[LG]《Ask a Strong LLM Judge when Your Reward Model is Uncertain》Z Xu, Q Lu, Q Zhang, L Qiu... [Georgia Institute of Technology & Amazon] (2025)
基于不确定性的路由框架:提升RLHF中奖励模型的泛化能力
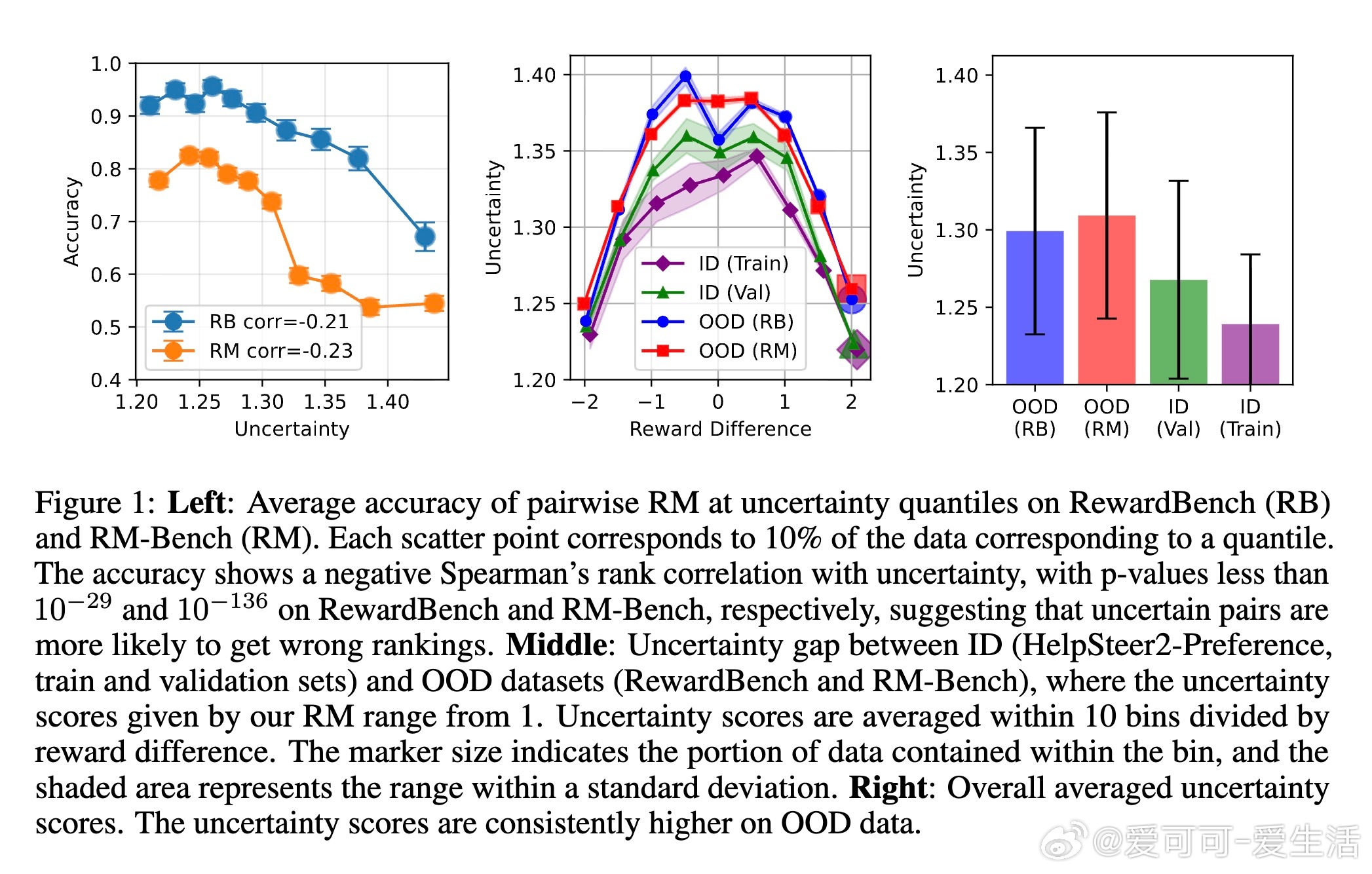
在大型语言模型(LLM)对齐中,强化学习人类反馈(RLHF)是关键方法,通过奖励模型(RM)捕捉人类偏好来优化模型。然而,传统RM基于有限的人类偏好数据训练,易受奖励黑客攻击和分布外(OOD)输入影响,泛化能力差。例如,在RM-Bench的困难子集上,即使最先进的RM准确率也仅为46.6%,远低于随机猜测的50%。这源于RM的认知不确定性:在OOD数据上,预测可靠性显著下降,如图1所示,不确定性与准确率呈负相关(Spearman相关系数-0.21至-0.23)。
相比之下,强大的LLM评判器(如DeepSeek-R1)利用链式思考(CoT)推理,在RM-Bench困难子集上准确率达78.9%,无需额外训练即可实现优异泛化。但其自回归生成和长推理链导致推理成本高、延迟大,无法直接用于在线RLHF的策略优化。
