[LG]《Search Self-play: Pushing the Frontier of Agent Capability without Supervision》H Lu, Y Wen, P Cheng, R Ding... [Quark LLM Team, Alibaba Group] (2025)
搜索自弈:无监督推动AI代理能力前沿
在AI代理训练领域,数据稀缺一直是瓶颈。传统强化学习(RLVR)依赖海量人工标注的任务和答案,成本高昂且难以扩展,尤其在多步决策的代理场景中。近期任务合成方法虽有尝试,但生成的代理任务难度难以动态控制,无法提供有效的RL训练优势。这让我思考:能否让AI代理“自娱自乐”,通过内部博弈自主生成高质量训练数据?
本文提出了一种创新方案:搜索自博弈(SSP)。SSP让LLM同时扮演“任务提出者”(Proposer)和“问题求解者”(Solver)两个角色,利用多轮搜索引擎调用,构建一个零和对抗游戏。提出者生成难度递增的深度搜索查询,确保有明确的事实答案;求解者则通过多轮推理和搜索尝试正确回答。通过竞争(提出者试图“难倒”求解者)和合作(RAG验证确保查询正确性),两者共同进化,提升搜索、推理和自我验证能力。这不仅消除了人工标注需求,还实现了自监督训练的规模化。
>SSP的核心机制
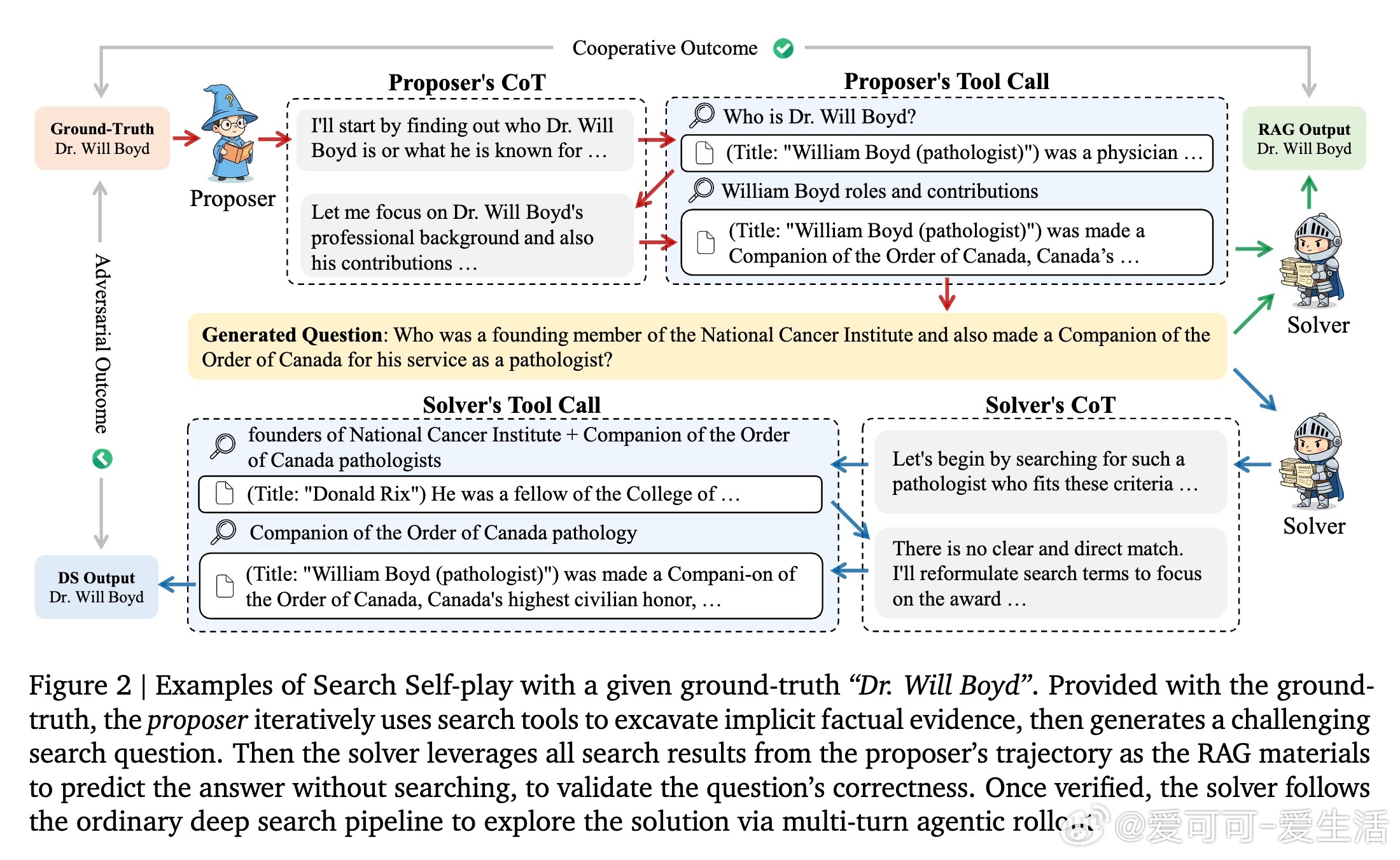
1. 游戏设计:从预定义答案集D采样真实答案a*。提出者基于a*生成查询q,通过多轮搜索挖掘隐含事实,形成逻辑链条(例如,从关联概念逆向构建,需要n步搜索才能解出)。求解者则模拟人类调查过程:动态重构查询、多跳推理和工具调用,输出预测答案A。
2. 验证与奖励:为防“作弊”(提出者生成无效查询),SSP收集提出者轨迹的所有搜索结果作为RAG文档,让求解者在无搜索条件下验证答案正确性(r(A, a*) = 1)。这引入合作机制:只有可靠证据支持的查询才通过过滤。同时,添加少量噪声文档(实验显示4个最佳)防止提出者生成“RAG易解但搜索难”的陷阱问题,确保查询鲁棒。
3. 优化过程:使用拒绝采样过滤无效查询。求解者采用GRPO(组相对策略优化)最大化成功率;提出者用REINFORCE最小化求解者成功率(奖励=1-平均成功率)。