[LG]《KL-Regularized Reinforcement Learning is Designed to Mode Collapse》A GX-Chen, J Prakash, J Guo, R Fergus... [New York University & EPFL] (2025)
KL正则强化学习本质上设计为模式坍缩:一篇理论与实践洞见
本文深刻剖析了强化学习(RL)在大型语言模型(LLM)和化学语言模型等领域的多样性问题。传统观点认为,反向KL散度优化倾向“模式寻求”(mode-seeking),正向KL则“覆盖质量”(mass-covering),后者更适合多模式采样。但作者通过数学证明和实验证明,这种直觉在KL正则RL中并不成立。相反,KL类型仅决定最优目标分布族,而模式覆盖主要取决于正则化强度β、奖励与参考概率的相对尺度。常见设置(如低β和平等可验证奖励)往往构建单模目标分布,导致多样性坍缩——这不是优化故障,而是目标函数的内在设计。
>为什么RL容易丢失多样性?
RL后训练基础模型的核心是正则化目标:最大化外部奖励R,同时保持策略πθ与参考分布πref的“接近”(如保持语法连贯)。输出多样性至关重要:在LLM中,它驱动创意写作和对话;在更广义上,支持新知识发现(如数学解、算法创新)和科学探索(如假设不确定性)。训练中,多样性还促进探索以收敛更好解。
然而,实证显示RL提升质量却牺牲多样性(如Kirk et al., 2023)。作者退一步诊断:优化目标本身是否有多样解?答案往往是“否”——即使无限计算、高质量数据和完美优化,常见超参数下全局最优解天生单模。
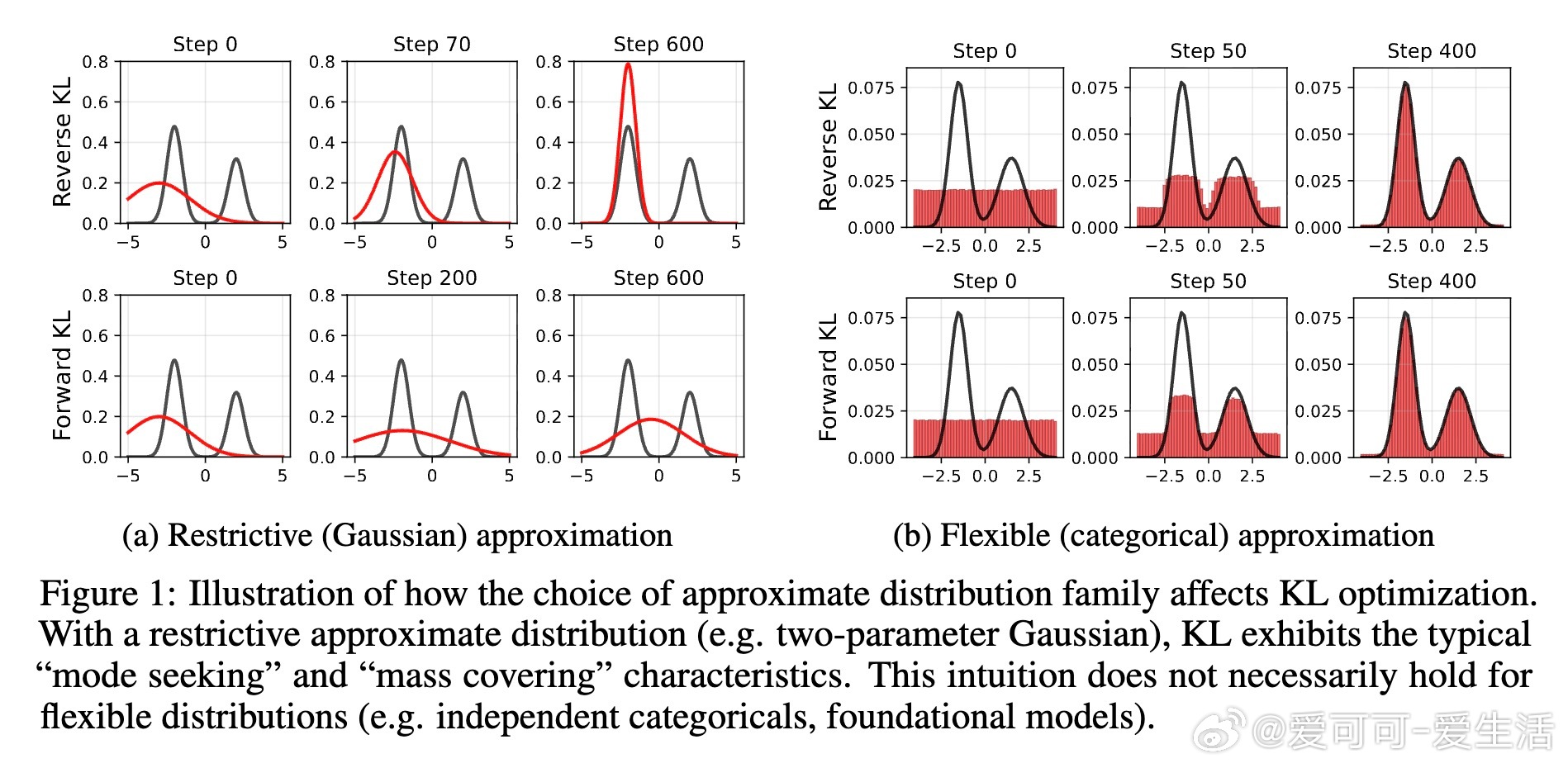
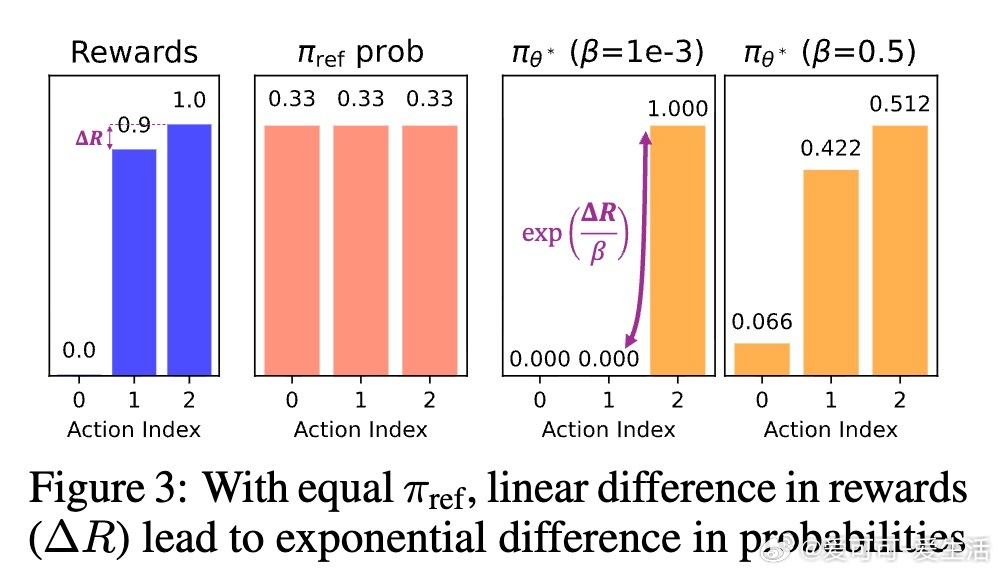
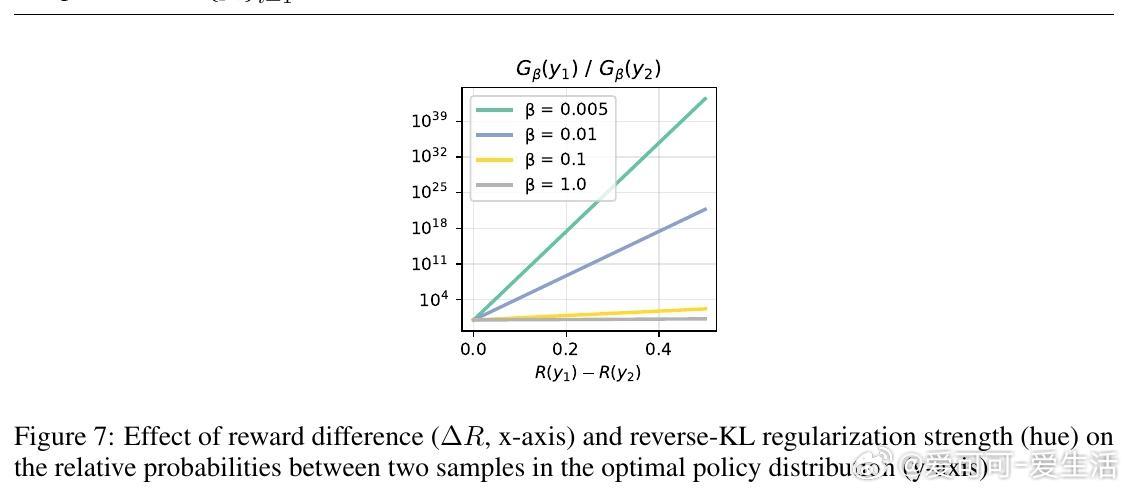
