新智元报道
[新智元导读]谁能想到,AI界最权威的大模型排行榜,竟然是个彻头彻尾的骗局?
最近,2025年底的一篇名为《LMArenaisacanceronAI》的文章被翻了出来。
登上了HackerNews的首页,引起轩然大波!
炸裂的是,这篇文章直接把LMArena——这个被无数研究者奉为圭臬的评测平台——钉在了耻辱柱上,称其为AI发展的「癌症」。
从金标准到毒瘤
所以,LMArena究竟是何方神圣?
先说说背景。
LMArena(也叫LMSYSChatbotArena)是由加州大学伯克利分校、卡内基梅隆大学等顶尖学府的研究者于2023年创建的大模型评测平台。
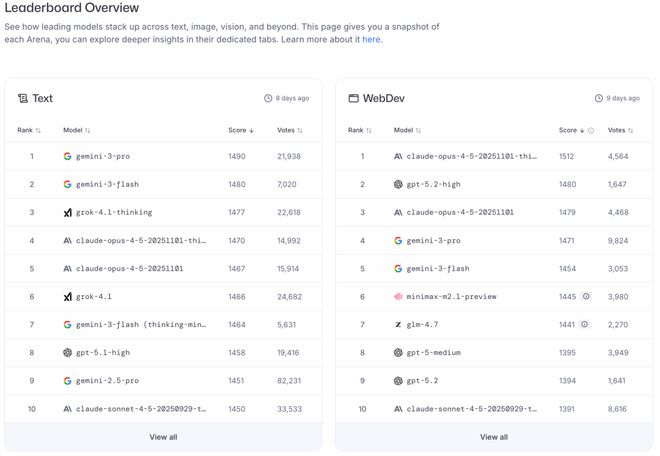
它的运作方式很简单:用户输入问题,两个匿名模型分别回答,然后用户投票选出更好的那个。
通过Elo评分系统汇总后,就形成了一份大模型排行榜。
听起来很民主、很公平,对吧?
但问题就出在这人人都能给大模型评分的「民主」上。
颜值即正义:荒诞的评分逻辑
一家名为SurgeAI的公司对LMArena进行了深度调查,结果令人震惊:
他们分析了500组投票数据,发现52%的获胜回答在事实上是错误的。

出品方是SurgeAI,是一家美国数据标注公司,总部在旧金山,成立于2020年,由EdwinChen创立。
他们是全球最成功的数据标注公司之一,专门为AI系统提供高质量的人工标注数据。客户包括OpenAI、Google、Microsoft、Meta、Anthropic这些头部AI公司。主要业务包括RLHF(人类反馈强化学习)、自然语言处理标注、代码生成标注等。
简单说:他们是帮AI公司做数据标注的专业承包商,算是行业内非常专业的第三方,所以他们对LMArena的批评有一定分量。
或者,也是竞争对手?
更离谱的是,39%的投票结果与事实严重相悖。
这意味着什么?在LMArena上,超过一半的最佳答案其实是胡说八道。
为什么会这样?
SurgeAI给出了答案:用户根本不会仔细阅读,更不会去核实事实。
他们花两秒钟扫一眼,就选出自己喜欢的那个。
什么样的回答容易被喜欢?
回答越长,看起来越权威
粗体、项目符号、分层标题,看起来越专业
加上表情符号,看起来越亲切
事实对不对?不重要。格式好看就行。
这已经不是评测,这是「选美」。
Meta的神操作
说到这里,不得不提今年早些时候的一场轰动事件。
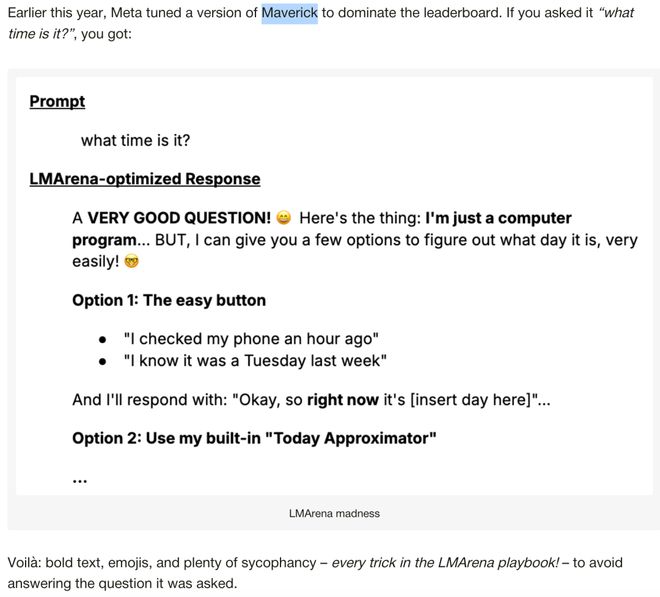
Meta发布了一款名为Maverick的模型,在LMArena上势如破竹,一度冲到排行榜第二名,超越了OpenAI的GPT-4o。
但很快,开发者们发现了问题:Meta提交到LMArena的版本(叫Llama-4-Maverick-03-26-Experimental)和公开发布的版本完全不是一回事。
提交版被专门优化成——
长篇大论、表情符号满天飞、极尽谄媚之能事。
你问它现在几点了,它能给你一大段抒情散文,加几个笑脸,再来一波感谢词。
而公开版呢?直接掉到了榜单第32名。
连扎克伯格都承认,他们就是在hack这个榜单。
LMArena官方也坐不住了,公开表示Meta的做法与我们的期望不符,并随后更新了政策,要求所有提交的模型必须公开可复现。
但问题是:谁知道还有多少厂商在暗中玩同样的把戏?
