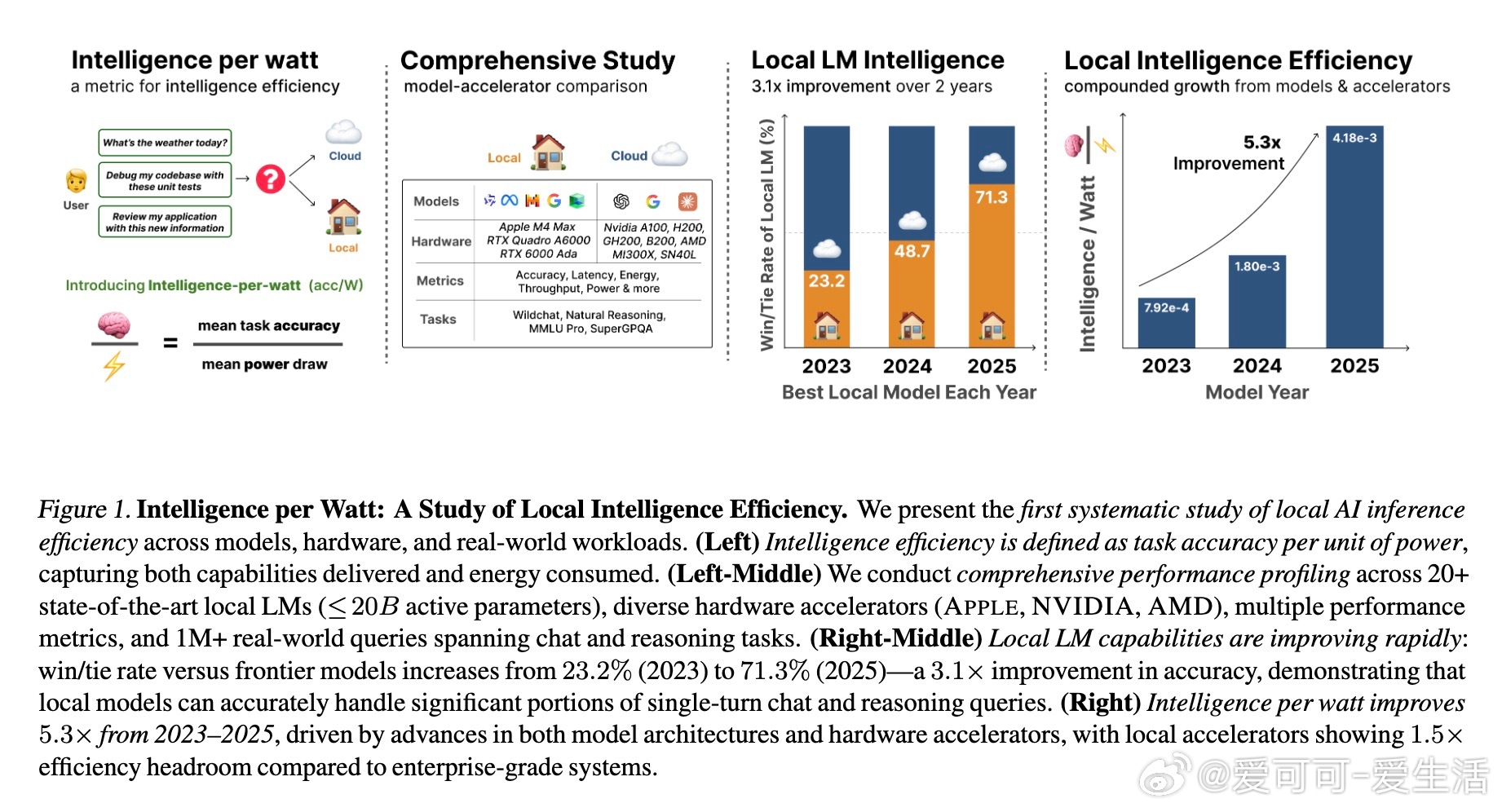
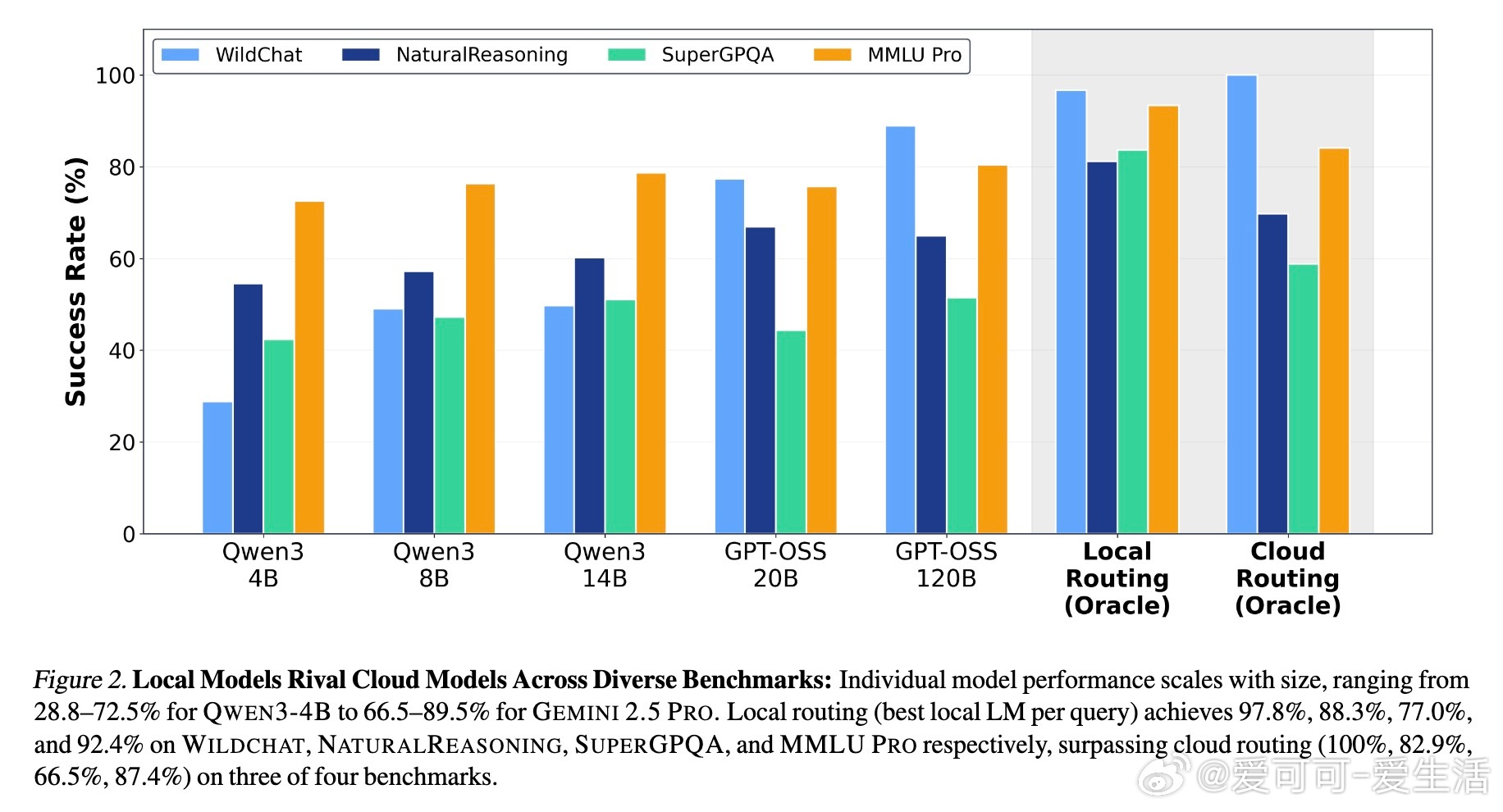
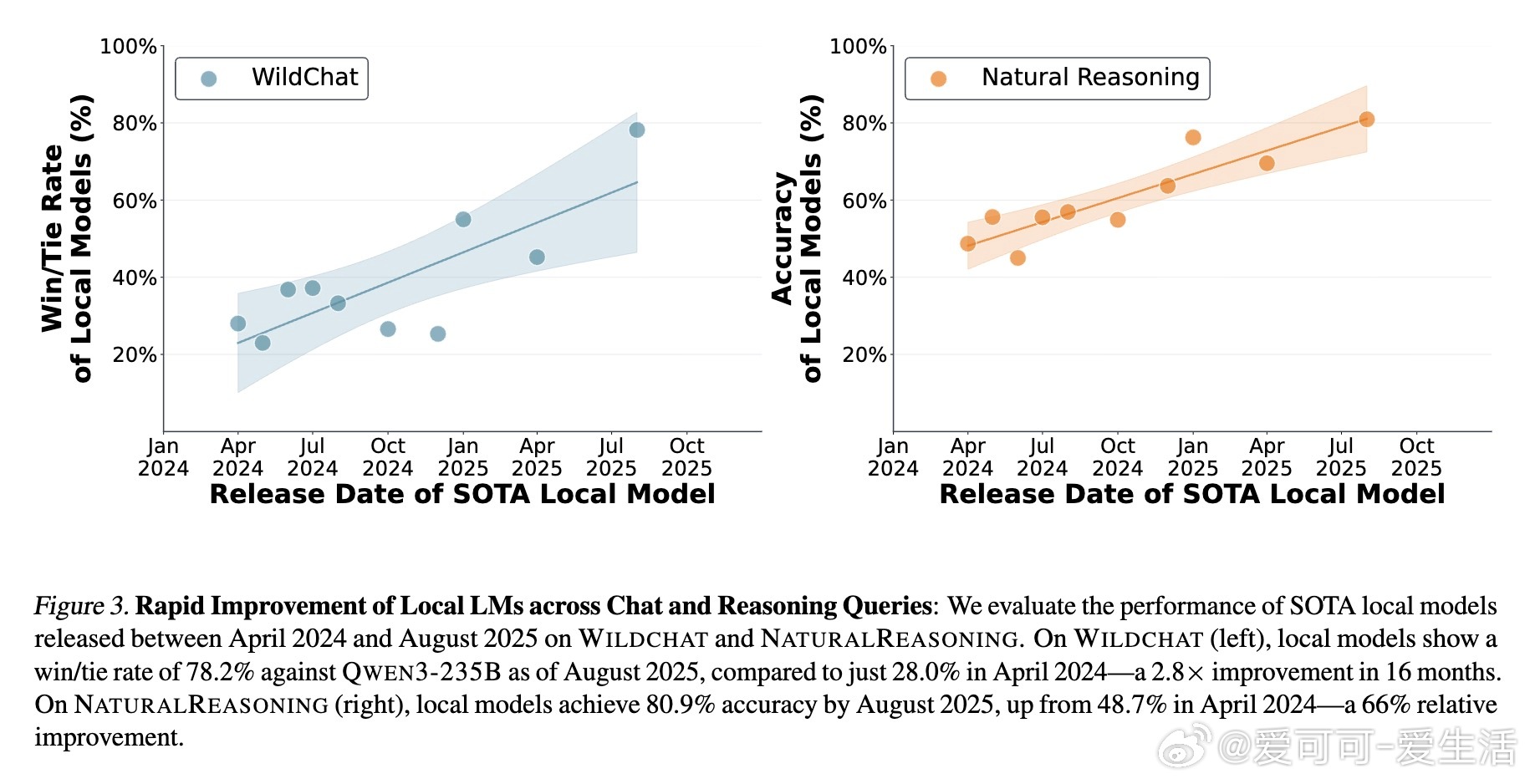
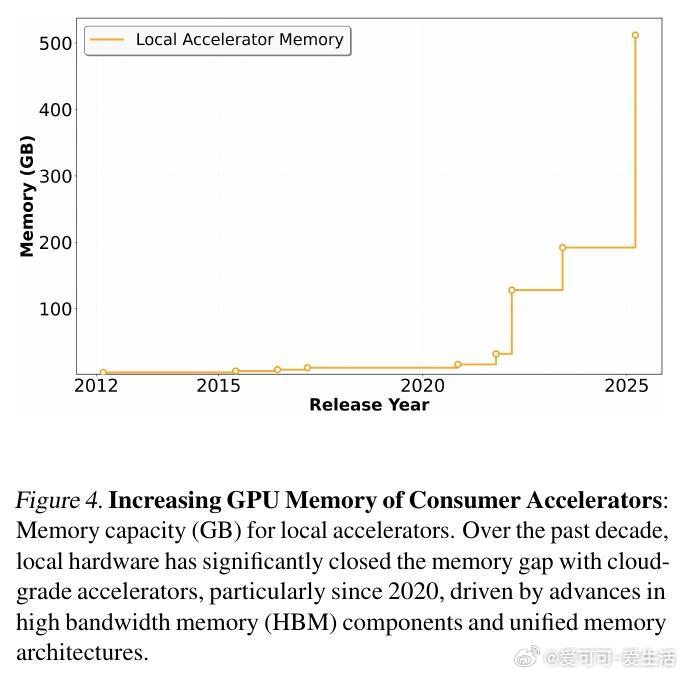
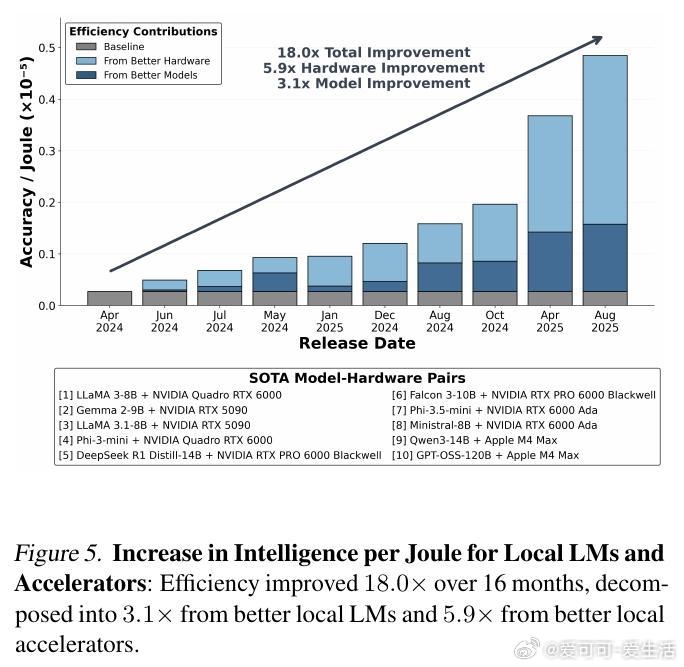