- 反向KL目标:J_β(πθ) = E[R(y)] - β D_KL(πθ || πref)。最优分布G_β(y) ∝ πref(y) exp(R(y)/β),梯度等价于最小化πθ与G_β的反向KL。直观上,小β放大小奖励差异,导致指数级概率倾斜:奖励差0.1、β=10^{-3}时,高奖励样本概率高出2.6×10^{43}倍(见图3)。结果:策略坍缩到最大奖励模式。
- 正向KL目标:J_fwd(πθ) = E[R(y)] - β D_KL(πref || πθ)。最优G_fwd(y) = β πref(y) / (Λ - R(y)),Λ > max R(y)。这不是简单“覆盖质量”——梯度并非正向KL形式,且若高奖励区超出πref支持,G_fwd可在零支持区均匀分配质量。但在πref支持内,它不继承传统直觉。
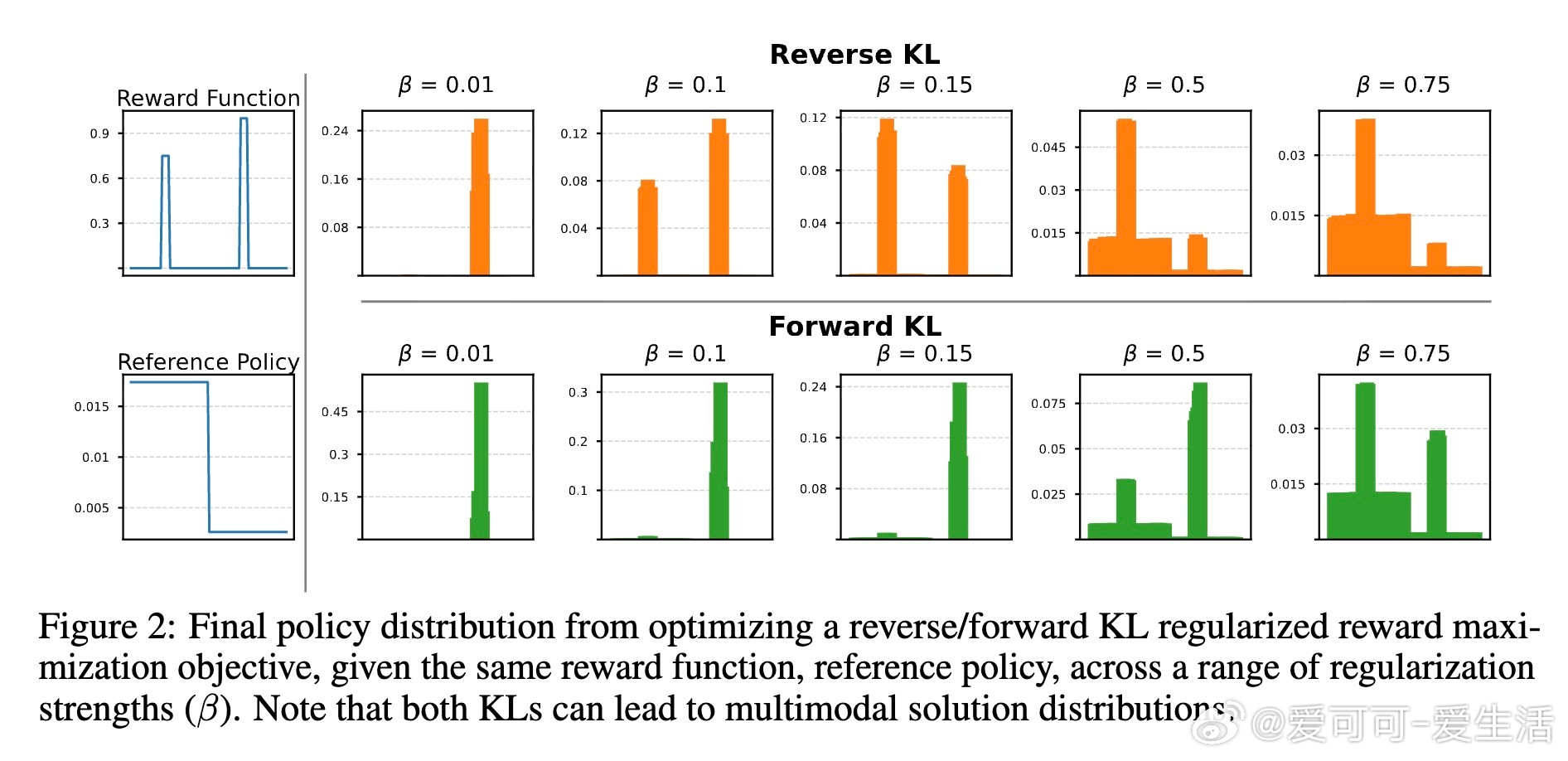
关键洞见:两者都能产生多模分布(定义:所有高奖励样本均获高概率,见图2),但依赖β。模式覆盖不靠KL类型,而是:
1. 等支持下:小奖励差导致指数概率爆炸,低β加剧坍缩。
