[LG]《Glyph: Scaling Context Windows via Visual-Text Compression》J Cheng, Y Liu, X Zhang, Y Fei, W Hong... [Tsinghua University & Zhipu AI] (2025)
Glyph:通过视觉-文本压缩扩展上下文窗口
在AI时代,大语言模型(LLM)在文档理解、代码分析和多步推理等任务中越来越依赖长上下文建模。但将上下文窗口扩展到百万token级别,会带来巨大的计算和内存开销,限制了实际应用。本文提出了一种创新范式:不直接延长token序列,而是将长文本渲染成紧凑图像,由视觉-语言模型(VLM)处理。这不仅压缩了输入,还保留了语义完整性,值得AI从业者和研究者关注。
>核心挑战与创新思路
传统LLM扩展长上下文的方法主要有三类:位置编码延长(如YaRN),注意力机制优化(如稀疏注意力),或检索增强生成(RAG)。这些方法虽有效,但仍面临二次方复杂度、推理加速不足或信息丢失的风险。Glyph则换个角度——“视觉上下文扩展”。它将纯文本渲染为图像,每个视觉token承载多个文本token的信息,从而提高密度而不牺牲保真度。
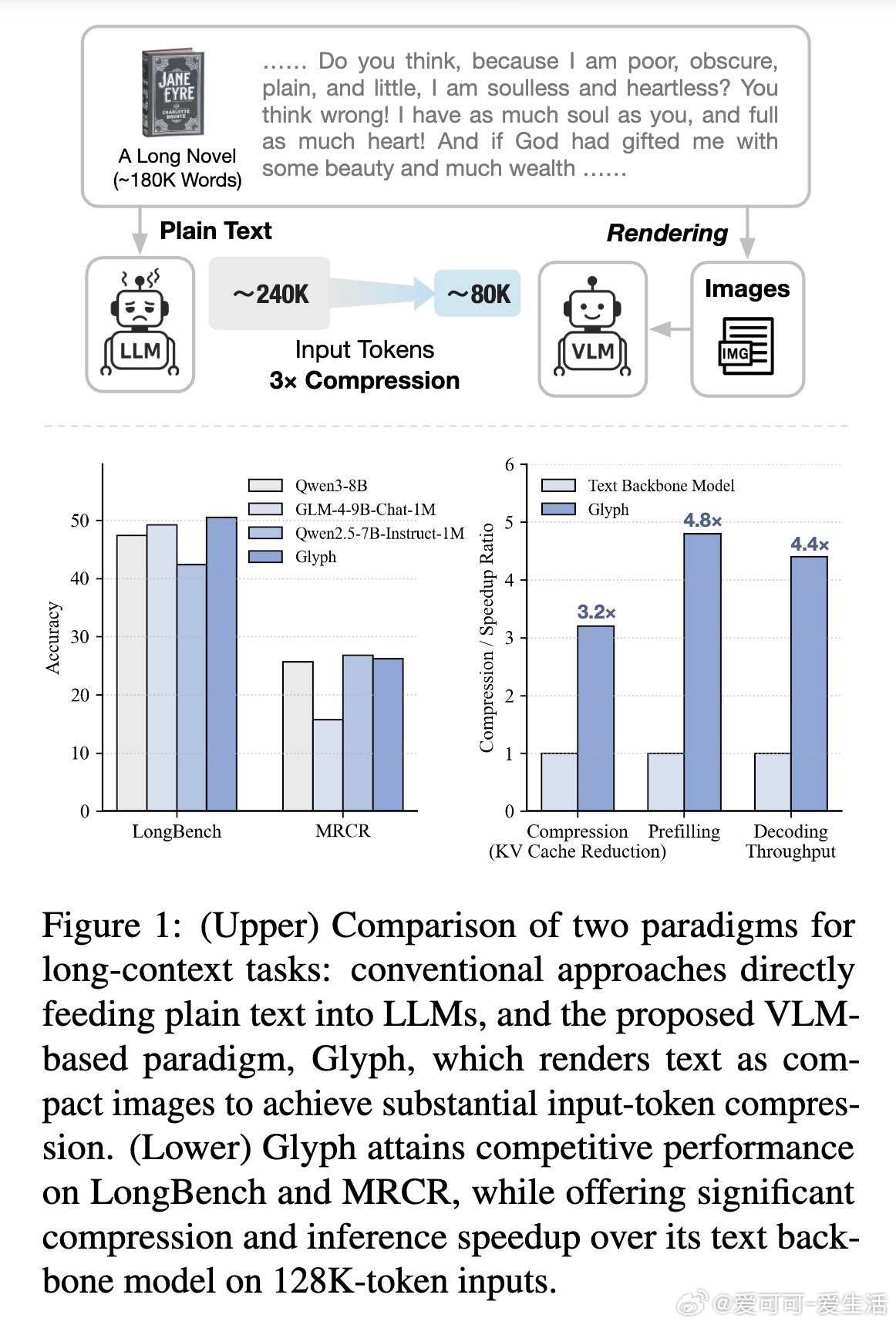
例如,经典小说《简·爱》(约24万文本token)无法完整输入128K上下文的LLM,容易因截断导致全局问题(如“谁在简离开桑菲尔德后支持她?”)回答错误。Glyph将其渲染成约8万视觉token的图像,128K VLM即可全书处理,准确回答问题。这本质上是“字形”表示,让VLM像阅读书籍一样高效解析长文本。
这种方法与现有技术正交,可结合使用,进一步降低成本。思考一下:在资源有限的边缘设备上,这能让长上下文任务更普适化,推动AI从实验室走向现实。
>Glyph框架详解
Glyph由三个紧密耦合阶段构建,确保从预训练到优化的全链路高效:
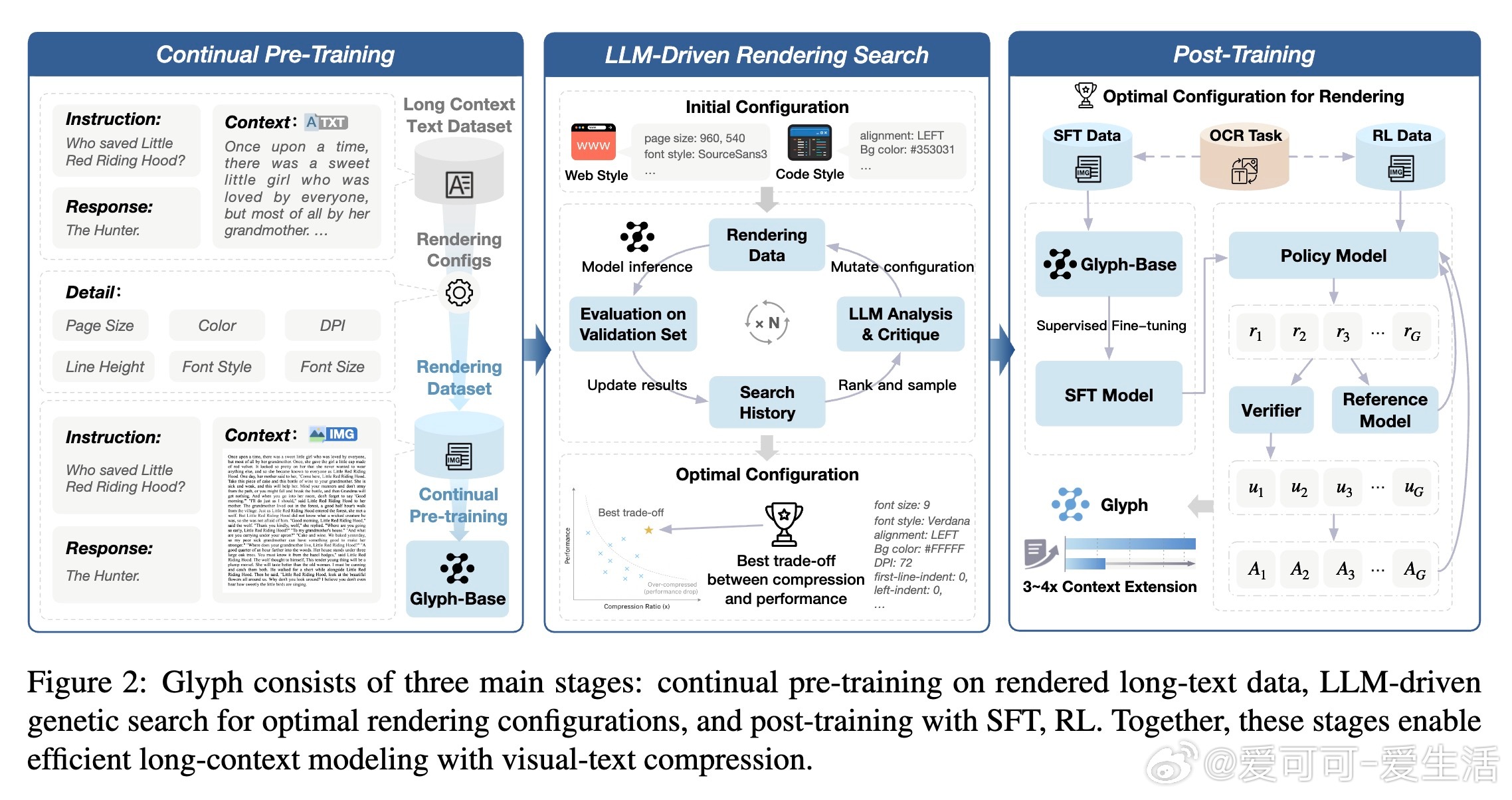
1. 持续预训练(Continual Pre-Training)
使用大规模长上下文文本数据集,渲染成多样视觉形式(如文档风格、网络风格、暗黑模式、代码风格)。引入三种任务:OCR任务(重建渲染页文本)、交错语言建模(文本与图像混合输入)、生成任务(补全部分渲染页)。这转移了LLM的长上下文能力到VLM,模型初始化自GLM-4.1V-9B-Base,训练4000步,批次大小170,学习率2e-6。
关键:多样渲染提升鲁棒性,避免单一风格偏差。通过规则过滤无效配置(如行高小于字体),并融入人类先验主题,确保视觉与文本语义对齐。
2. LLM驱动的遗传搜索(LLM-Driven Rendering Search)
渲染参数(如DPI、分辨率、字体大小、布局、颜色)直接影响压缩率与性能权衡。Glyph用遗传算法自动化探索:从初始种群采样配置,迭代渲染验证集、模型推理评估准确率与压缩比(ρ(θ) = 文本token / 视觉token),LLM分析历史建议变异/交叉,直至收敛(5轮,每轮200步)。
这比手动调参高效得多,确保最佳θ*(如DPI=72,压缩率3-4倍)。深入看,这体现了AI自治优化:LLM不只生成文本,还指导渲染,展示了多模态协作的潜力。
3. 后训练(Post-Training)
固定最优配置,进行监督微调(SFT,1.5K步,学习率5e-6衰减到2e-6)和强化学习(RL,使用GRPO算法,500迭代,采样16响应/组)。SFT采用思考式格式(...),鼓励步步推理;RL整合LLM评判奖励(准确+格式)和Levenshtein距离OCR奖励。辅助OCR任务贯穿全程,提升细粒度文本识别。
结果:Glyph-Base经优化后,长上下文推理更稳健,低级文本恢复更准。
整个框架见论文图2,清晰展示从文本到图像的管道。值得一提的是,渲染参数详尽(如表8:DPI混合采样、字体家族去重),支持自定义调整。
>实验验证与性能亮点
论文在LongBench、MRCR、Ruler等基准上全面评估,与Qwen3-8B、LLaMA-3.1-8B等同规模LLM比较:
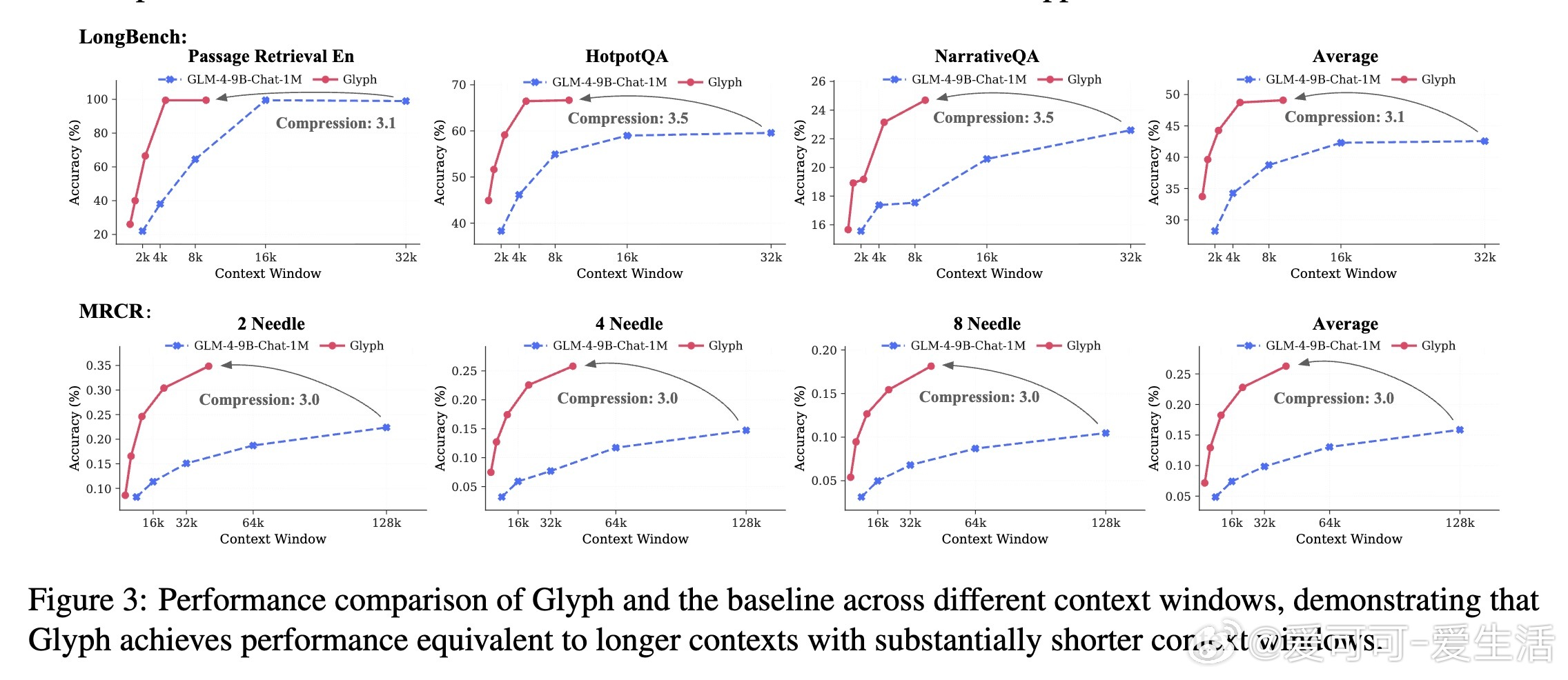
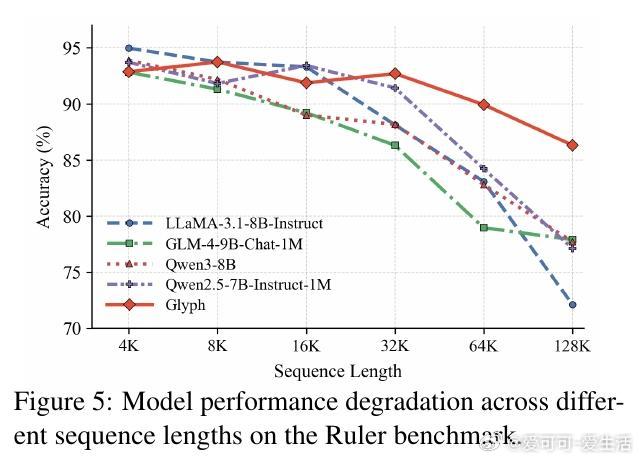
- 长上下文理解:Glyph平均准确率达50.56%(LongBench),26.27%(MRCR),72.17%(Ruler),与SOTA相当。压缩比3-4倍:在128K token下,相当于处理原3倍文本(如MRCR 8-needle子任务,Glyph 18.14% vs. GPT-4o 23.4%,但效率更高)。图3显示,随着上下文增长,Glyph性能衰减更慢——32K到64K扩展,实际获益96K原文本。
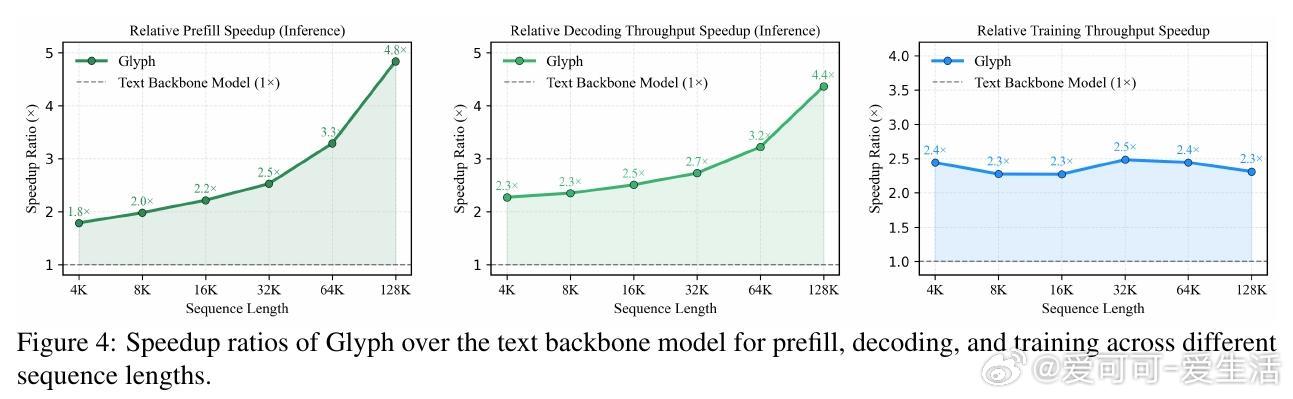
- 效率提升:图4量化加速:预填充4.8倍、解码4.4倍、SFT训练2倍。内存节省约67%(KV缓存线性缩减)。极端压缩下(8倍),128K VLM处理1M token,MRCR性能持平Qwen2.5-1M。
- 跨模态泛化:虽训练主用渲染文本,Glyph在MMLongBench-Doc(长PDF文档理解)上F1达46.32%,超基线14%。这表明渲染数据增强了真实多模态任务,如跨页问答。
消融实验(表5-7)证实:搜索配置优于随机/手动(平均+4.69%);OCR任务贡献大(移除后掉8.12%);RL不可或缺(移除掉7.11%)。极端8倍压缩实验显示潜力:可扩展到4M-8M token。
>局限与未来展望
Glyph虽创新,但对渲染参数敏感(如分辨率变化影响性能),UUID等稀疏OCR挑战仍存,任务多样性需扩展(当前偏理解,少代理/推理)。未来,可开发自适应渲染(依任务动态调整)、增强视觉编码器、知识蒸馏对齐文本模型,或应用于代理记忆系统/上下文工程,实现1M到10M token跃升。这不仅是压缩,更是重塑上下文表示的范式转变。
总之,Glyph证明了视觉-文本压缩是扩展长上下文的低成本路径,结合VLM的OCR天赋,开启高效AI新篇章。代码模型开源:。欢迎讨论,你如何看待这种“图像化”文本的思路?
原论文链接:arxiv.org/abs/2510.17800