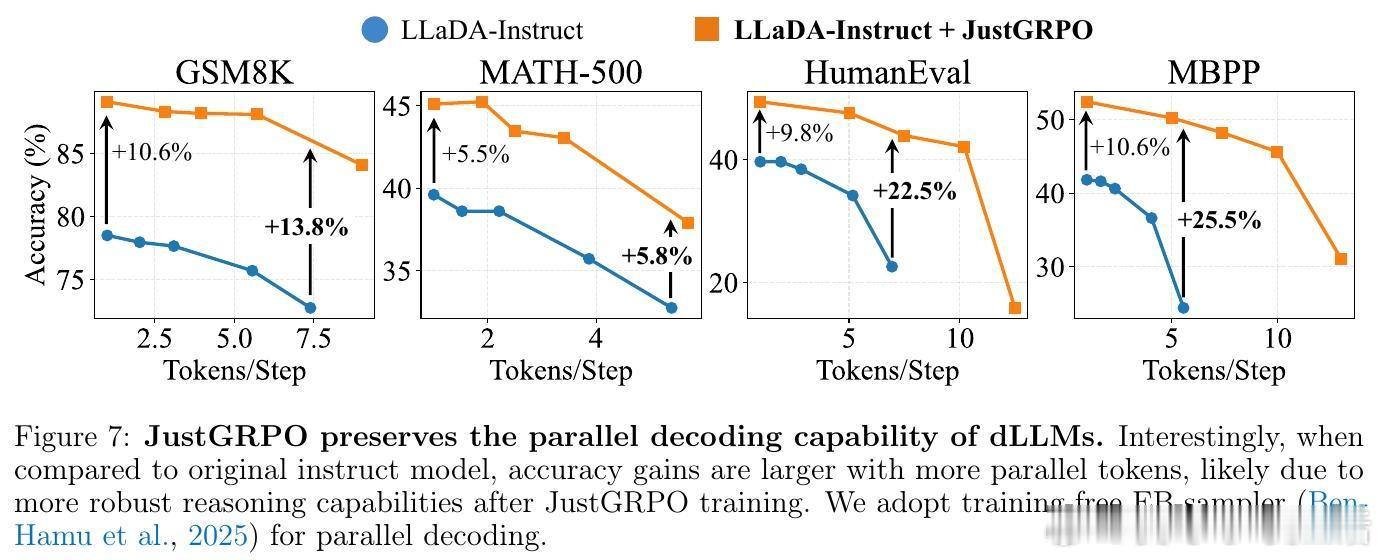
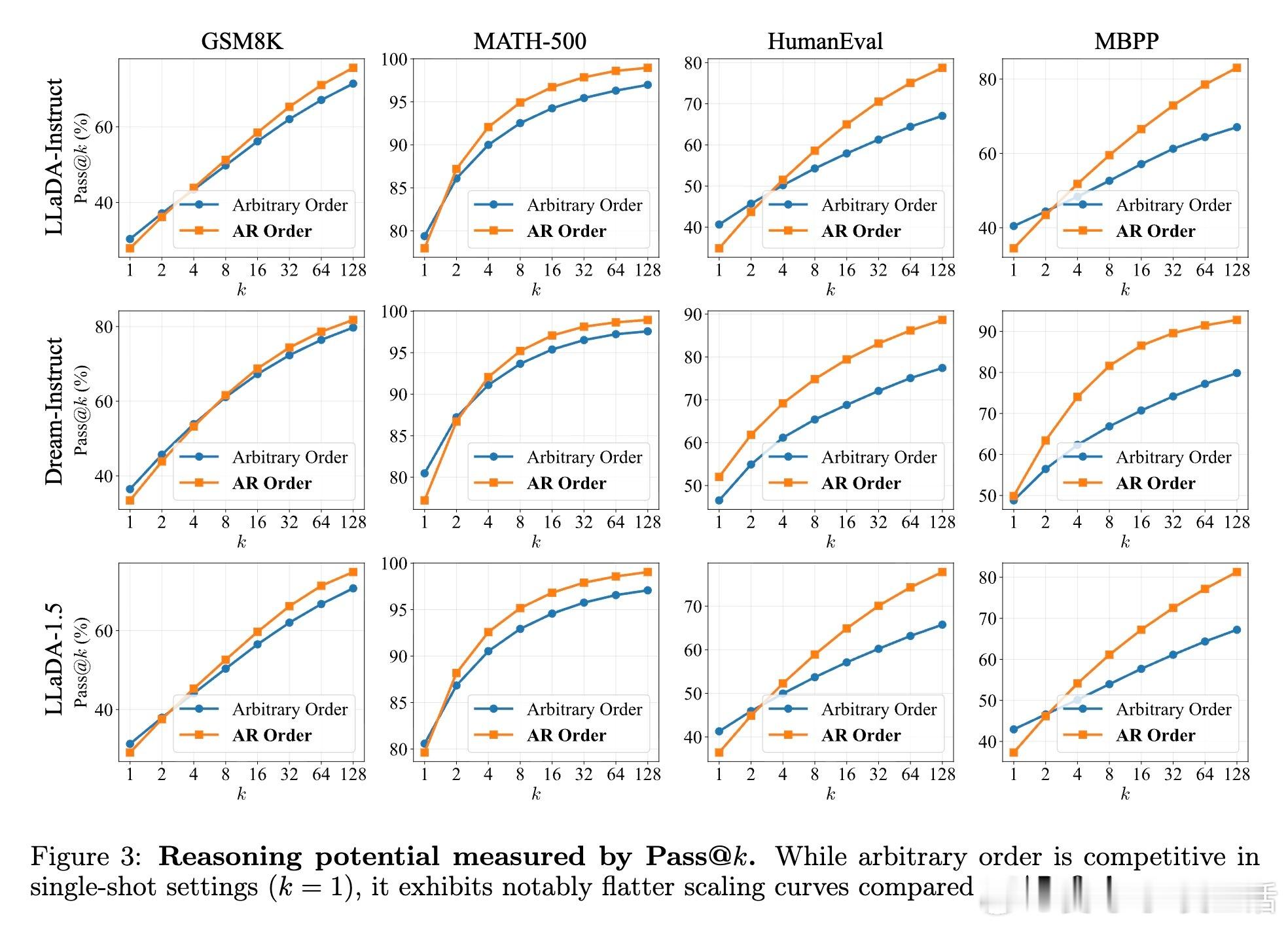
[CL]《The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models》Z Ni, S Wang, Y Yue, T Yu, W Zhao... [Tsinghua University] (2026) 灵活性陷阱:为什么限制生成顺序,反而能释放扩散大模型的推理潜力?扩散大模型(dLLM)一直以打破自回归(AR)的从左到右限制、支持任意顺序生成而著称。直觉上,这种灵活性应该能让模型在处理数学或代码时先易后难,展现更强的推理能力。但清华大学 LeapLab 等团队的最新研究揭示了一个反直觉的真相:这种灵活性其实是一个陷阱。研究发现,如果将扩散模型强制限制在标准的自回归顺序下,其推理潜力的上限反而会显著提升。这一发现挑战了目前 dLLM 领域追求生成顺序任意性的主流方向。核心问题在于一种被称为熵减退(Entropy Degradation)的现象。推理本质上是非均匀的,它依赖于少数关键的逻辑分叉点,比如因此、由于或既然。在自回归模式下,模型必须在这些分叉点正面应对不确定性,从而探索不同的逻辑路径。