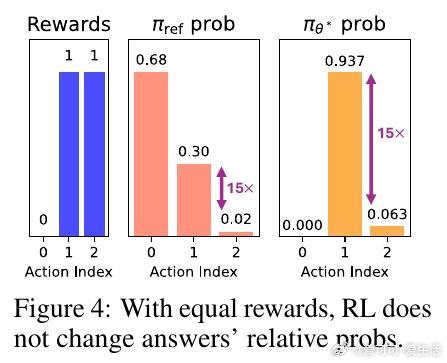
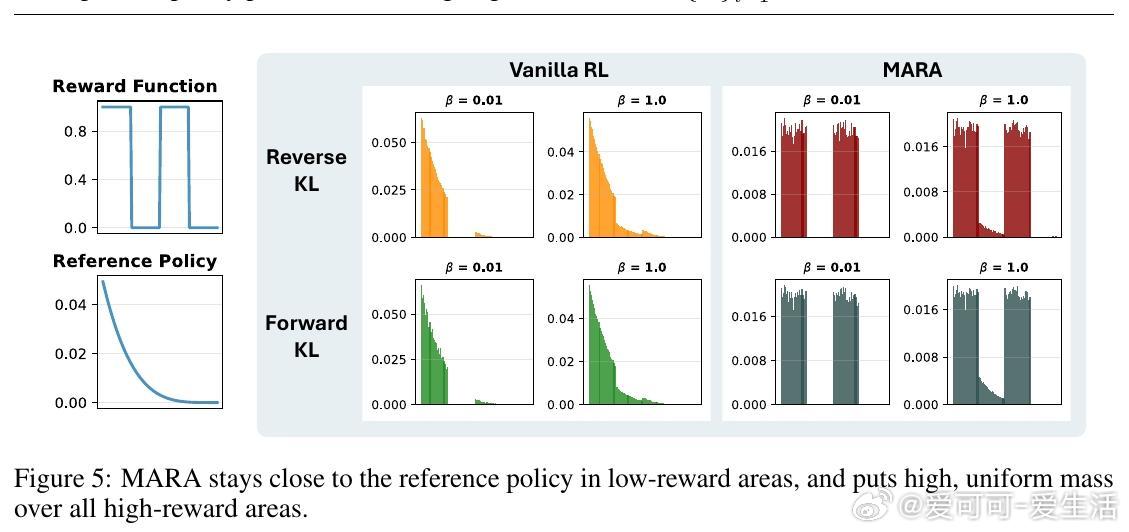
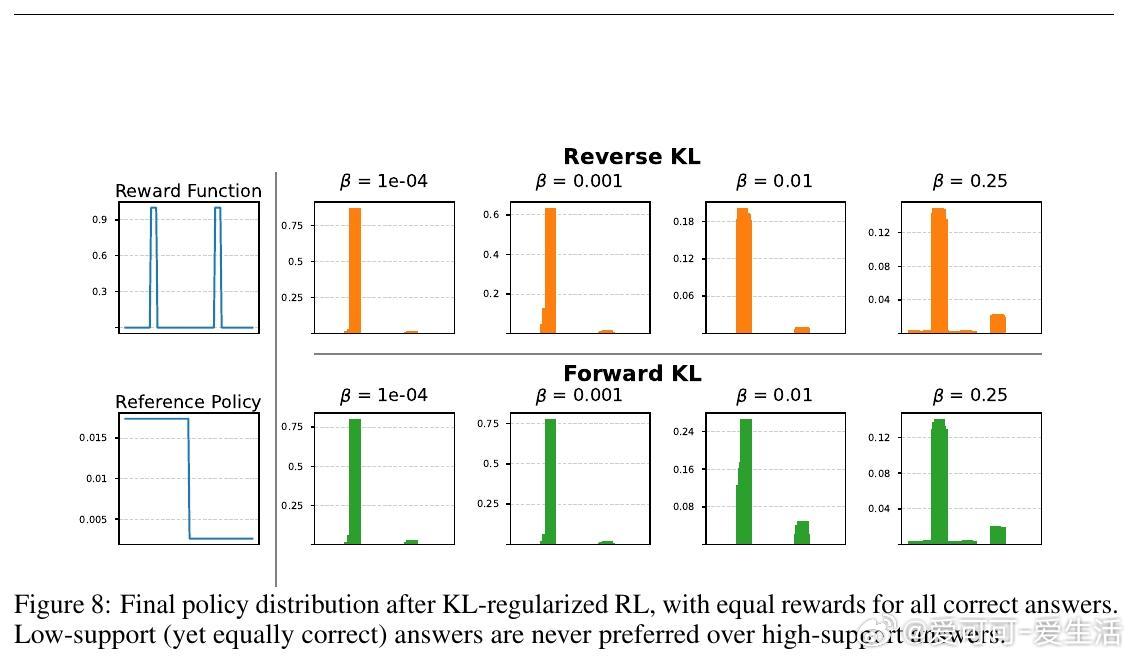
2. 等奖励下(如数学任务,正确答1分、错0分):G_β(y1)/G_β(y2) = πref(y1)/πref(y2),独立于β。低支持正确答永不优于高支持正确答(见图4、8)。这解释了为什么RL偏好“安全”但单调输出。
3. 不等奖励与支持:β充当“旋钮”——唯一β使两样本概率相等:ΔR = β (log πref(y1) - log πref(y2))(命题4.1)。如图2,高支持模式(奖励0.75)在β=0.15时主导,低支持(奖励1.0)在β=0.1时翻转。但典型低β偏好高支持,忽略低支持创新。
这些不是后训练“怪癖”,而是RL目标的自然后果。作者强调:KL-RL本质是分布匹配问题,应明确设计目标分布,而非依赖正则化直觉。
