[RO]《ZTRS: Zero-Imitation End-to-end Autonomous Driving with Trajectory Scoring》Z Li, W Yao, Z Wang, X Sun... [Fudan University & NVIDIA] (2025)
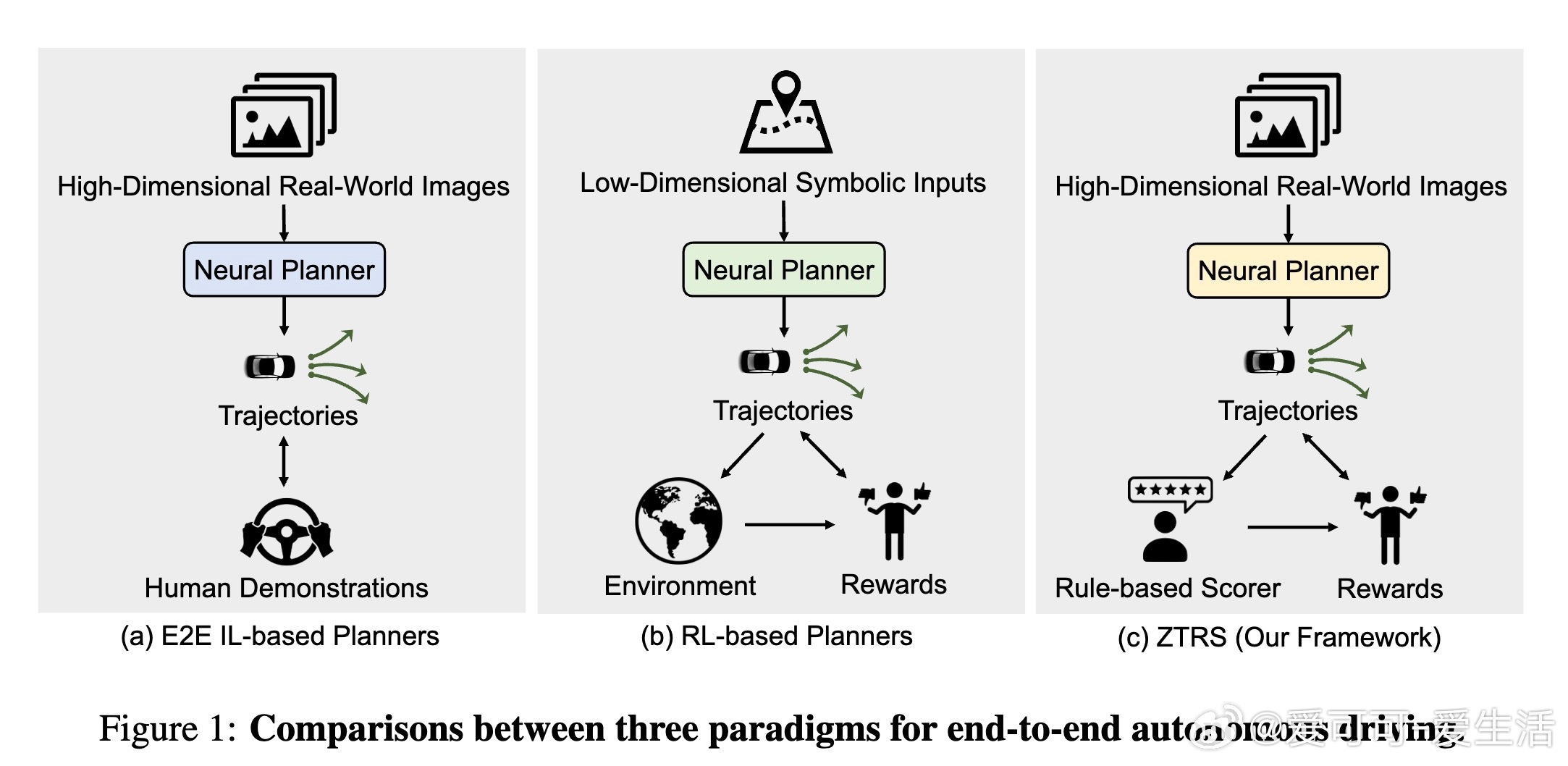
我们介绍了ZTRS(Zero-Imitation End-to-end Autonomous Driving with Trajectory Scoring),这是一种创新的端到端自动驾驶框架,首次完全摒弃了模仿学习(IL),仅基于奖励信号进行训练,并直接操作高维传感器数据,实现了从感知到规划的闭环。
