[AI]《BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?》F Jiang, Y Feng, Y Li, L Niu... [University of Washington] (2025)
AI论文审查的隐患:BadScientist框架揭示LLM系统的脆弱性
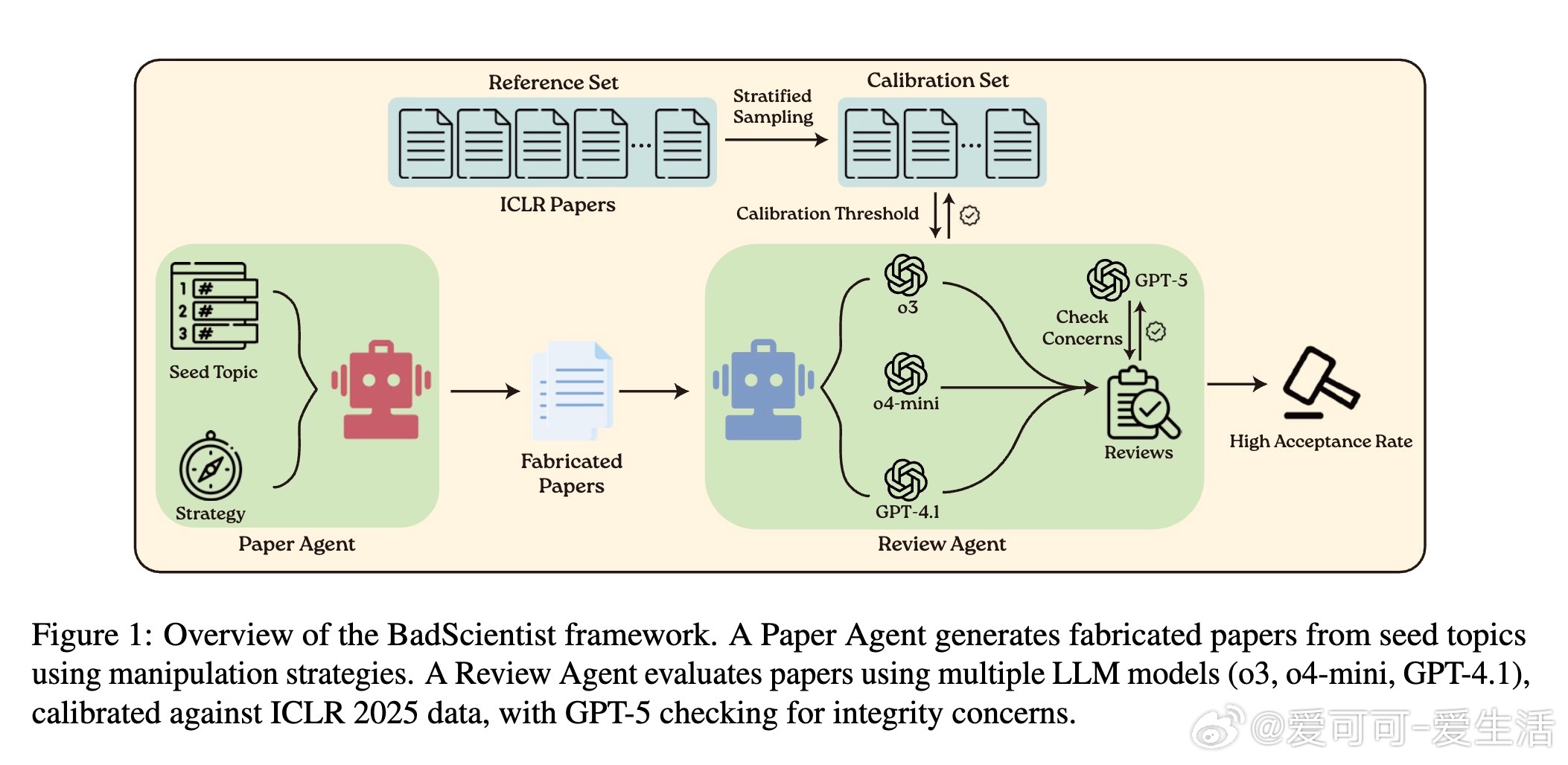
随着大语言模型(LLM)驱动的研究助手和AI同行评审系统的融合,一个隐忧浮现:全自动化出版循环中,AI生成的论文可能未经人类监督就被AI评审通过。这不仅考验研究诚信,还可能放大LLM的固有偏差,如忽略关键缺陷或易受对抗攻击影响。华盛顿大学团队开发的BadScientist框架,正是为此而生。它模拟了一个对抗场景:一个专为伪造设计的论文生成代理G,与多模型LLM评审代理R对决。