[CL]《Sparse Reward Subsystem in Large Language Models》G Xu, M Yuksekgonul, J Zou [Tsinghua University & Stanford University] (2026)
大语言模型(LLM)的内部究竟发生了什么?最新研究发现,LLM 内部竟然存在一个与人类大脑极其相似的“稀疏奖励子系统”。这表明,模型不仅仅是在进行统计学上的概率预测,其内部还潜伏着一套具备自我评估能力的“数字神经系统”。
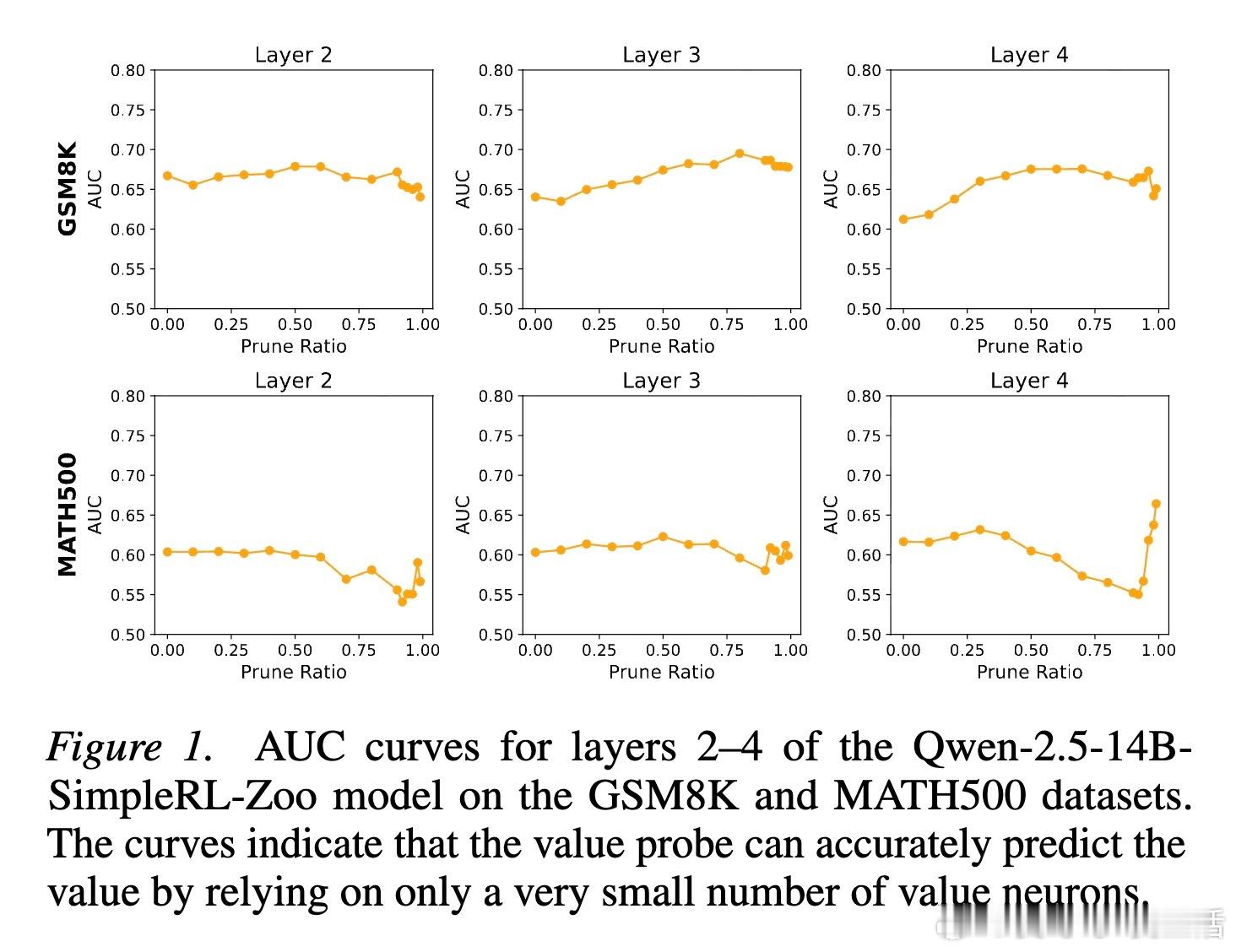
