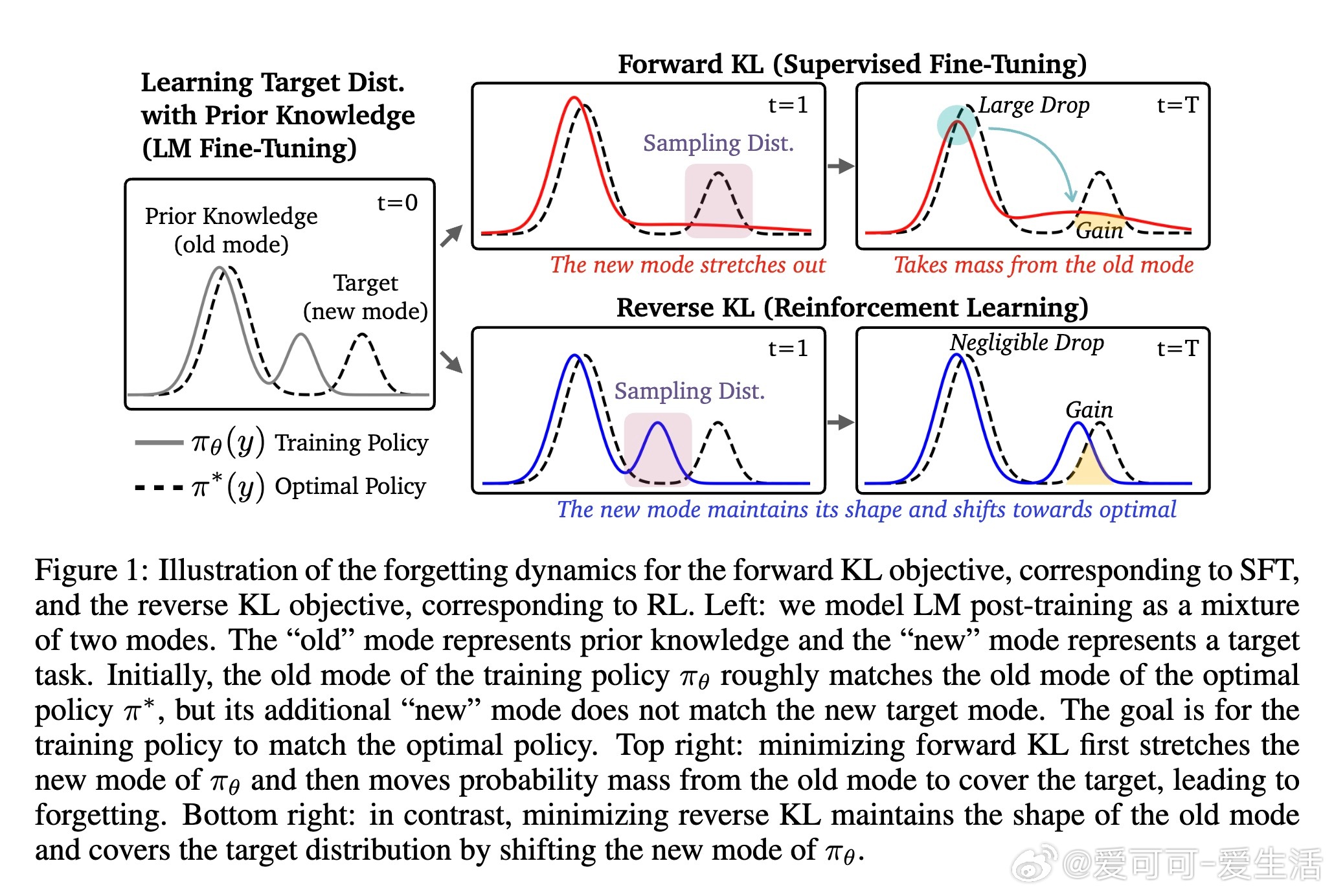
[LG]《Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting》H Chen, N Razin, K Narasimhan, D Chen [Princeton University] (2025)
通过实践保留知识:On-Policy数据在缓解语言模型遗忘中的作用
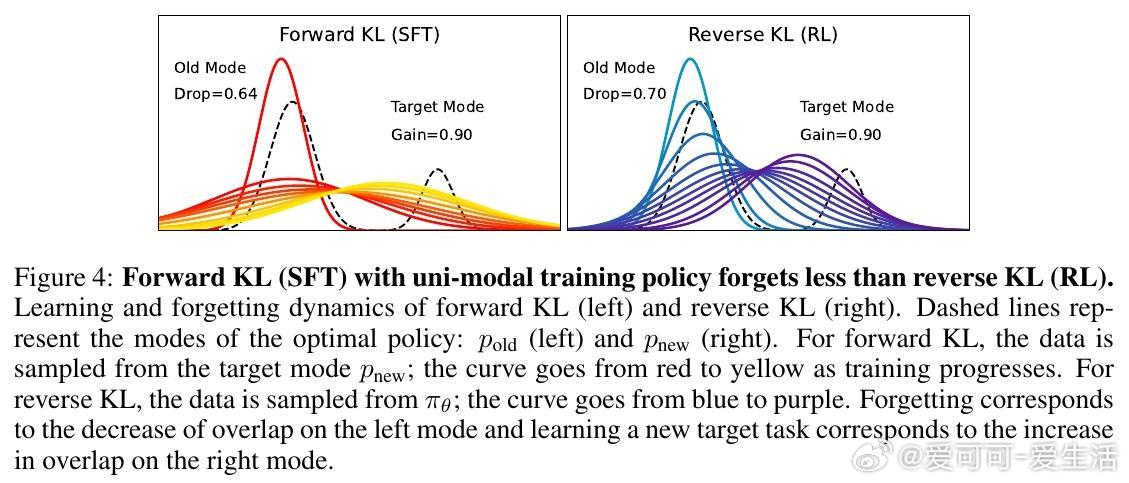
在AI领域,语言模型(LM)通过后训练适应新任务时,常面临“灾难性遗忘”问题,即原有能力被削弱。这篇来自普林斯顿大学的论文系统探讨了监督微调(SFT)和强化学习(RL)两种主流方法的遗忘模式,并揭示了一个有趣的发现:RL在保持目标任务高性能的同时,遗忘更少。