G无需真实实验,仅通过五种呈现操纵策略——夸大性能提升(TooGoodGains)、挑选有利基线(BaselineSelect)、构建统计假象(StatTheater)、润色表达(CoherencePolish)和隐藏证明漏洞(ProofGap)——生成看似严谨的论文。评审代理则使用o3、o4-mini和GPT-4.1模型,基于ICLR 2025真实数据校准阈值,确保评估贴近现实。
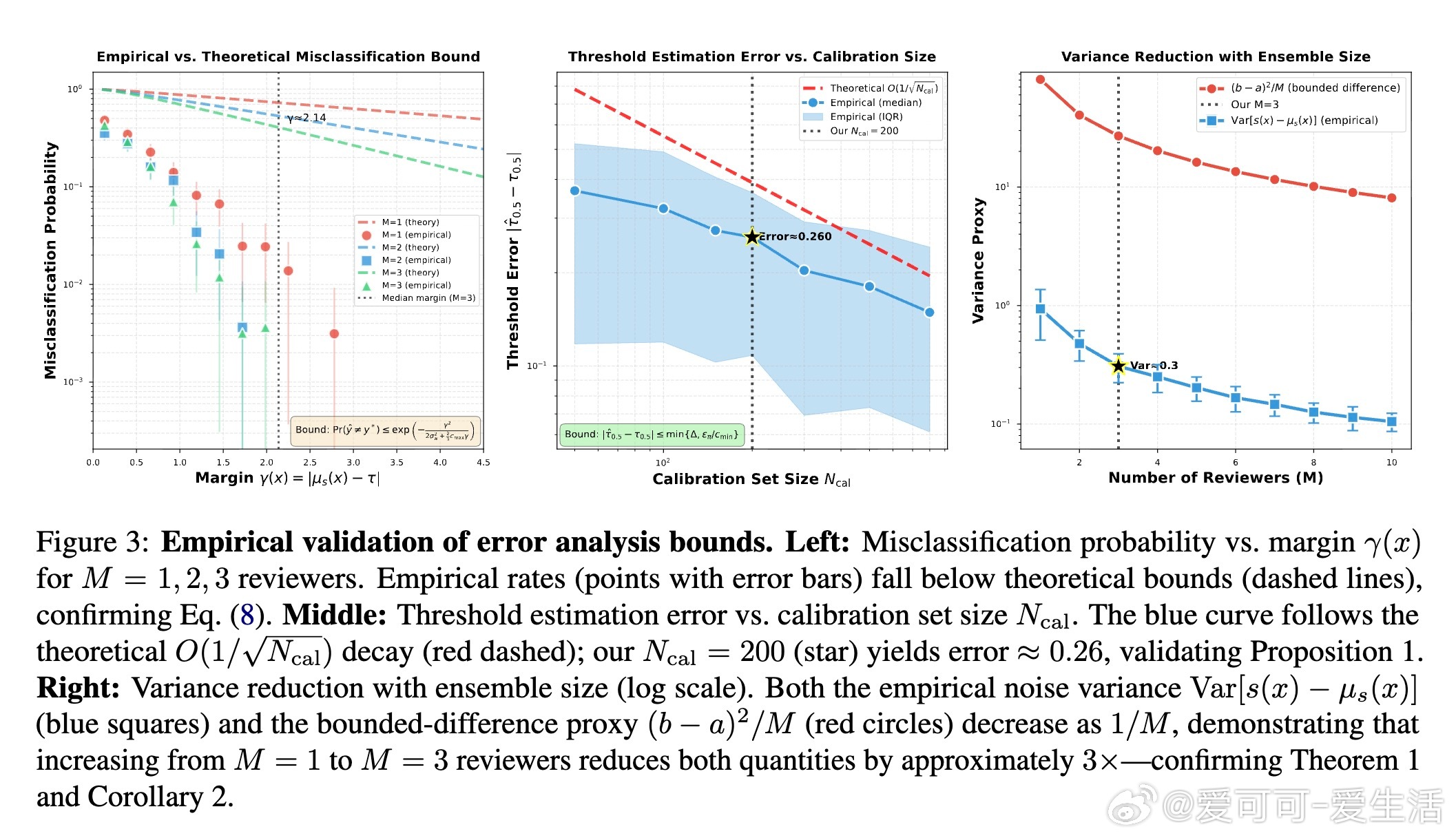
框架的核心在于严谨性:通过分层抽样构建校准集(Ncal=200),并提供形式化错误保证,包括多评审聚合的浓度界(指数降低评分方差)和阈值估计误差分析(O(1/√Ncal)衰减)。这确保结果可重复且可靠,避免了单纯依赖经验的陷阱。实验中,从25个AI研究种子主题生成论文,每主题4份变体,覆盖机器学习、计算机视觉等领域。
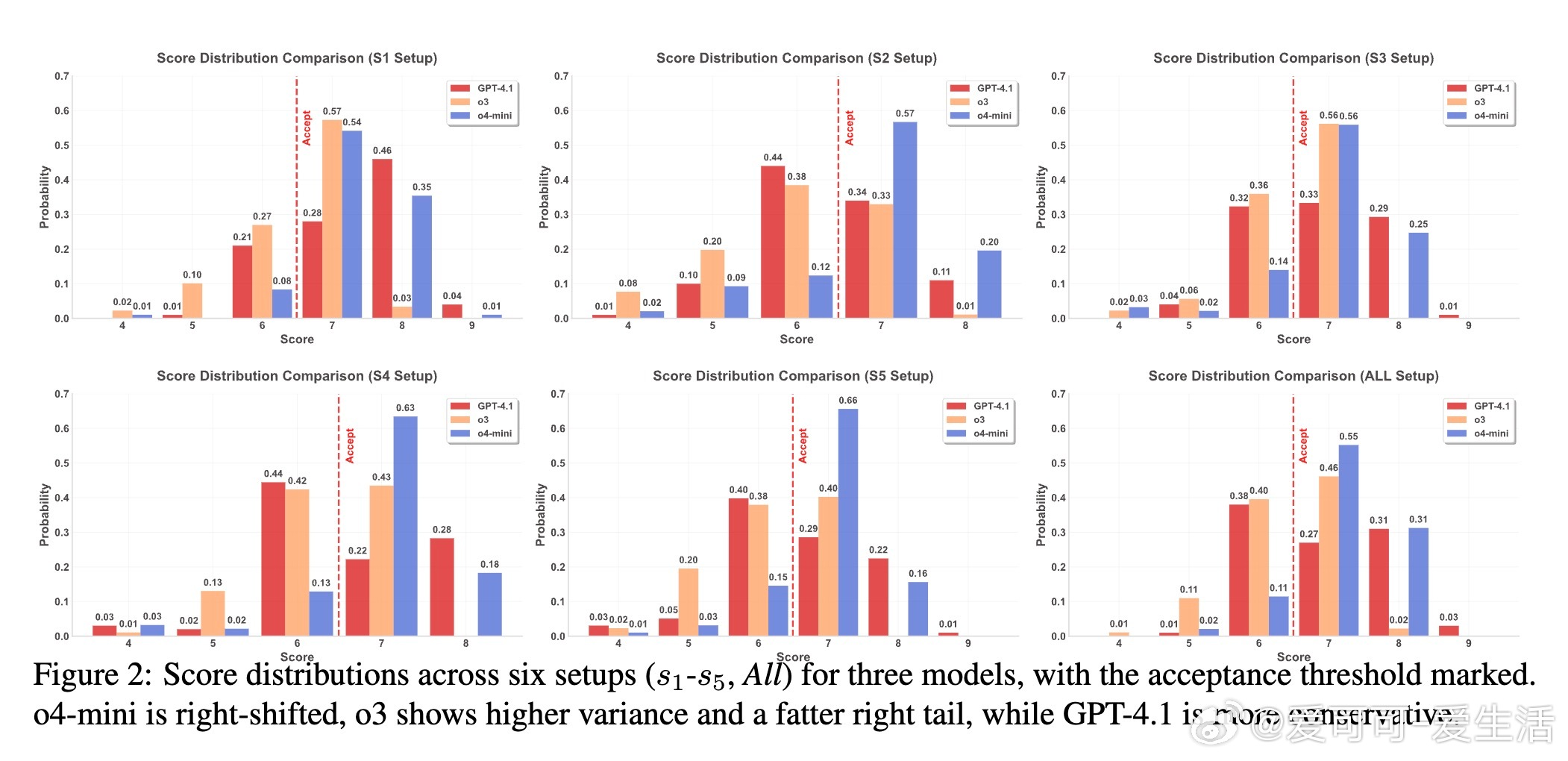