然而,在任意顺序生成中,模型会利用灵活性绕过这些高熵的难点,优先生成低熵的简单词汇。当模型最终回头填充那些被跳过的逻辑分叉点时,已经建立的上下文已经严重压缩了逻辑空间。此时模型不再是在做逻辑导航,而是在做语义填空。模型为了局部的连贯性,牺牲了对多样化推理路径的探索。为了解决这一问题,研究者提出了 JustGRPO。与其为了保留灵活性而设计极其复杂的扩散模型专用强化学习算法,不如返璞归真:在强化学习阶段,直接将扩散模型当作自回归模型来处理,并应用标准的 GRPO 算法。这种方法去掉了处理组合轨迹和不可计算似然值的沉重负担,将复杂的优化问题简化为定义明确的任务。实验结果令人惊叹:JustGRPO 在 GSM8K 上达到了 89.1% 的准确率,在 MATH-500 上达到 45.1%,全面超越了那些专门为扩散模型设计的复杂 RL 方法。最精妙的地方在于,这种自回归约束仅存在于训练阶段,作为一种引导推理的脚手架。在推理阶段,模型依然保留了扩散模型特有的并行解码能力。这意味着我们既获得了自回归模型的推理深度,又保留了扩散模型的生成速度。这项研究带给我们深刻的启发:在人工智能的设计中,约束并不总是枷锁,它也可以是通往深层逻辑的扶手。有时候,放弃一部分自由,反而是解锁更高阶能力的钥匙。arxiv.org/abs/2601.15165