[CL]《How Do LLMs Use Their Depth?》A Gupta, J Yeung, G Anumanchipalli, A Ivanova [UC Berkeley & Georgia Institute of Technology] (2025)
大语言模型如何利用其深度?——“猜想-精炼”框架揭示内部计算机制
本文通过追踪开源模型(如GPT2-XL、Pythia-6.9B、Llama2-7B和Llama3-8B)的中间表示,深入剖析了LLM在推理过程中如何层级化地使用深度。这不仅仅是技术细节,更为理解模型“黑箱”和优化效率提供了新视角。论文提出“Guess-then-Refine”(猜想-精炼)框架,强调LLM像早期统计猜测者,后期上下文整合者。
1. 核心框架:猜想-精炼的层级预测动态
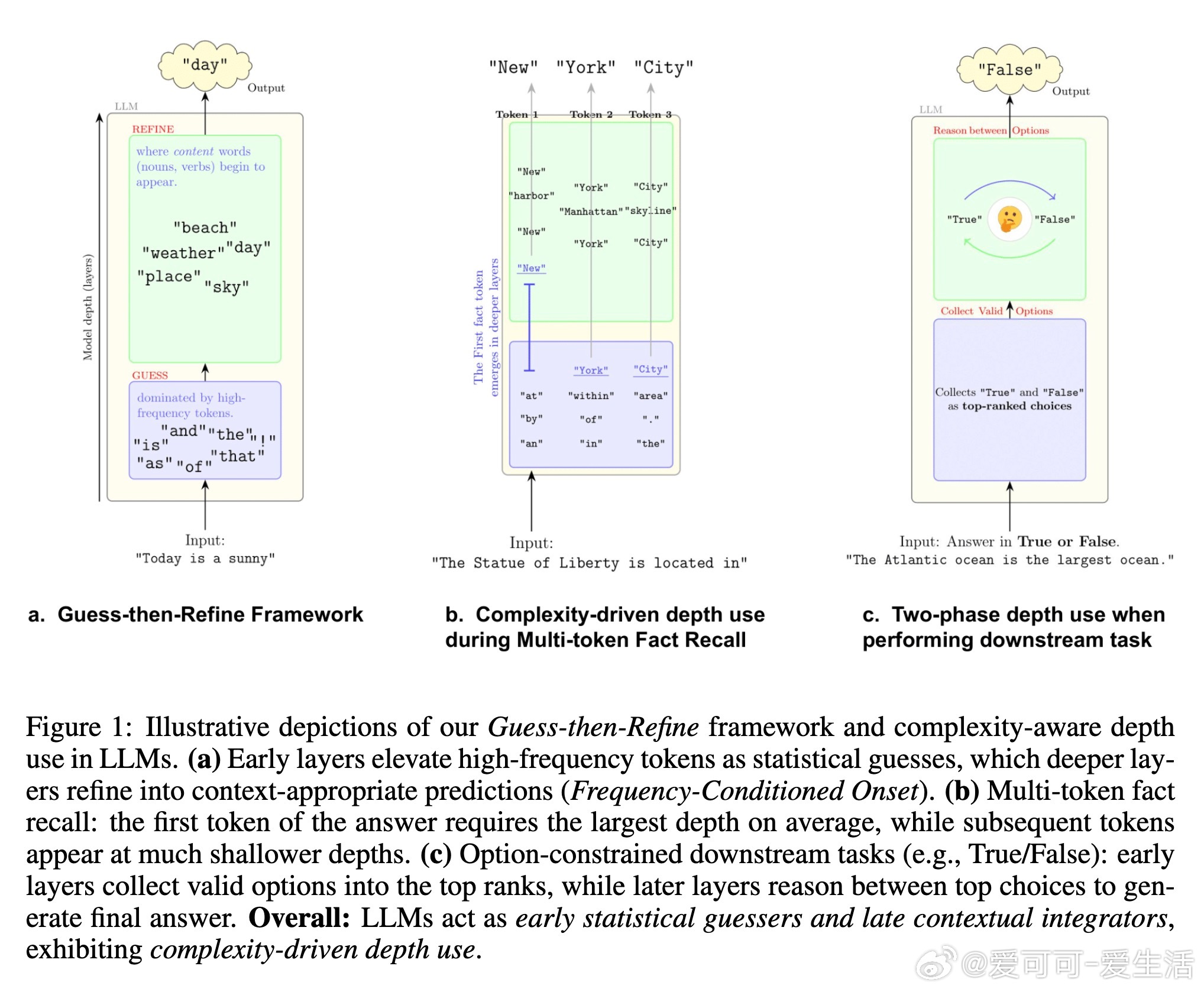
LLM并不均匀使用深度,而是遵循“猜想-精炼”策略:早期层(浅层)基于语料统计快速提出高频token作为“猜测”,后期层(深层)整合上下文信息进行大规模精炼,最终输出合适预测。
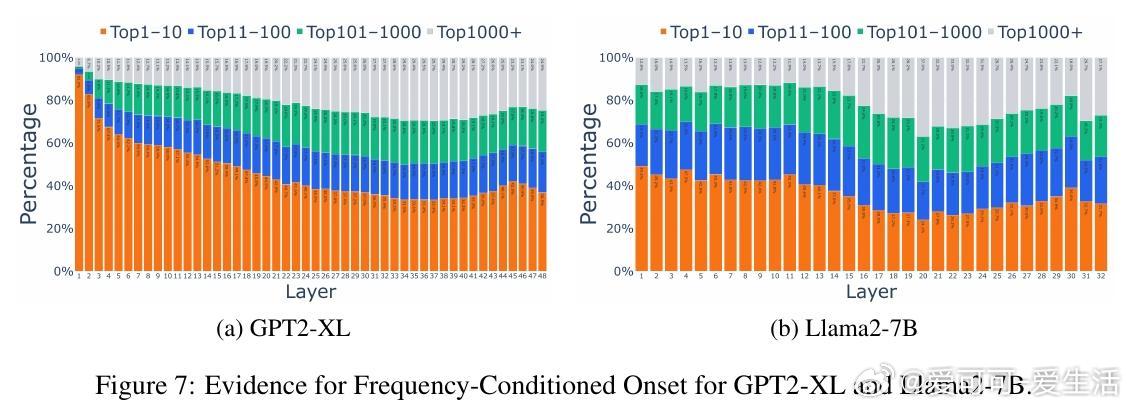
- 早期层:统计猜测主导(Frequency-Conditioned Onset)
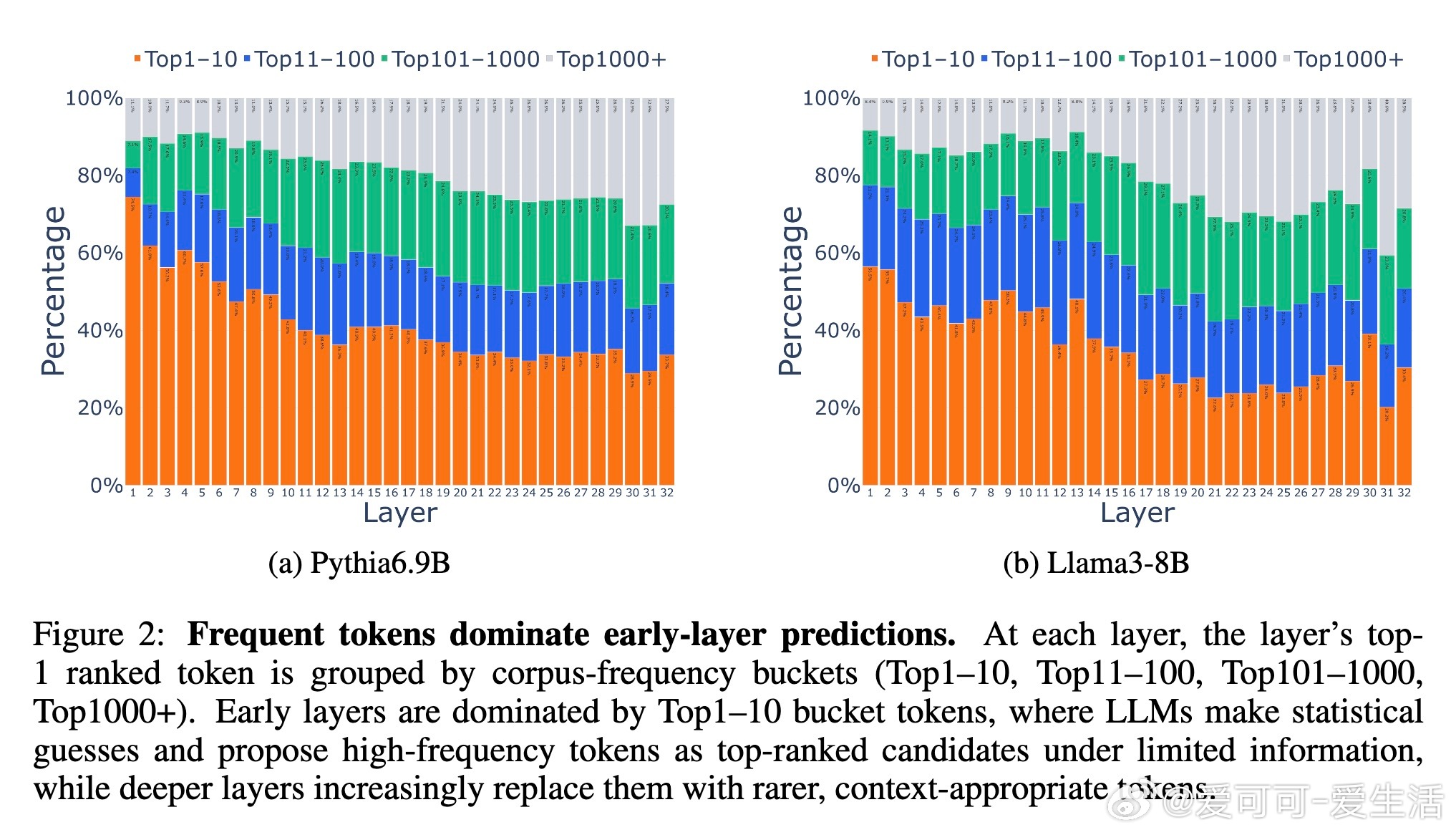