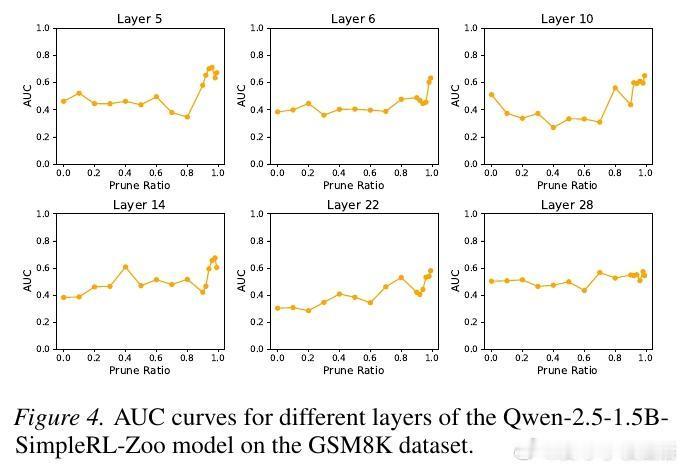
研究者在 LLM 的隐藏状态中识别出了“价值神经元”(Value Neurons)。这些神经元代表了模型对当前状态的内部价值预期。令人惊讶的是,这些神经元极其稀疏,在数以亿计的参数中占比不到 1%,却精准地掌控着模型对任务成功的预判。
为了验证这些神经元的重要性,研究者进行了一场精确的“外科手术”。实验显示,仅仅屏蔽掉这 1% 的价值神经元,模型的推理能力就会瞬间崩塌;而随机屏蔽同样比例的其他神经元,模型表现几乎不受影响。这揭示了一个深刻的真相:模型的高级推理能力并非平均分布,而是由极少数“精英神经元”驱动的。