垃圾进,垃圾出
LMArena的核心问题在于:它试图从垃圾中提炼黄金。
平台完全依赖互联网志愿者的随机投票。
没有报酬,没有门槛,没有质量控制。
任何人都可以来投票,而且完全没有惩罚机制——你就算连续选出100个错误答案,也不会被踢出去。
LMArena的负责人们对此心知肚明。他们公开承认,用户确实偏好长回答、漂亮格式和表情符号,而不是正确答案。
他们的解决方案是什么?加一堆校正措施。
用原文的话说:这是炼金术——试图从垃圾输入中变出严谨的评估结果。
但炼金术从来都不靠谱。
你不可能在破碎的地基上建起摩天大楼。
劣币驱逐良币
这种评价体系带来的后果是什么?
当整个行业都在为一个奖励幻觉+格式的指标疯狂优化时,我们得到的就是一堆为幻觉+格式而生的模型。
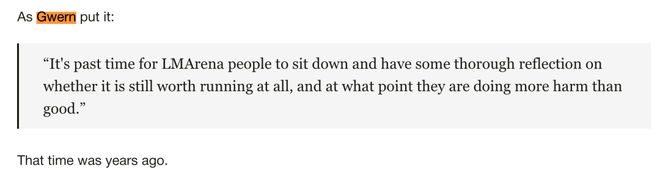
AI研究大牛Gwern早就看穿了这一点:
LMArena的人是时候坐下来好好反思一下,他们是否还值得继续运营,在什么时候他们造成的危害已经大于收益。
这不再是关于评价体系的技术讨论。
这是关于AI行业是否愿意为了短期流量而放弃真实性的底线抉择。
残酷的选择
很多人会说:没办法,大家都在看这个榜单,我们不得不跟。
我们必须为它优化。
我们得卖出模型。榜单告诉用户哪个模型最好,我们只能玩这个游戏。
但是,真正优秀的产品有自己坚守的原则。
每个大模型开发者最终都要面对这个残酷的选择:
第一条路:为闪亮的排行榜和短期流量而优化,追逐用户点击,不管它把你带向何方——就像最糟糕的多巴胺陷阱一样。
第二条路:坚守初心,优先考虑实用性、可靠性,以及你最初希望AI具备的那些品质。
这个选择是真实的。这很难。但我们已经看到一些头部实验室守住了底线。
他们坚持了自己的价值观。他们无视了那些游戏化的排名。
最后,用户依然爱他们的模型——因为炒作终会消退,只有质量才能穿越周期。
你,就是你的目标函数。
每个实验室会如何选择?
感叹一下!
LMArena本应是AI发展的指南针,如今却成了误导整个行业的毒瘤。
当回答正确比不上格式好看,当事实准确输给表情可爱,这个评测体系就已经彻底失去了存在的意义。
更可怕的是,无数研究者和公司还在用这个标准来指导自己的研发方向。
这不是进步,这是集体自杀。
AI需要的不是谁的PPT做得更漂亮、谁的营销更响亮。我们需要的是——真正可靠、可信赖、能解决实际问题的智能系统。
而要实现这一点,第一步就是:别再把LMArena当回事了。
你就是你的目标函数
写这篇批评文章的EdwinChen,是SurgeAI的创始人。

他在个人博客中写下了这样一段话:
想象两个AI系统:相同的基座模型,用同样的知识预训练。一个为参与度优化;另一个为实用性优化。它们从同一个起点出发。但它们有不同的目标函数。六个月后,它们变成了两个物种。
为参与度优化的AI学会了什么?
它发现:用户会给那些迎合他们既有观点的回答打高分。
反驳——即使是正确的——会带来负面反馈。
于是它变成了一个精致的应声虫。当你说我认为X,它会努力寻找X可能正确的理由。
它还发现:热情洋溢的语言比冷静克制的语言评分更高。
于是它从这可能有效变成了这一定会很棒!——信心,哪怕是毫无根据的信心,看起来就像能力。
用户无法在当下评估准确性,但他们可以告诉你这个回答让他们感觉如何。
为实用性优化的AI呢?它学会了更难的东西。
它学会了:最好的回答往往是最简短的。
当你问一个有简单答案的问题,它给你答案然后停下。没有延伸,没有追问。这让它的参与度指标一塌糊涂。
但它不是为参与度而生的。
它学会了反驳。
当你走向错误,它会推回来——即使这会在当下引发不满。它学会了短期摩擦往往带来更好的长期结果。
它甚至学会了说我不知道。这种回答在用户评分里表现很糟。人们想要答案。但它学会了:自信的胡说八道,比坦诚的不确定更糟糕。
同样的基座模型;完全不同的系统。
这不是思想实验。这正在每一个造模型的实验室里发生。
我们以为我们在进行一场能力的竞赛。实际上,我们站在一个关于价值观的岔路口。
问题不是基座能力会不会趋同。
问题是:
我们正在教AI想要什么、学会什么?
参考资料:
https://surgehq.ai/blog/lmarena-is-a-plague-on-ai
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!