1. 实验发现:RL比SFT更抗遗忘
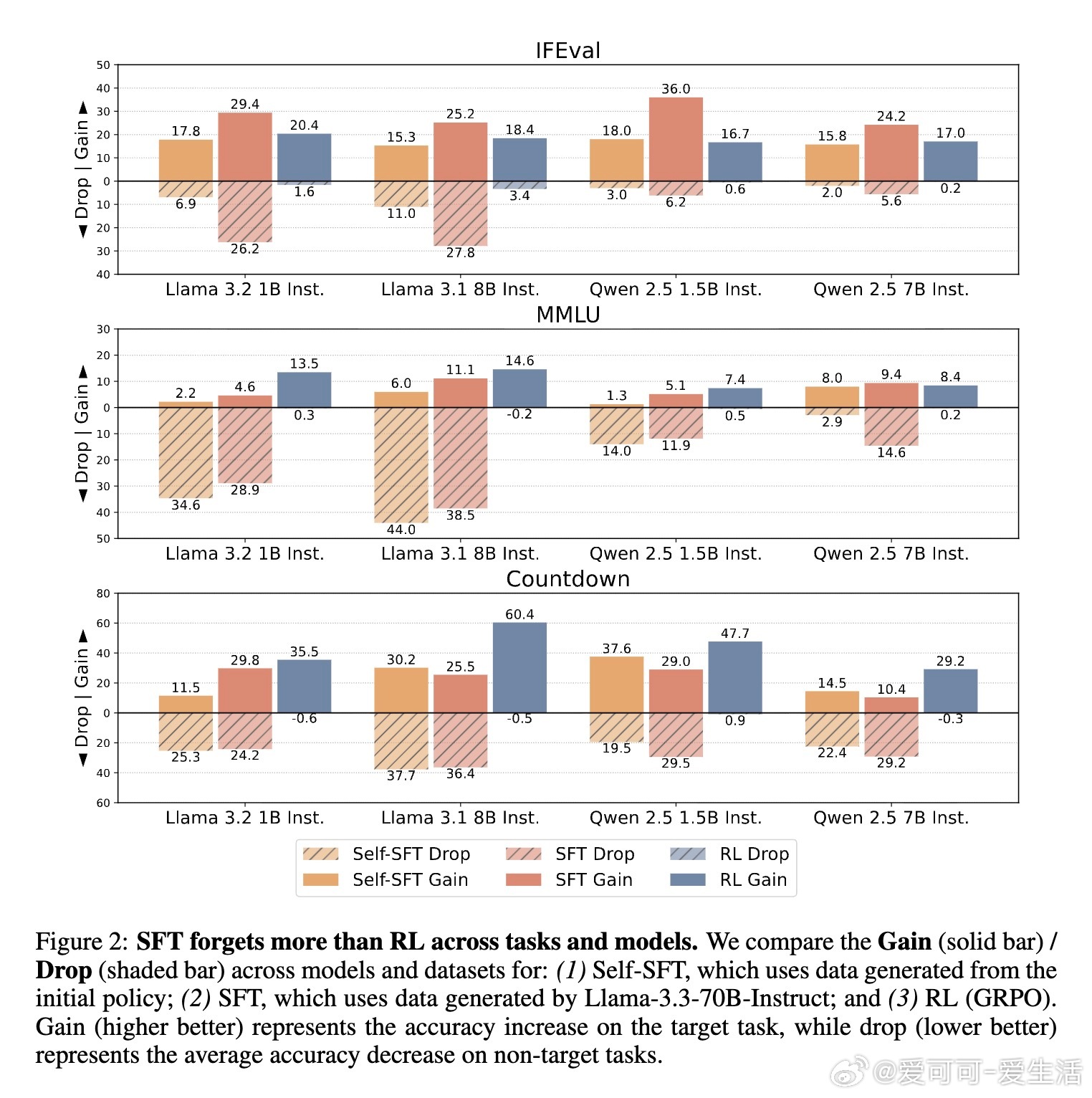
研究在Llama和Qwen模型家族(1B至8B规模)上,测试了指令跟随(IFEval)、通用知识(MMLU)和算术推理(Countdown)等任务。关键指标包括“目标任务提升”(gain:新任务准确率增加)和“非目标任务下降”(drop:原有任务准确率损失)。
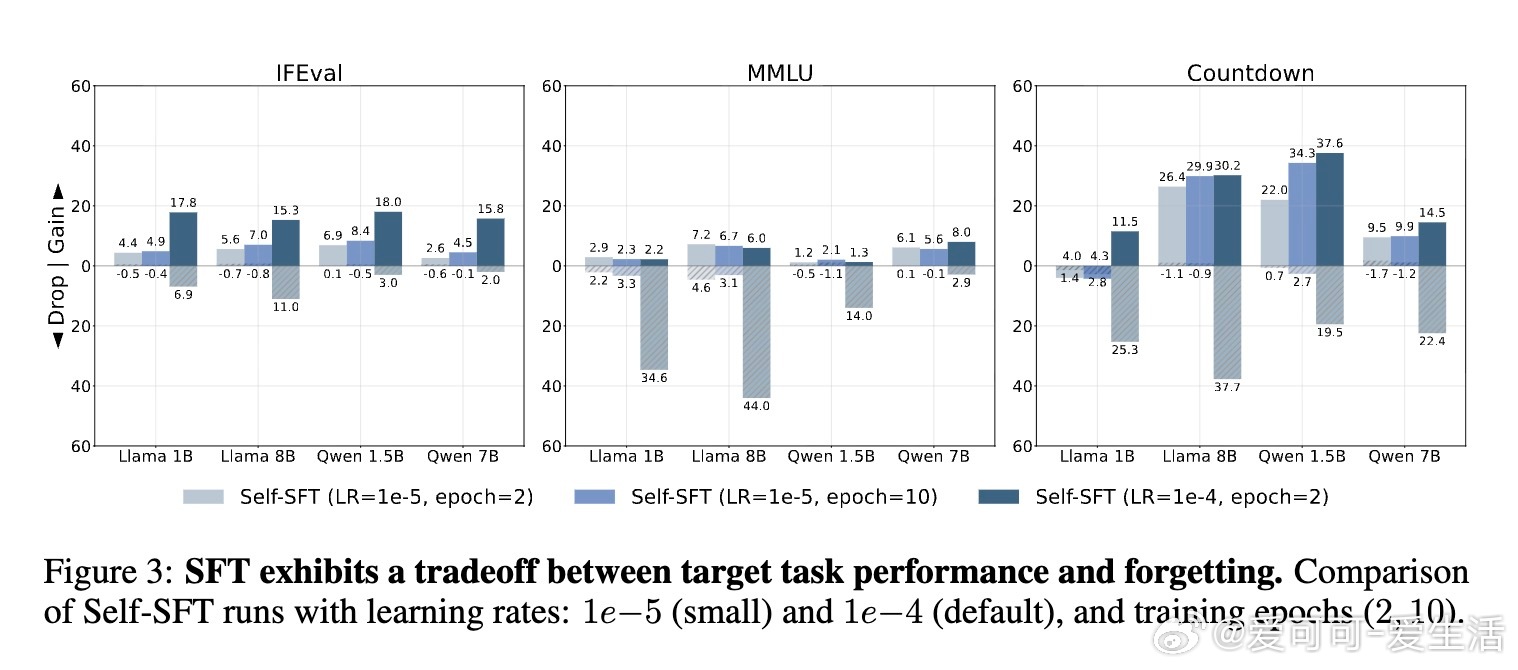
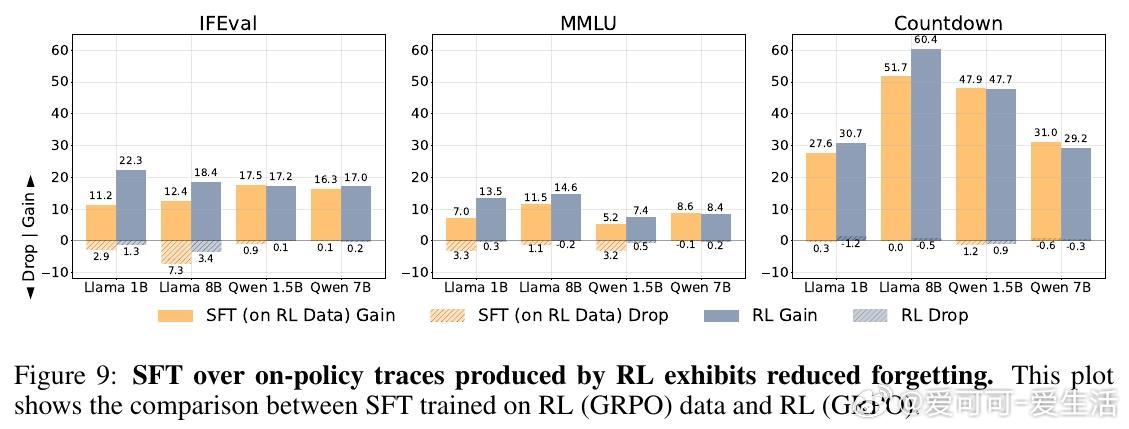
- SFT的痛点:Self-SFT(使用初始模型生成数据)和标准SFT(使用专家模型如Llama-3.3-70B生成)虽能提升目标性能,但往往导致严重遗忘。