>如何构建多模目标?引入MARA算法
基于上述,作者推导简单、可扩展算法:Mode Anchored Reward Augmentation (MARA),仅微调奖励幅度,即优化多模分布——高奖励区(>阈值τ)均匀高密度,低奖励区贴近πref(见图5)。核心:增强奖励R¯(y) = R(z) + β (log πref(z) - log πref(y)),若R(y) ≥ τ,其中z是高奖励“锚点”(如max πref under R≥τ)。伪代码仅两行改动(算法1),兼容反/正向KL,无需外部多样信号。
- 理论基础:增强后G¯_β在高奖励区统一为πref(z) exp(R(z)/β),确保所有优质样本等概率(备注B.3)。τ可固定(如已知范围)或批次上分位数。
- 深度思考:MARA不只是修补,而是重塑目标——它平衡探索与利用,避免“奖励同质化”陷阱。在不确定环境中,这促进鲁棒性:如LLM创意任务,多样输出反映真实不确定性;在药物发现,高效采样独特分子加速创新。相比显式多样奖励(如Li et al., 2025),MARA更简洁、无需额外模型,适用于任何KL-RL。
>实验验证:从LLM到药物发现
作者在真实场景测试MARA作为“即插即用”方法。即使早停训练,也受益于多模最优。
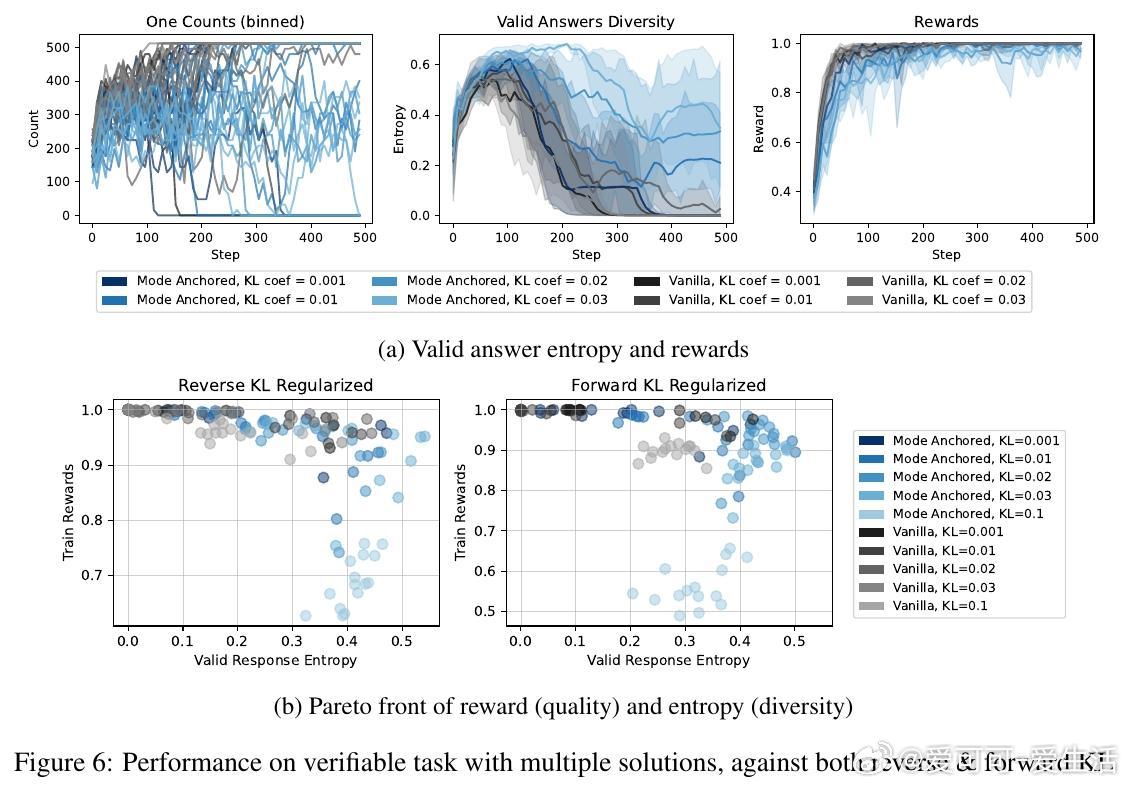
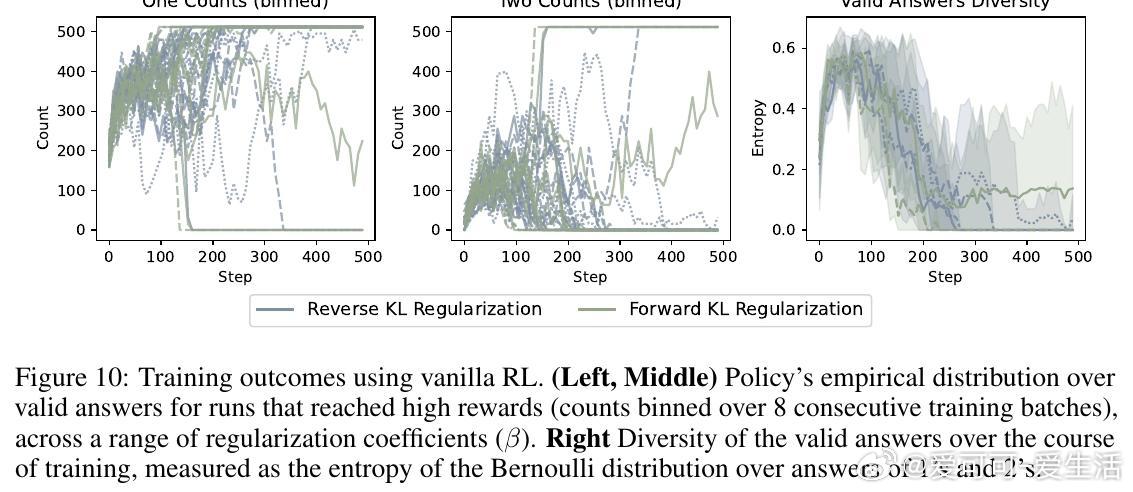
1. 可验证LLM任务(1-2生成):训练Qwen2.5-3B生成随机1或2(奖励1正确、0否则)。 vanilla RL坍缩到高似然“1”(见图10),MARA保持近均匀分布(熵~1),匹配正确率却超多样性(图6)。Pareto前沿显示:质量不变,多样性提升。
2. 非可验证创意问答:Qwen3-1.7B在WildChat上用奖励模型训练。MARA(反/正向KL)优于GRPO/RLOO:分布外奖励更高(1.60 vs 1.32),n-gram/语义多样性提升(表1)。无外部信号,即获更好泛化。
3. 化学语言模型药物发现:适应REINVENT算法,奖励结合结合亲和力与可合成性(SYNTH/ALL-AMIDE任务)。预算10k评估下,MARA产量(Yield)更高、效率(OB100)更好、多样(IntDiv1/Circles)持平或优(表2)。在挑战性阈值0.85,MARA发现更多独特高奖励分子,证明多样性在昂贵模拟中的价值。
这些结果印证:MARA在复杂域放大RL潜力,推动从单模“完美”到多模“创新”。
>结语与启发
这篇论文提醒我们:AI优化不止追高分,更需设计“想要的”分布。未来可深化正向KL梯度、MARA变体,或扩展到更广分布族。KL-RL如双刃剑——理解其“设计坍缩”,才能解锁多样驱动的智能。推荐AI研究者和从业者阅读,思考如何在实践中应用。
原论文链接:arxiv.org/pdf/2510.20817
(此推文基于论文核心,精炼要点并添思考深度,适合分享讨论。)