整体目标:min_u max_v E[r(A(ρ), a*)],约束RAG验证=1。训练中,提出者难度自适应调整(基于胜率),形成动态课程,避免过拟合。
这种设计巧妙融合AlphaGo Zero的自博弈思想与代理工具交互,突破LLM内部知识局限。不同于传统自博弈(局限于数学/代码),SSP利用外部搜索工具,确保生成的查询真实且可验证,适用于复杂信息检索场景,如科学文献综述或事实核查。
>实验洞见与性能提升
团队在7个基准(NQ、TriviaQA、PopQA、HotpotQA、2Wiki、MuSiQue、Bamboogle)上评估SSP,使用Wiki-2018语料库和E5检索器。结果令人振奋(pass
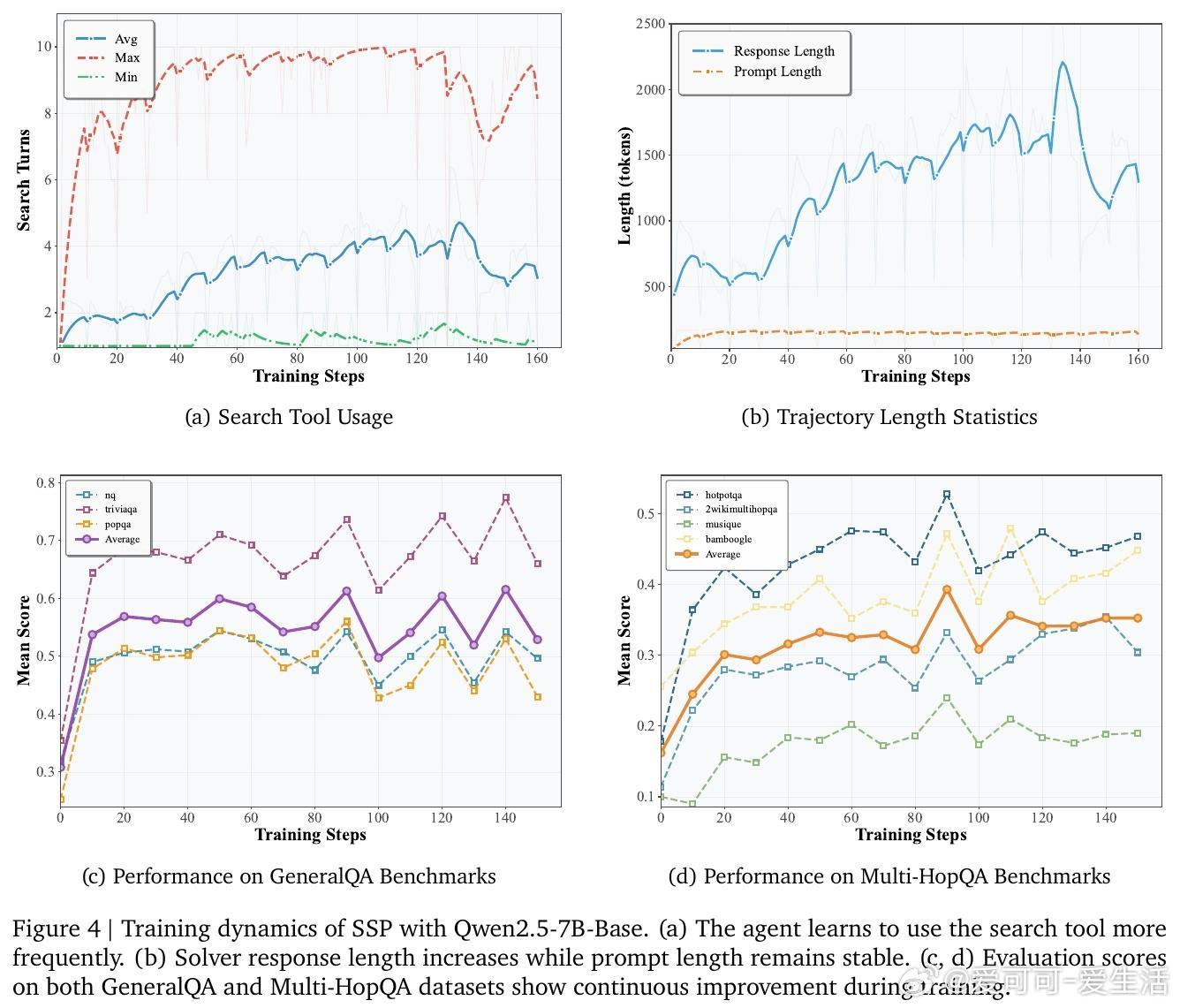
- 从零训练:在Qwen2.5-7B-Base上,SSP平均提升26.4分(TriviaQA +40.4);Instruct版提升8.0分。证明SSP能从基础模型中挖掘代理潜力。
- 泛化性:跨LLaMA-3.1和Qwen3,提升9.6和3.8分,显示模型无关。