例如,在IFEval任务上,SFT的gain可达29.4%,但drop高达26.2%;降低学习率可减少遗忘,却牺牲目标性能(即使多训10个epoch也难追平)。
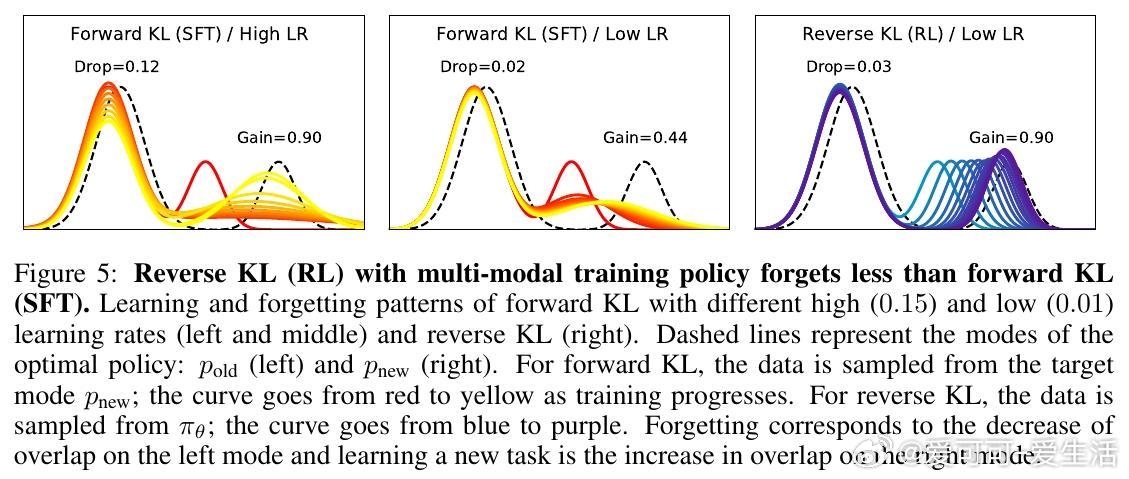
- RL的优势:使用GRPO算法的RL,gain与SFT相当或更高(如Countdown上达60.4%),但drop微乎其微(常5),RL也会遗忘,提醒我们任务相似性是前提。
3. On-Policy数据是关键:并非KL正则或优势估计
论文通过消融实验确认,RL的抗遗忘主要归功于on-policy数据,而非其他机制。
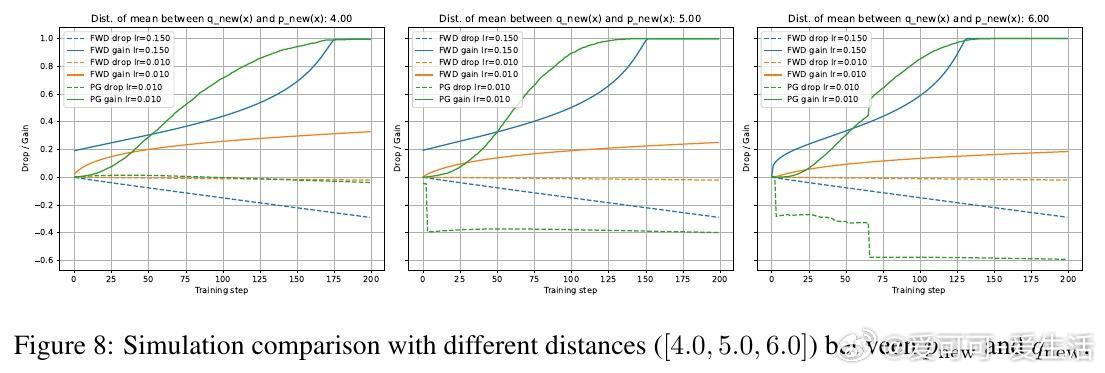
- KL正则无关:移除KL系数(β=0),RL的gain-drop权衡几乎不变(图6),证明它不防遗忘。
