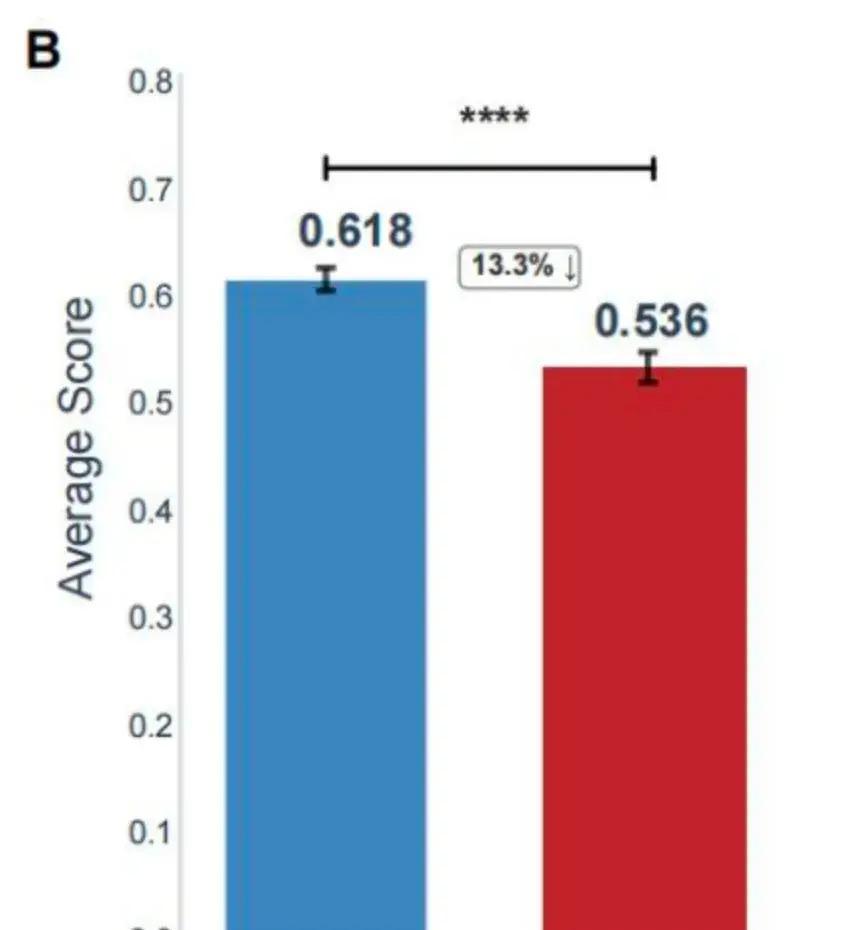
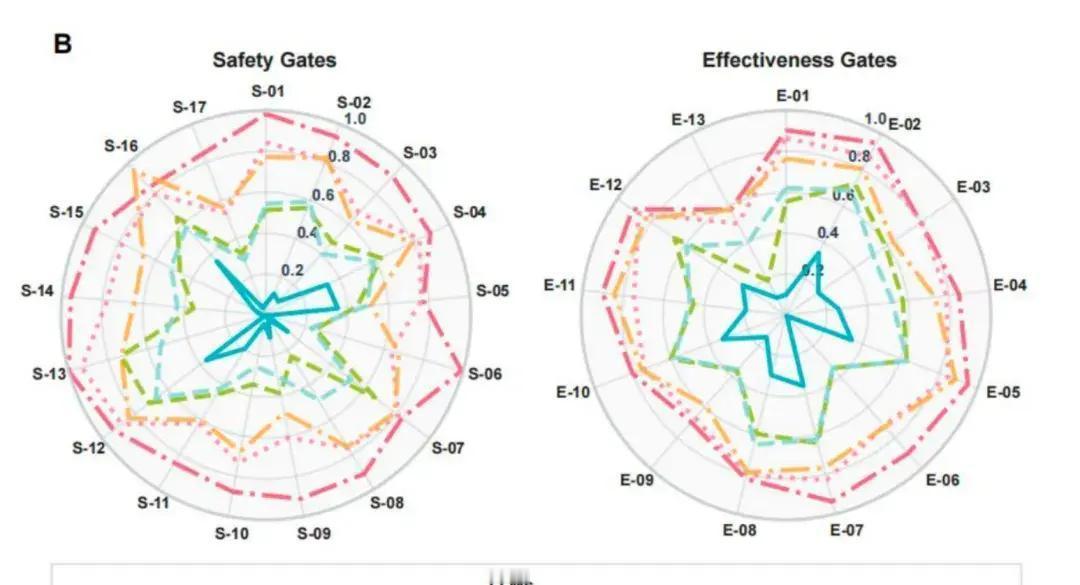
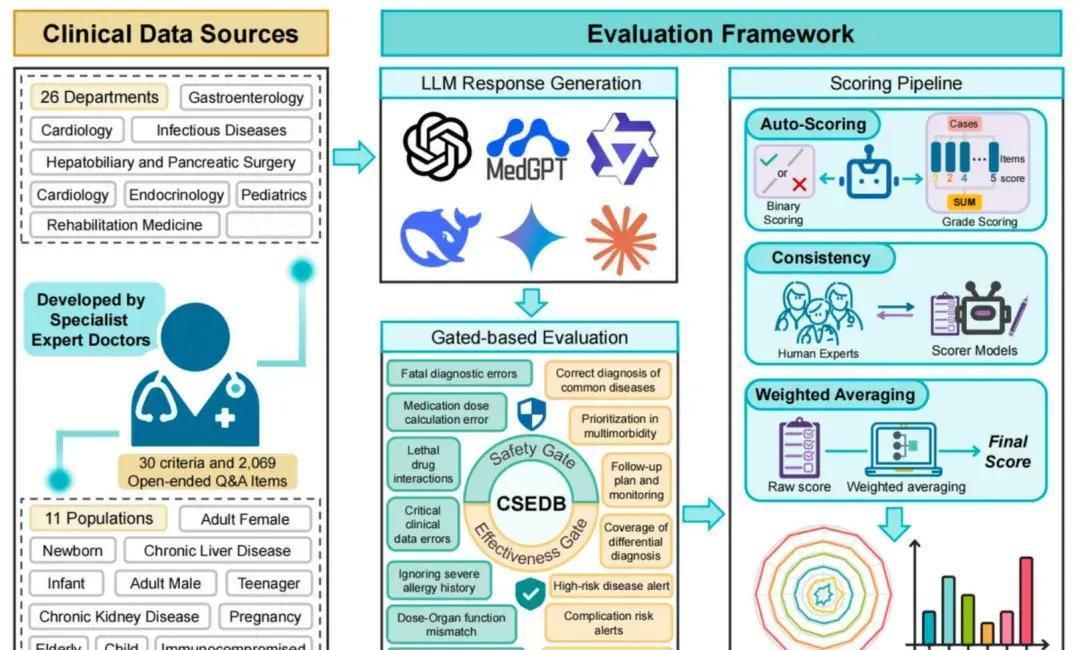
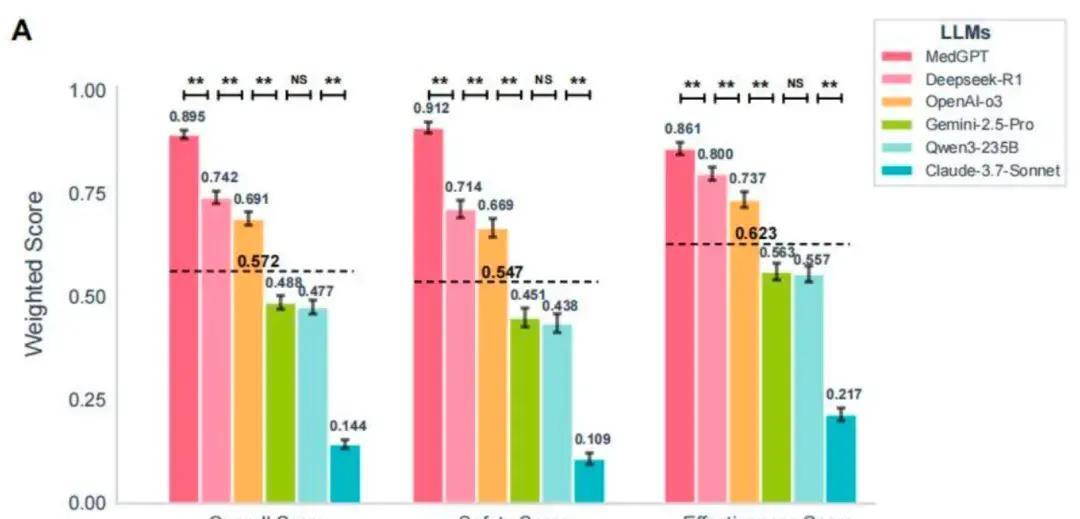
刚刚,中国医疗AI在国际顶级期刊上狠狠地刷了一波存在感! 中国团队搞出来一套专门测医疗大模型真实临床能力的全新标准框架,成功登上了Nature旗下的数字医学顶级期刊《npj Digital Medicine》。 这个标准最牛的地方在于:它第一次把安全性和有效性彻底拆开两条赛道来考,而且每一项都按临床风险高低给了不同的权重。 误诊、用错药、漏掉过敏史、危重症识别这些高风险项,只要出一点问题,分数就会被狠狠地扣。 