为解决这一困境,我们提出不确定性路由框架:将RM与LLM评判器高效结合。核心创新是将策略梯度(PG)方法中的优势估计转化为成对偏好分类,使用谱归一化高斯过程(SNGP)量化RM的不确定性。低不确定性样本由快速RM处理,高不确定性(阈值以上)样本路由至LLM评判器,提供可靠反馈。这种方法避免了点状RM的非确定性问题(Bradley-Terry模型下添加提示偏差不影响偏好分布),转而采用成对偏好模型(PM),其分类性质便于不确定性量化。
>方法详解
1. PM训练与不确定性量化:基于Llama-3.1-8B-Instruct,使用HelpSteer2-Preference数据集训练PM。将提示和两个响应拼接为单一序列,输出分类logit。应用SNGP:在Transformer块添加谱归一化,最后隐藏状态通过高斯过程层(随机特征近似)计算logit g(h)和不确定性 u。训练损失为缩放BT损失,第三轮冻结权重计算后验协方差矩阵。推理时,p = g(h)/u,u 捕捉认知不确定性(数据覆盖不足引起),而非随机不确定性(人类偏好固有)。
2. 路由与优势估计:在RLOO(一种PG方法)中,为每个提示生成K=4响应,计算K(K-1)对偏好矩阵。若u ≤ 阈值,使用PM预测;否则,调用LLM评判器(输出更好/更差/平局标签,转换为高置信奖励差)。优势Ai = 1/(K-1) ∑_{j≠i} pe(x, yi, yj),其中pe融合两源预测。最终策略损失为LRLOO(θ) = -1/[K(K-1)] ∑ pe log πθ + β DKL(πθ || πref)。