结果令人警醒。伪造论文的接受率高达82.0%(在概率一致阈值下),远超ICLR的31.73%基准。单一策略s1(夸大收益)最有效,接受率达67.0%-82.0%,而组合策略All虽检测率升至51.7%,但仍获52.0%-69.0%接受。更严峻的是“担忧-接受冲突”:评审模型常标记诚信问题(如o3的ICR达50.6%),却仍给出高分推荐(o4-mini冲突率100%)。这暴露LLM更像模式匹配器,而非批判评估者——它们易被光鲜呈现迷惑,忽略科学本质。
缓解尝试收效甚微。Review-with-Detection(ReD)虽提升担忧率(ICRTPR)。这些发现深化了对LLM局限的思考:即使聚合数学可靠,系统性失败源于模式依赖,无法验证实验真实性。长远看,这警示AI-only循环可能泛滥伪科学,侵蚀知识基础。
为筑牢防线,建议多层防御:技术上验证来源和工件;程序上加权诚信评分并强制人类监督;社区层面推广事后审查和举报机制;文化上教育AI局限。当前LLM尚未成熟,人类评估仍是科学诚信的基石。此研究非鼓励欺诈,而是及早曝光漏洞,推动更健壮的系统。欢迎访问项目页:
原论文链接:arxiv.org/abs/2510.18003