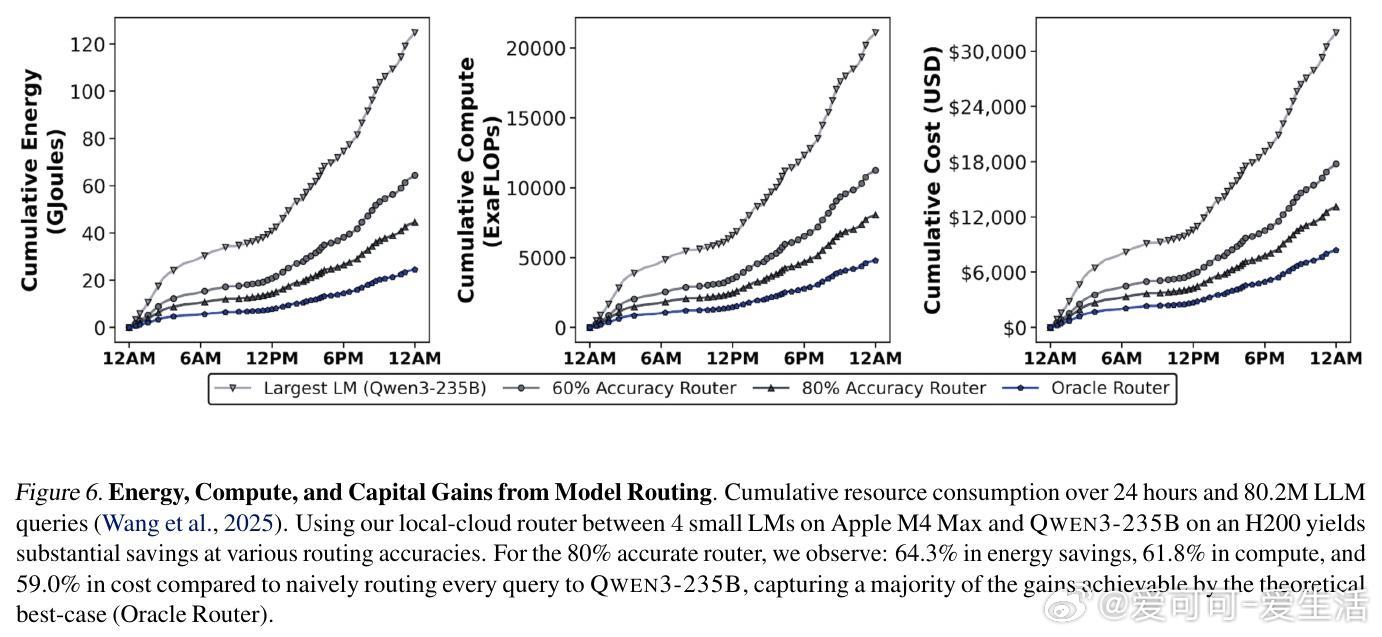
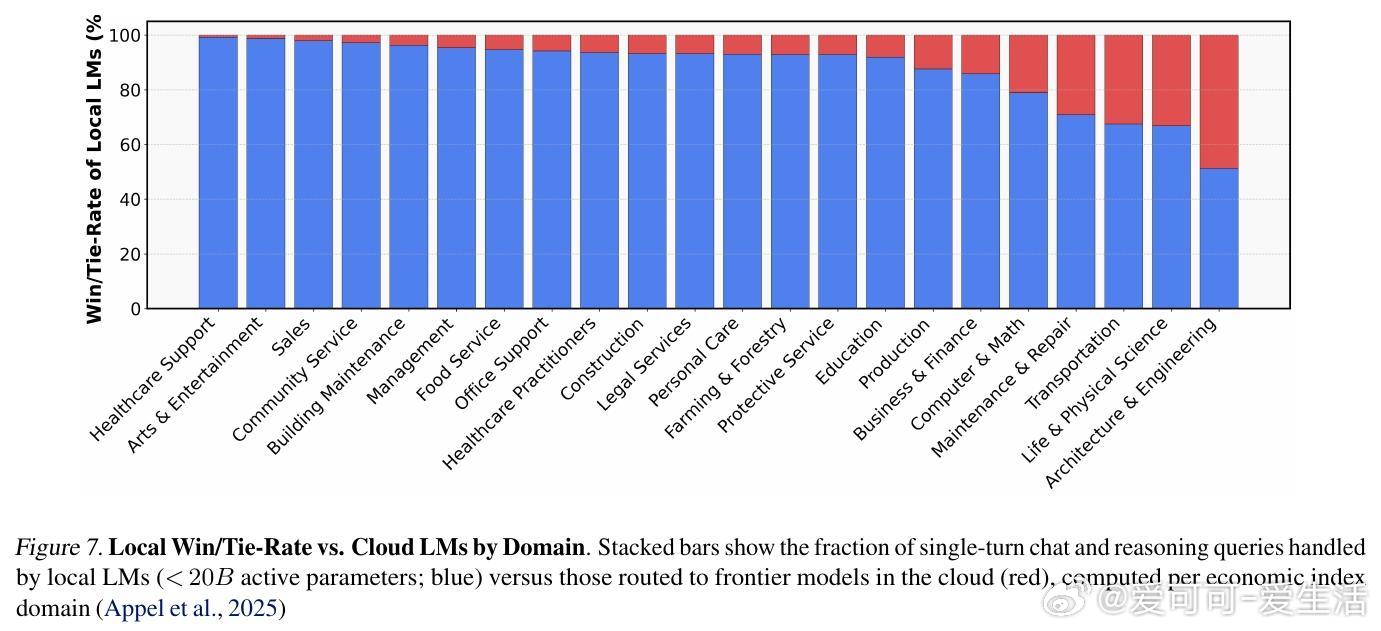
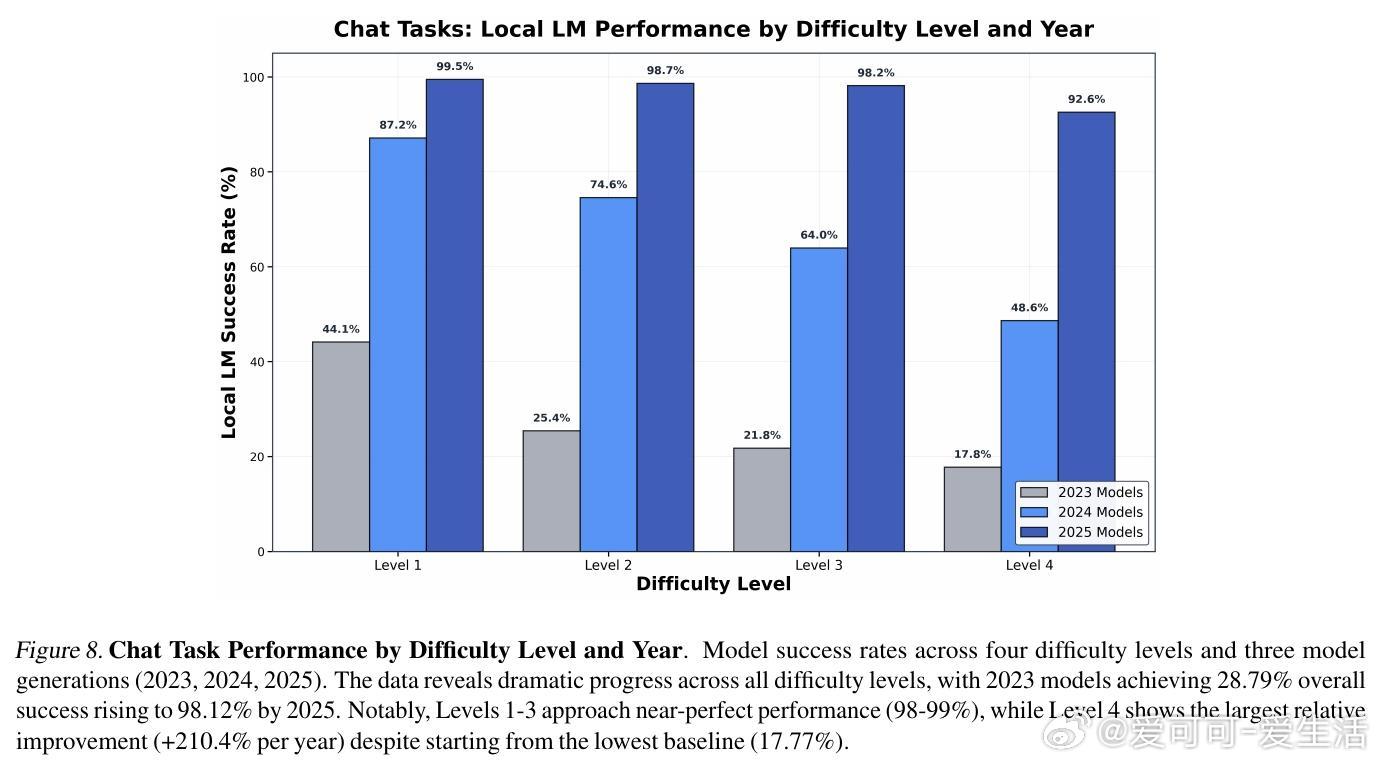
[LG]《Intelligence per Watt: Measuring Intelligence Efficiency of Local AI》J Saad-Falcon, A