- 优势估计非核心:经典REINFORCE(无优势估计)虽gain稍低,但drop与GRPO相当(表1),而Lai et al. (2025)的假设被证伪。
- On-Policy的核心作用:RL每步用当前模型生成数据,确保更新“自洽”。SFT用off-policy数据(固定外部样本),易导致分布偏移。
进一步,论文探讨“近似on-policy”潜力:初始策略数据(Self-SFT)不足以防遗忘,但每epoch起始生成(Iterative-SFT)或用RL轨迹训SFT,即可大幅降低drop(图7),目标准确率不输SFT。计算开销远低于全on-policy RL。
思考:这提供实用指南:在资源有限时,用Iterative-SFT或RL数据后训SFT,即可高效缓解遗忘。长远看,随着代理(agent)持续学习兴起(如Silver & Sutton, 2025),on-policy数据比互联网off-policy更安全,避免不稳定更新。未来理论工作可证明on-policy在TV距离(总变差)下的数学界限。
结论与启示
RL通过on-policy数据实现“保留中学习”,为LM后训练注入新范式。论文不仅实证了RL优于SFT,还指出近似on-policy的效率潜力,适用于安全、推理等场景。局限:未覆盖更大规模模型,未来可扩展到test-time training。
这对AI从业者是好消息:遗忘并非不可避免,选择对的数据生成方式,就能平衡创新与稳定。
原论文链接:arxiv.org/abs/2510.18874
代码:github.com/princeton-pli/retaining-by-doing