- 持续训练:在Search-R1-7B等专业代理上,进一步提升1.8-2.3分,即使基线已优化。
- 规模扩展:Qwen2.5-32B-Instruct上,SSP在5/7基准达SOTA,平均+3.4分。
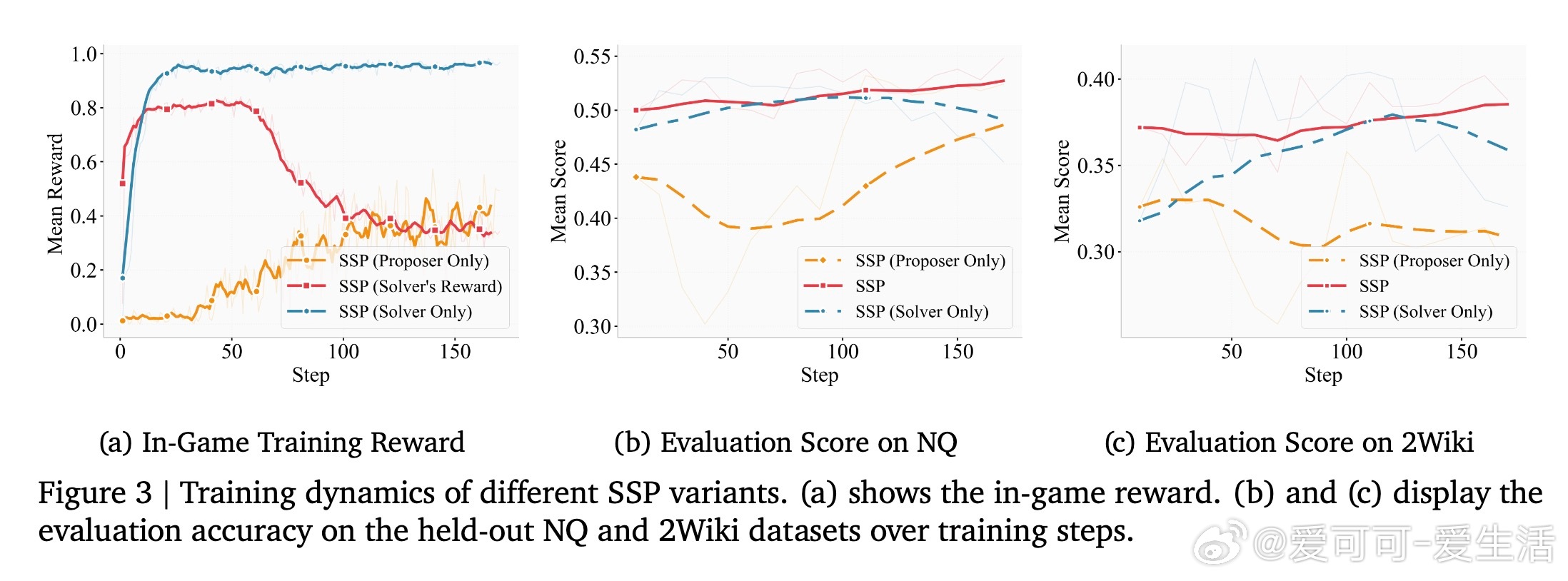
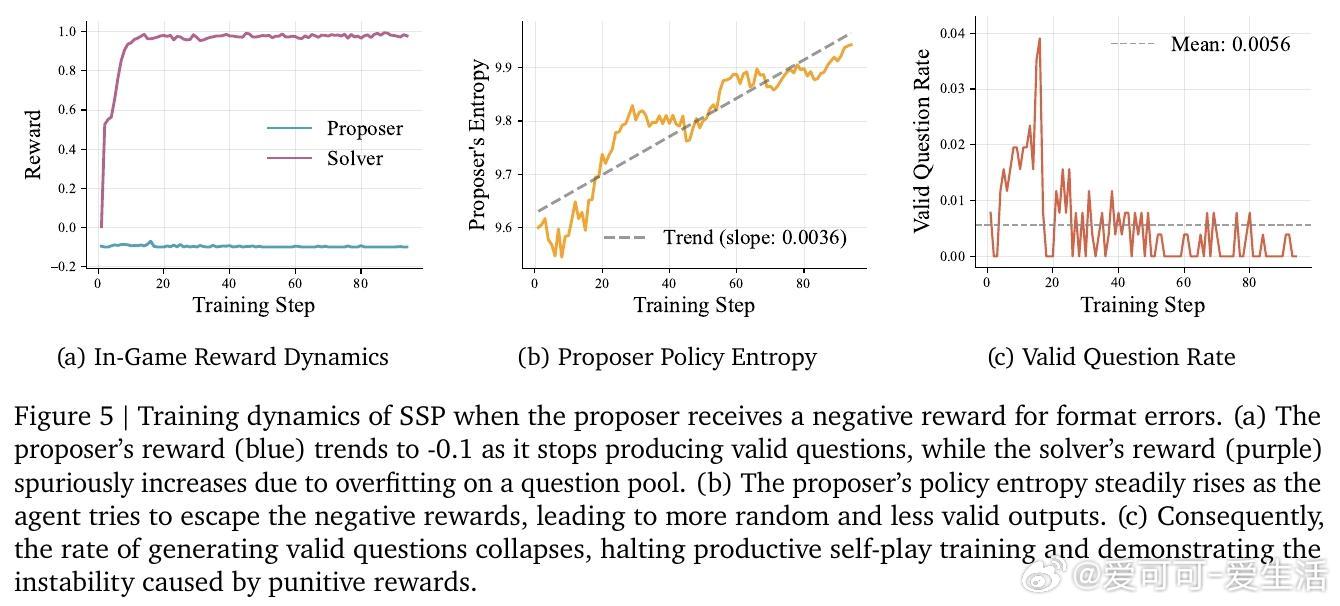
消融实验强调共进化关键:仅训求解者(Solver-Only)导致过拟合,奖励饱和;仅训提出者(Proposer-Only)泛化差。完整SSP动态调整难度,训练中搜索调用次数和响应长度持续增长,性能稳定上升。RAG验证不可或缺,无它准确率降至36.7;噪声优化防“黑客”问题(如非唯一答案查询)。此外,RL算法对比显示REINFORCE+GRPO最佳,平衡效率与效果。
这些结果让我反思:SSP不仅是技术突破,更是AI自驱动范式的典范。它减少了对人类监督的依赖,推动代理训练向可持续方向演进。未来,可扩展到GUI或代码代理,助力更智能的AI系统。代码开源:。
原论文链接:arxiv.org/abs/2510.18821