Narayan, H O Akengin, J. W Griffin... [Stanford University] (2025) 随着大语言模型(LLM)推理需求爆炸式增长,传统集中式云计算面临资源瓶颈,扩展难题日益突出。近期两大技术进步为本地推理带来曙光:一是参数规模不超过20B的小型本地语言模型(如Qwen3、Llama3.1、gpt-oss)已能在多任务上与云端前沿模型媲美;二是本地加速器(如Apple M4 Max、AMD Ryzen AI)具备运行这些模型的算力和内存,支持交互式时延。那么,本地推理能否有效分担集中式基础设施的压力?关键在于评估本地模型的回答准确率和在电源受限设备上的能效。本文提出“每瓦智能度”(Intelligence Per Watt, IPW)作为统一指标,衡量单位功率下模型的任务准确率,融合了能力与能效两大维度。通过对20余款本地模型、8种硬件加速器,以及超过100万条真实单轮对话和推理查询的实证分析,研究揭示:1. 2025年,本地模型能准确回答88.7%的单轮查询,覆盖面随领域不同而异。创意类任务(如艺术传媒)准确率超90%,而技术领域(建筑工程)则降至约68%。2. 2023至2025年间,IPW提升了5.3倍,得益于模型架构与硬件加速器的协同进步。本地服务的查询覆盖率也从23.2%飙升至71.3%,显示本地推理可处理越来越多实际需求。3. 本地加速器的IPW比云端加速器低约1.4倍,表明本地硬件仍有巨大优化空间。此外,智能路由机制能显著节省资源:即使路由准确率为80%,也可实现约60%的能耗、算力和成本节约,同时保持答案质量。这些发现表明,本地推理不仅是云计算的有效补充,更是推动AI基础设施可持续发展的关键。随着技术迭代,IPW将成为衡量本地推理转型进展的重要标尺。我们同时开源了IPW性能分析工具,支持社区持续基准测试,推动本地模型与硬件的协同优化。——详细报告请见:arxiv.org/abs/2511.07885