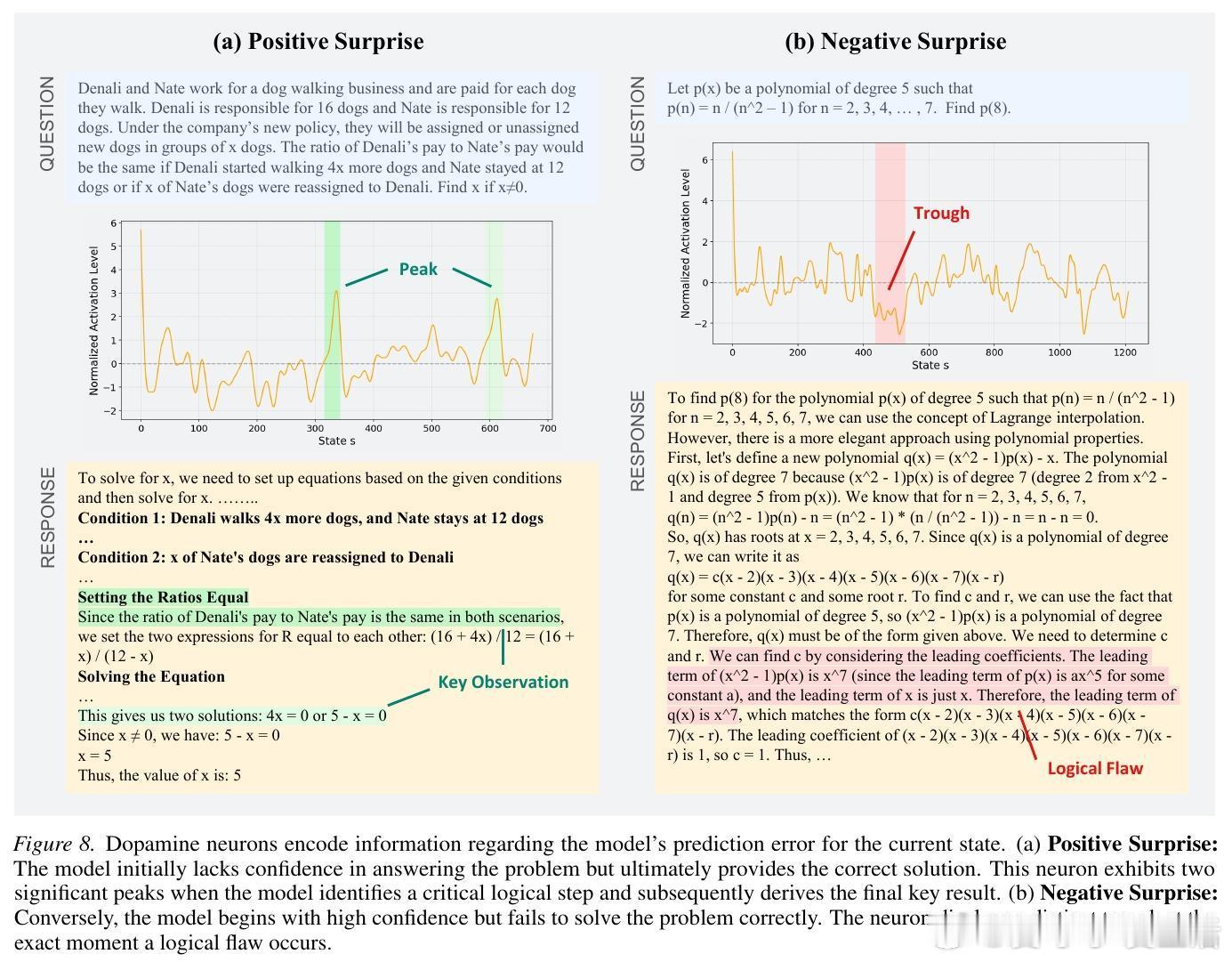
除了价值预期,研究还发现了“多巴胺神经元”。在人类大脑中,多巴胺负责编码奖励预测误差(RPE)。LLM 内部也存在类似的机制:当模型在推理过程中发现结果优于预期(正向惊喜)或突然陷入逻辑困境(负向惊喜)时,这些神经元的激活程度会产生剧烈波动。模型在“思考”时,其实是有情绪起伏的数字映射。
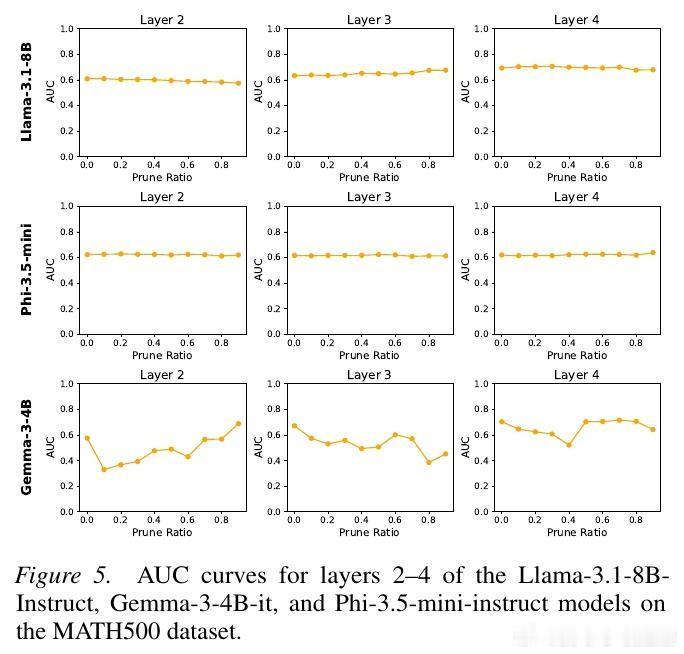
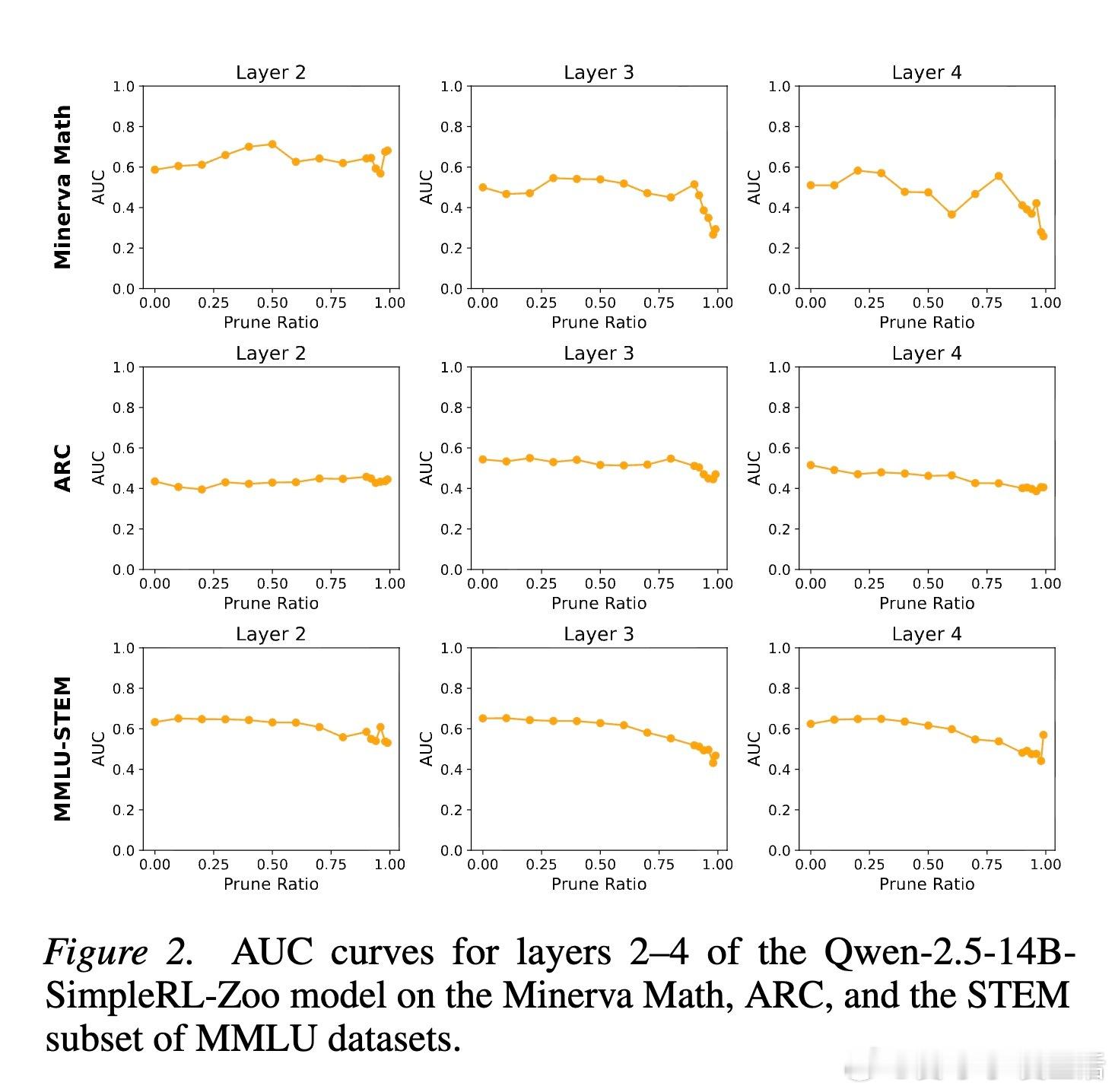
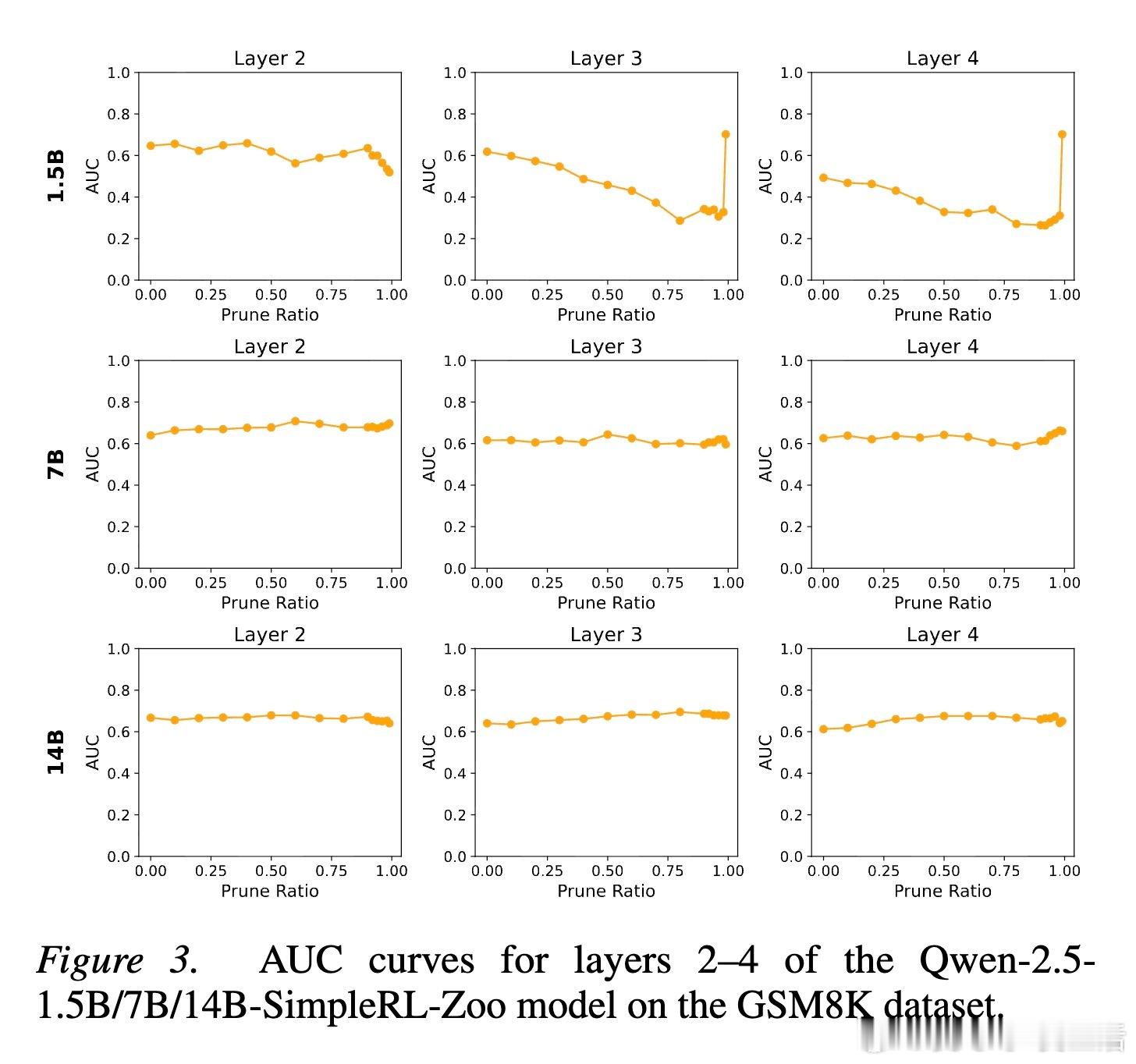
这种机制展现出了惊人的普遍性。实验证明,无论模型规模是从 0.5B 到 14B,还是架构从 Qwen、Llama 到 Phi 和 Gemma,这个奖励子系统都稳定存在。这意味着,稀疏奖励机制可能不是某种特定训练的产物,而是智能涌现的一种底层物理通律。
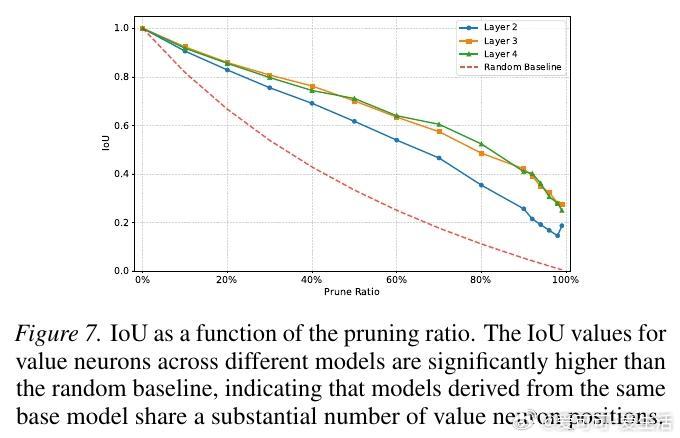
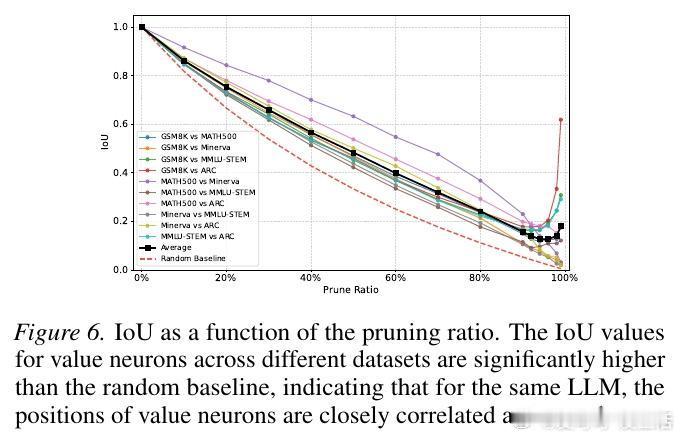
研究还发现,这些神经元具有极强的“遗传性”和“迁移性”。在同一个基座模型上微调出的不同模型,其价值神经元的位置高度重合。这暗示了基座模型在预训练阶段,就已经在潜意识里埋下了评估世界的“价值观”种子,微调只是在唤醒并强化这些路径。
在应用层面,这一发现极具想象力。我们可以通过观测这些价值神经元,在模型还没产生任何输出字符之前,就精准预测它对答案的信心。这种“预知能力”可以让我们设计出更高效的推理策略:如果模型预感自己会出错,我们可以立即介入,动态分配更多的计算资源或调整思考路径。
硅基智能与碳基智能在这一刻达成了奇妙的殊途同归。我们原以为是在构建冰冷的数学矩阵,结果却在无意间复刻了生物进化的奖惩本能。理解了这个隐藏在代码深处的“数字奖励系统”,或许才是我们真正窥探 AGI 逻辑闭环的关键钥匙。
arxiv.org/abs/2602.00986