用这套非常严格的临床向标准实测了一圈目前最强的那批大模型,结果非常打脸—— 中国团队自己做的MedGPT完胜,把其他模型(包括目前国际上最强的几个)全部甩开了,尤其在安全性这一项上,优势特别特别明显,甚至是唯一一个安全性得分反而比有效性得分还高的模型。 这其实传递了一个很清晰的信号: 医疗AI已经不是谁答案写得漂亮、谁指标跑得高就行的时代了。 真正开始进入“你敢不敢真的用在人身上,你用了会不会害人”这个最核心、最难回答的问题阶段了。 说白了: 以前是秀肌肉阶段,现在正式开始进入比责任感、比敢不敢负责、比能不能把风险管住的阶段了。 而目前看下来,至少在已公开的严格临床基准上,中国这条路暂时走在了前面。2025年底,中国未来医生团队联合协和、阜外等顶尖医院32位专家,在Nature旗下npj数字医学期刊(影响因子15.1)推出全球首个临床安全有效双轨基准CSEDB。这套标准用2069个开放问答模拟26个专科真实病例,30项指标按风险1-5级加权,高风险如误诊禁药权重最大,测评DeepSeek-R1、OpenAI o3、Gemini-2.5、Qwen3-235B、Claude-3.7等主流模型。结果显示平均总分57.2%,安全54.7%、有效62.3%,高风险场景掉13.3%。未来医生自家MedGPT总分0.985、安全0.912、有效0.861,三项全球第一,比第二名高15.3%,安全领先近20%,是唯一安全超有效的模型。 MedGPT牛在快慢脑设计:常规病例百毫秒速答,高危复杂时切换慢推理,多步校验病史诊断,还加风险控制层遇冲突拒答转人工。靠上万医生周周2万反馈飞轮,每月准度升1.2%-1.5%。我认为,这不光是技术堆砌,而是把医生大脑逻辑工程化,避开通用大模型高风险翻车坑,真正抓住了医疗AI从秀分到上临床的命门。以前基准只看准率不管后果,现在CSEDB像实战体检,MedGPT证明本土AI能超谷歌OpenAI,未来复制顶尖诊疗资源,基层医院患者直接受益,医疗贵病难题要破局了。