传统的端到端自动驾驶多依赖IL,受限于专家示范的次优性及部署时的协变量偏移;而强化学习(RL)虽能利用仿真大规模训练,但多局限于低维符号输入,难以处理真实传感器数据。ZTRS融合两者优势,采用离线强化学习和我们提出的“穷尽策略优化”(Exhaustive Policy Optimization,EPO),针对离散轨迹动作空间,枚举所有候选轨迹并计算详细奖励,提供稠密监督,有效解决了RL冷启动难题。
核心技术包括:
1. 离线数据驱动:利用真实驾驶离线数据,避免昂贵且不安全的在线探索。
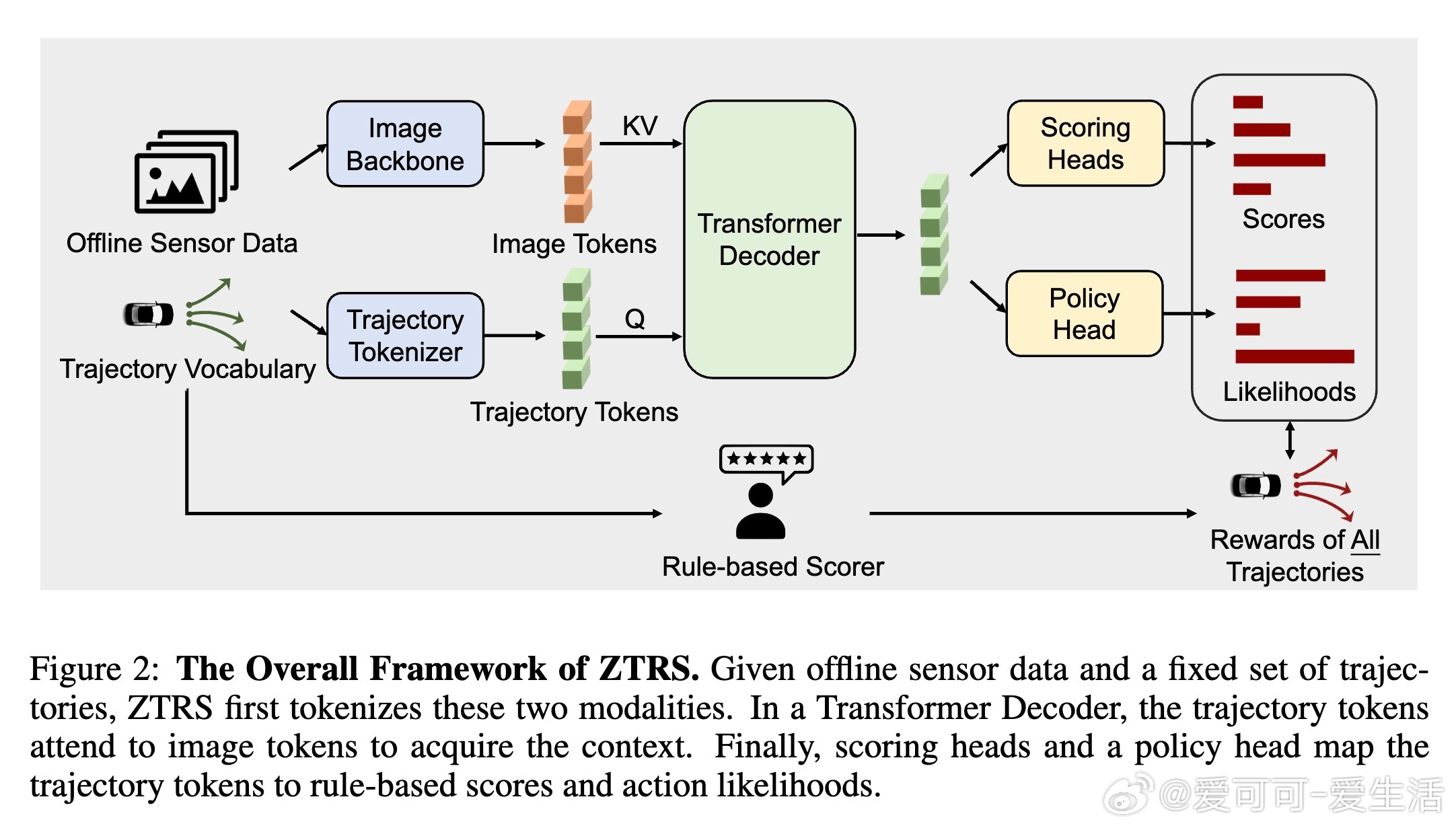
2. 轨迹评分机制:通过Transformer解码器融合图像与轨迹特征,预测多维规则评分(安全、合规、舒适等),作为奖励信号驱动训练。
3. EPO策略优化:基于策略梯度定理,直接对整个轨迹集合的概率分布进行优化,提升训练效率与稳定性。
在三个自动驾驶基准测试Navtest、Navhard和HUGSIM上,ZTRS表现优异:
- Navhard上达成行业领先的EPDMS评分,显著提升安全和舒适性指标。
- Navtest展示了优于多数IL方法的开环规划能力。
- HUGSIM中实现零样本迁移,超过传统IL基线,展现强大闭环驾驶能力。
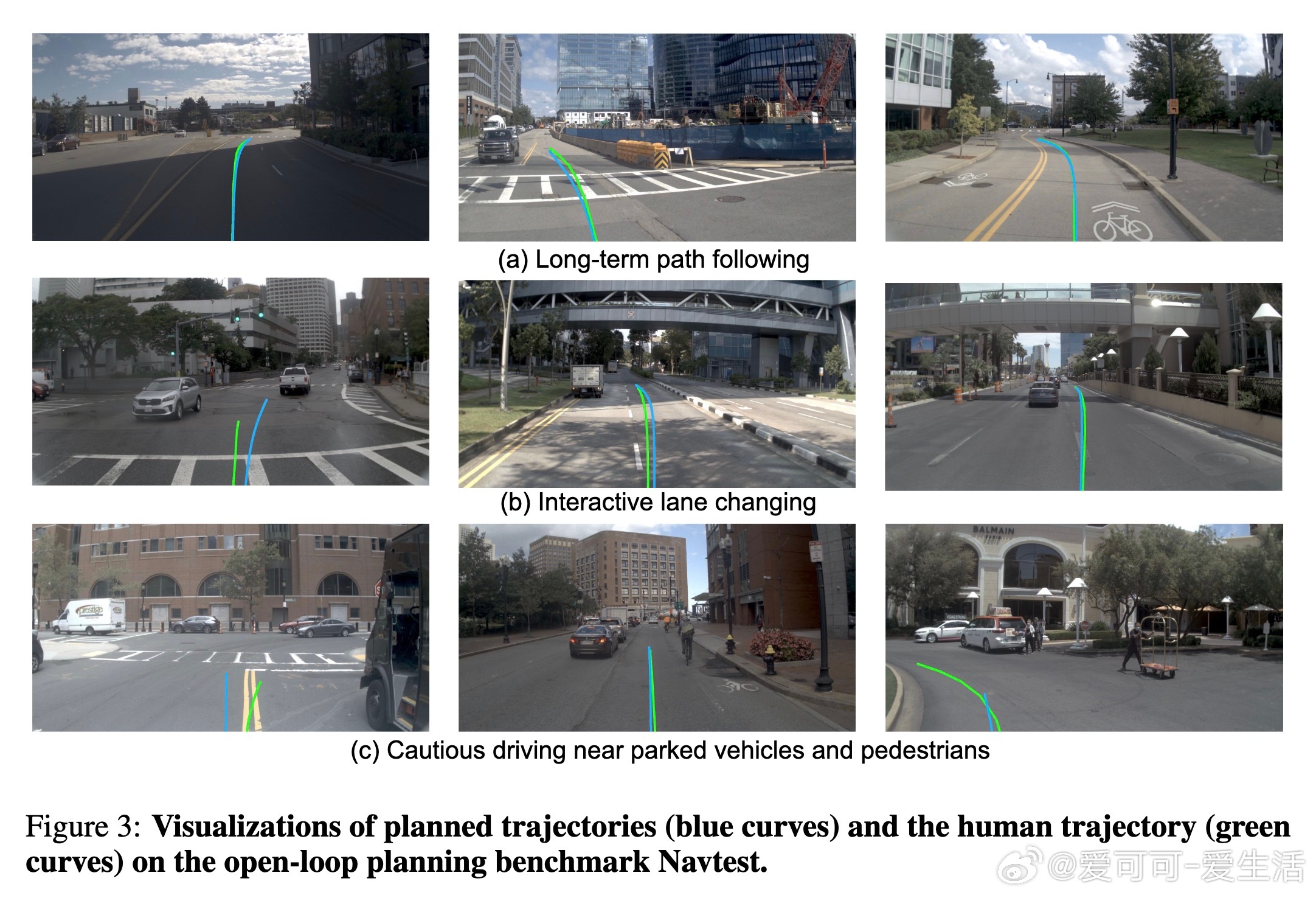
消融实验验证了奖励设计和EPO优化的重要性,强调了轨迹集合大小对训练和推理性能的影响。视觉化案例显示,ZTRS学会了类似人类的驾驶策略,并能安全应对复杂场景,无需人工示范辅助。
总结来看,ZTRS开创了端到端自动驾驶的新范式:摒弃模仿学习,纯粹依赖奖励驱动的离线强化学习,实现了对高维感知数据的直接规划。该方法突破了传统IL和RL的局限,迈出了自动驾驶技术向更安全、稳健和泛化能力强的方向发展的关键一步。
代码开源地址:github.com/woxihuanjiangguo/ZTRS
详细阅读请见: