《From Masks to Worlds: A Hitchhiker's Guide to World Models》
从掩码到世界:构建世界模型的指南
在AI领域,“世界模型”听起来遥远而迷人,但真正构建它并非天马行空,而是沿着一条清晰路径前行。这篇论文不是泛泛的综述,而是献给想亲手创造世界的你。它聚焦核心:从早期掩码模型统一多模态表示学习,到统一架构共享单一范式,再到交互生成模型闭合行动-感知循环,最终到记忆增强系统维持长期一致的世界。我们绕开枝蔓,直击本质——生成心脏、交互循环与记忆系统。这条“狭窄之路”是最有前景的通往真正世界模型的捷径。
>什么是真正世界模型?
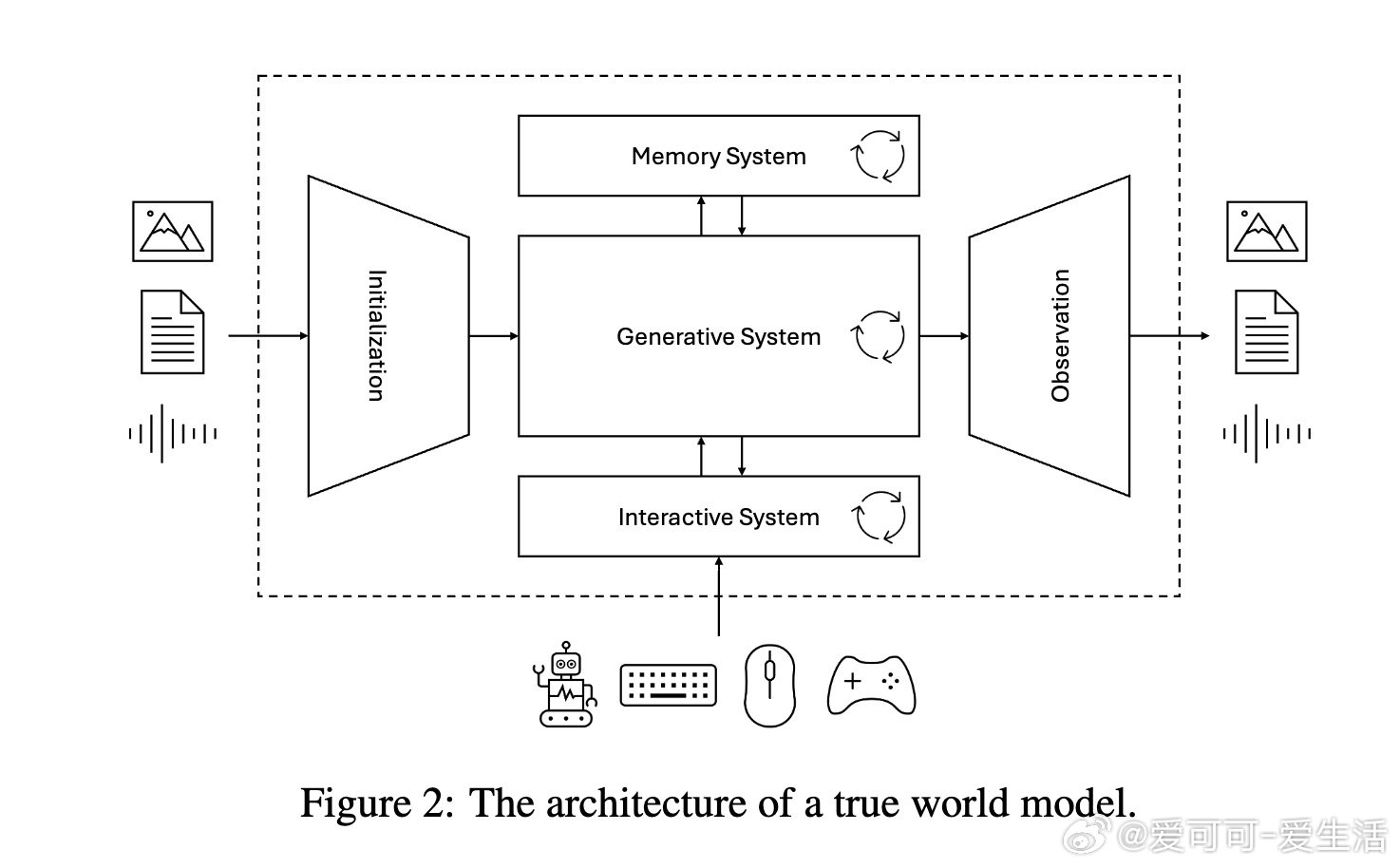
世界模型不是单一实体,而是三个子系统的合成体(见图2架构):
- 生成心脏(G):世界动态的核心,预测未来状态、观察、奖励与终止(如pθ(zt+1 | zt, at))。它像心脏般泵送世界状态,确保生成真实而连贯。
- 交互循环(F, C):闭合实时行动-感知循环,包括状态推理qϕ(zt | ht-1, ot)、策略πη(at | zt, ht)和价值函数vω(zt, ht)。这让模型从被动生成转向主动响应,实现真正互动。
- 记忆系统(M):ht = fψ(ht-1, zt, at-1),通过递归状态维持长期连贯,避免遗忘。
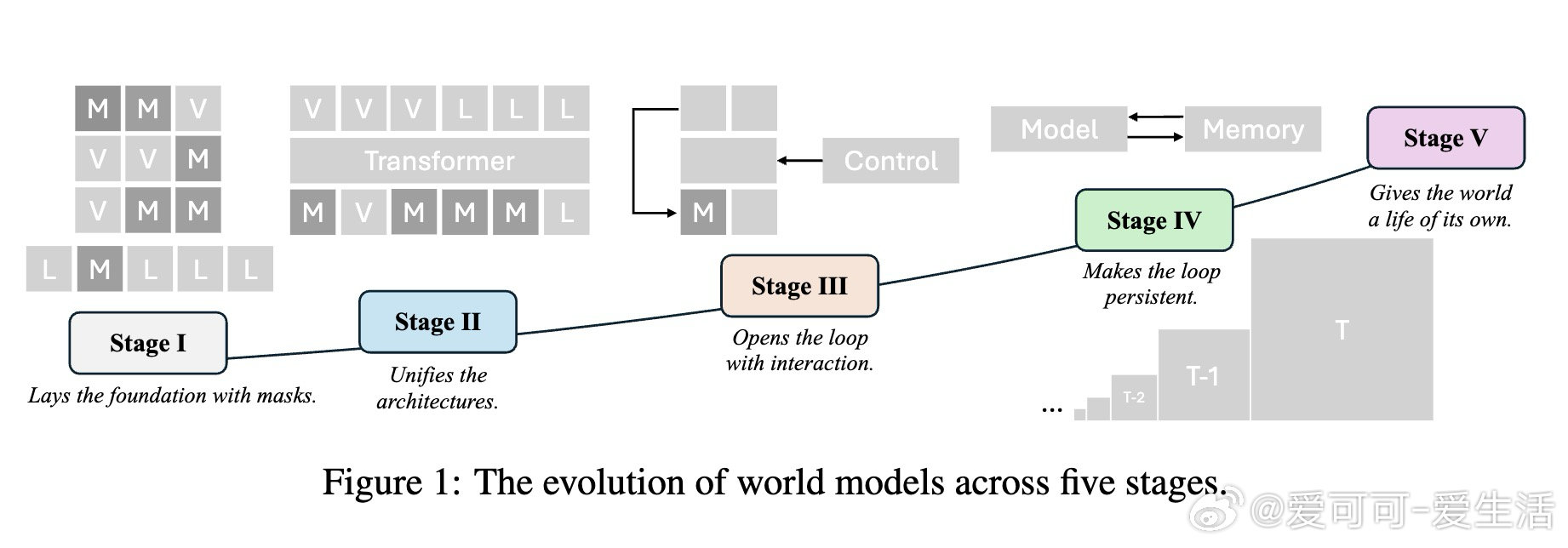
这些子系统源于强化学习(如Dreamer, 2019)和生成AI(如Genie系列, 2024-2025)的演进。今天,许多工作优化窄任务,却忽略了生成、交互与持久性的本质。论文将历史划分为五阶段(见图1),从孤立组件到自主整体,揭示从预测引擎到“活世界”的跃迁。这提醒我们:规模化不是万能,系统整合才是关键——它能激发持久性、能动性和涌现性,而非简单堆砌参数。
>第一阶段:掩码模型——跨模态基础
一切从“掩码、填充、泛化”范式开始。这统一了token化、表示和预训练,奠定多模态基石。尽管模型仍专一于模态,但它证明掩码是通用自监督学习利器。
- 语言:BERT (2019)用双向掩码预测15% token,SpanBERT (2020)掩码连续片段提升推理。T5/BART (2020)转为去噪自编码,ELECTRA (2020)用替换检测提效。非自回归演进如RoBERTa (2019)的动态掩码,到离散扩散模型(Li et al., 2022),工业如Gemini Diffusion (2025)媲美自回归速度与质量。
- 视觉:BEiT/MAE (2021-2022)掩码图像块学强大特征,MaskGIT/MUSE (2022-2023)并行填充高效合成图像,Meissonic (2024)实现高保真文本到图像。视频扩展如VideoMAE (2022)捕捉时空动态。
- 其他模态:音频的wav2vec 2.0 (2020)、3D的Point-MAE (2023)、图的GraphMAE (2022),证实掩码的普适性。
思考:这一阶段统一了学习范式,却暴露模态孤岛问题。想象如果早期就跨模态,它将加速世界构建——这推动第二阶段的统一。
>第二阶段:统一模型——单一架构多模态
从专才到通才:单一骨干与范式处理生成多模态,简化缩放、启用跨模态转移。这是通往世界模型的首次合成,但仍缺实时交互。
代表作(表1)分三轨:
- 语言优先:从BLIP-2/LLaVA (2023)连接视觉编码器到LLM,到EMU3/Chameleon (2024)的端到端自回归统一文本/图像/视频。掩码分支如MMaDA/Lavida-O/Lumina-DiMOO (2025),用离散去噪统一推理与生成。
- 视觉优先:UniDiffuser (2023)联合扩散文本/图像,Muddit/UniDisc (2025)基于MIM的离散扩散。
- 工业规模:Gemini/GPT-4o (2024-2025)单系统多模态,虽非单范式,但证明统一已成主流。
益处与缺口:减少碎片,涌现跨模态能力(如Gemini的对话)。但视觉优先模型限于单次合成,语言优先虽互动,却无闭环实时。见解:统一如拼图,桥接模态却未活化世界——这需第三阶段的交互来点燃。
>第三阶段:交互生成模型——闭合循环
模型从静态生成转向实时参与:输出条件于流式输入/行动,内部状态支持低延迟响应。架构无关,聚焦语言、视频、场景三域。
- 语言世界:从经典交互小说(TextWorld, 2018)到AI Dungeon (2024),LLM驱动开放叙事,用户提示生成无限分支。从解决静态谜题到共同创作,预示个性化视觉小说。
- 视频/场景世界:GameGAN (2020)神经游戏引擎,PVG/PE/PGM (2021-2024)从步进行动到语义控制。Genie系列巅峰:Genie-1 (2024) 2D控制,Genie-2 (2024) 准3D图像初始化,Genie-3 (2025) 720p/24fps多分钟连贯。开源如Oasis/GameNGen/Mineworld (2024-2025)实时3D物理,World Labs (2024)单图生成可探索3D。
- 挑战:长期一致性难。隐式帧生成灵活但易漂移(Genie-1仅16帧),显式3D稳定但动态弱。见解:交互如心跳,赋予生命却易疲惫——无记忆,世界如昙花一现,需第四阶段持久化。
>第四阶段:记忆与一致性——持久世界
无记忆的行动是反应而健忘。这一阶段解答:记忆锚定何处?如何扩展?如何调控一致?
- 外部记忆:从Neural Turing Machines (2014)到RAG/RETRO (2020-2022)的检索,MemGPT (2023)虚拟内存管理,LONGMEM (2023)扩展KV缓存。转向动态,如From RAG to Memory (2025)的持续学习。
- 容量扩展:Transformer内改革如Transformer-XL/Compressive (2019)、Infini-attention (2024)递归压缩;革命如Mamba/S4 (2023)线性状态空间无限上下文;实用如LongNet/Ring Attention (2023)亿级扩展。
- 一致调控:隐式视频防遗忘/漂移(FramePack/MoC, 2025);显式3D动态记忆(VMem, 2025)。见解:记忆非存储,而是纪律——规模或解数据瓶颈(如短视频),但工程政策(如何时遗忘)决定是否从“梦”到“忆”。
工业如Gemini/Claude (2024-2025)百万token多模态,耦合推理与代理。
第五阶段:真正世界模型——涌现生命
非新增组件,而是前四阶段合成:自主生态,涌现持久性(独立历史)、能动性(多代理社会)、涌现性(微观交互生宏观动态)。
三大挑战:
- 连贯问题:自生成世界无外部真相,如何度量内部逻辑/因果一致?
- 压缩问题:历史膨胀致计算崩,如何学因果抽象,逼近信息论界?
- 对齐问题:底层法则对齐人类价值,更难的是涌现多代理动态的安全。
愿景:从模拟器到科学仪器,实验现实不可及的复杂系统(如经济/文化)。深刻思考:构建世界非逃避,而是镜像自我——规模解锁涌现,但需伦理对齐,避免失控生态。这条路考验我们:娱乐工具抑或理解工具?
论文结论:远离静态基准,拥抱生成-交互-记忆整合。未来,我们锻造的不仅是模型,更是洞察复杂性的镜子。强烈推荐阅读,启发构建者前行。
原论文链接:arxiv.org/abs/2510.20668