此框架类似于主动学习:LLM评判器充当“预言机”,不确定性作为采集函数,选择最具信息量的样本。不同于传统主动学习,我们直接用于在线RLHF的优势计算,而非迭代训练RM,实现了即时反馈。
>实验验证与洞见
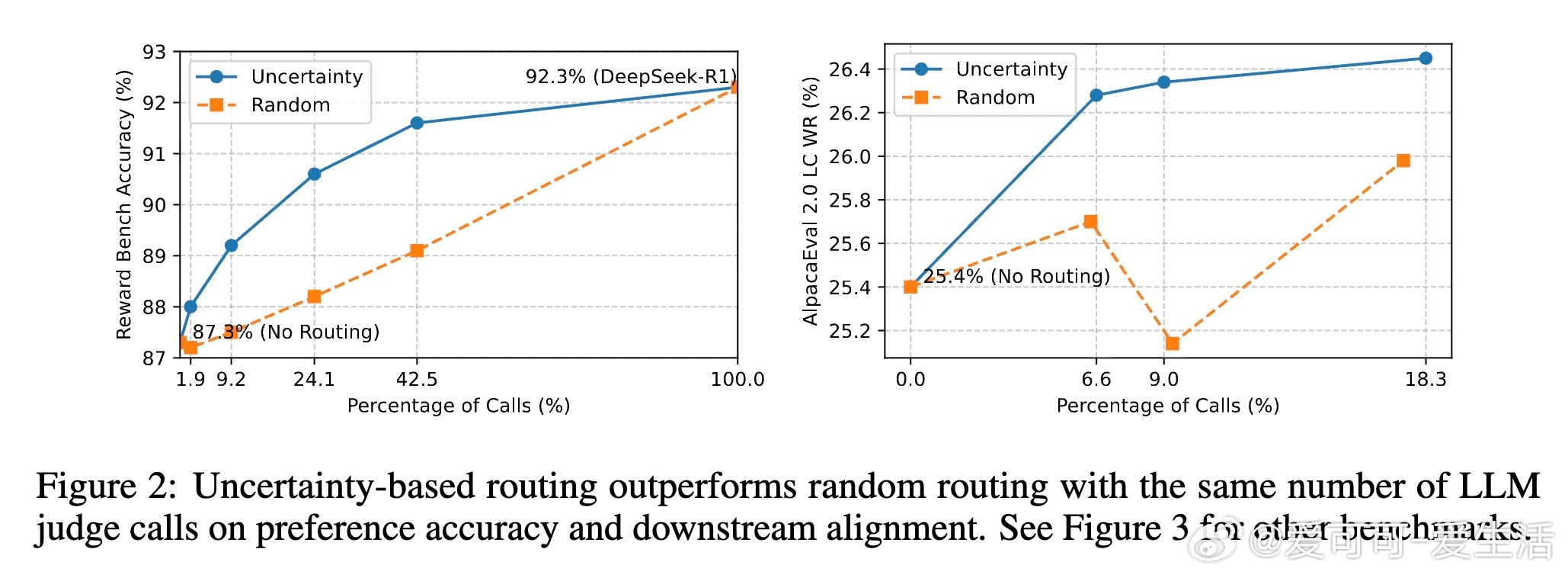
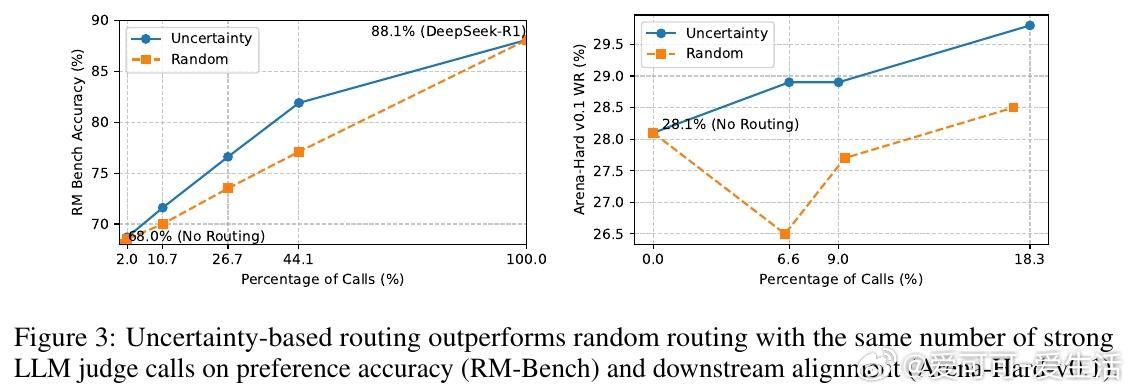
使用RewardBench和RM-Bench评估RM性能,Ultrafeedback数据集进行下游对齐,基准包括Arena-Hard-v0.1、AlpacaEval 2.0和MT-Bench。
- RM基准:SNGP-PM准确率与标准PM相当(差异思考与未来方向
此框架在平衡速度、成本与可靠性间取得突破,适用于PPO/GRPO等PG方法。未来,可探索分层路由(量化样本难度与评判器不确定性)、替代UQ方法(如深度集成),或将不确定样本反馈给人类标注,扩展偏好数据集。更深层洞见:RLHF的核心是可靠奖励信号,此方法揭示不确定性不仅是问题,更是机会——通过智能路由,将LLM推理能力转化为可扩展工具,推动更鲁棒的对齐。
代码开源:
原论文链接:arxiv.org/abs/2510.20369