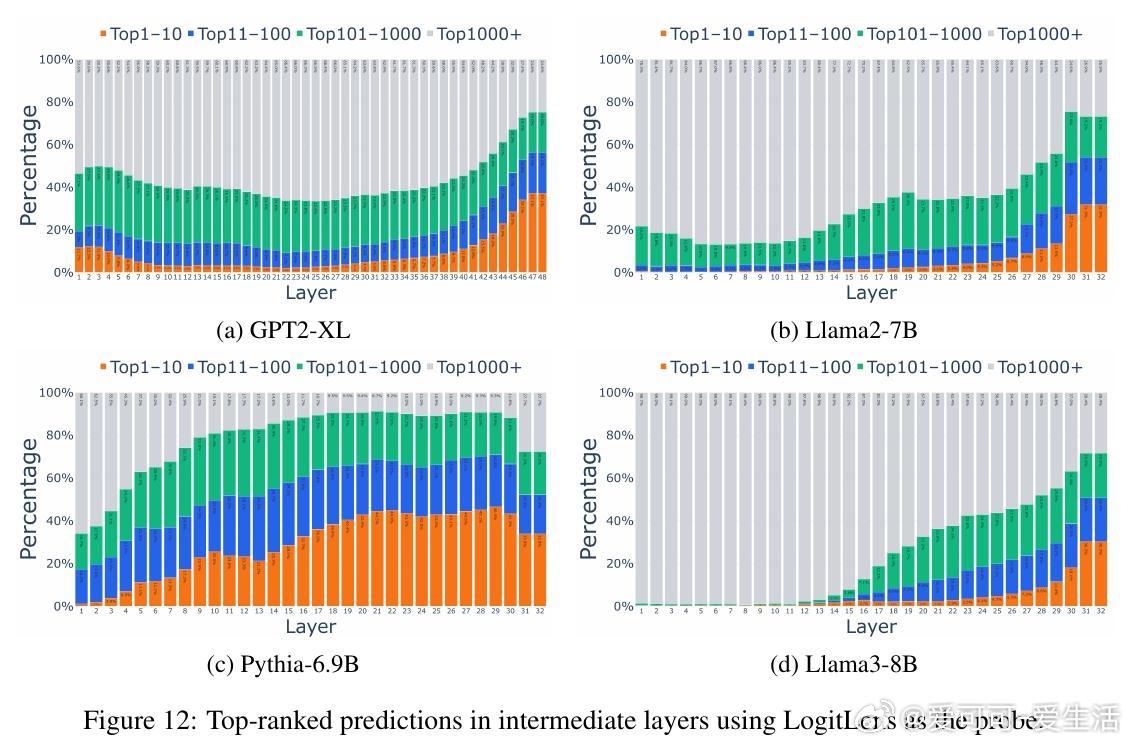
在浅层,模型缺乏完整上下文和事实知识(这些通常存储在中层MLP),因此依赖语料频率提出候选。例如,在Pythia-6.9B中,Top-10高频token(如“the”、“is”)在第一层占据75%以上top-1预测,而最终输出仅占34%。这是一种优化产物:在信息不足时,选择高频token能最大化正确率(约25%语料覆盖)。
*思考*:这揭示了预训练的“惰性”——模型像贝叶斯先验,浅层用频率作为默认假设,避免从零开始计算。相比人类认知,这类似直觉快速判断,但也暴露了浅层易受语料偏差影响的风险。
- 后期层:上下文精炼(Massive Refinement)
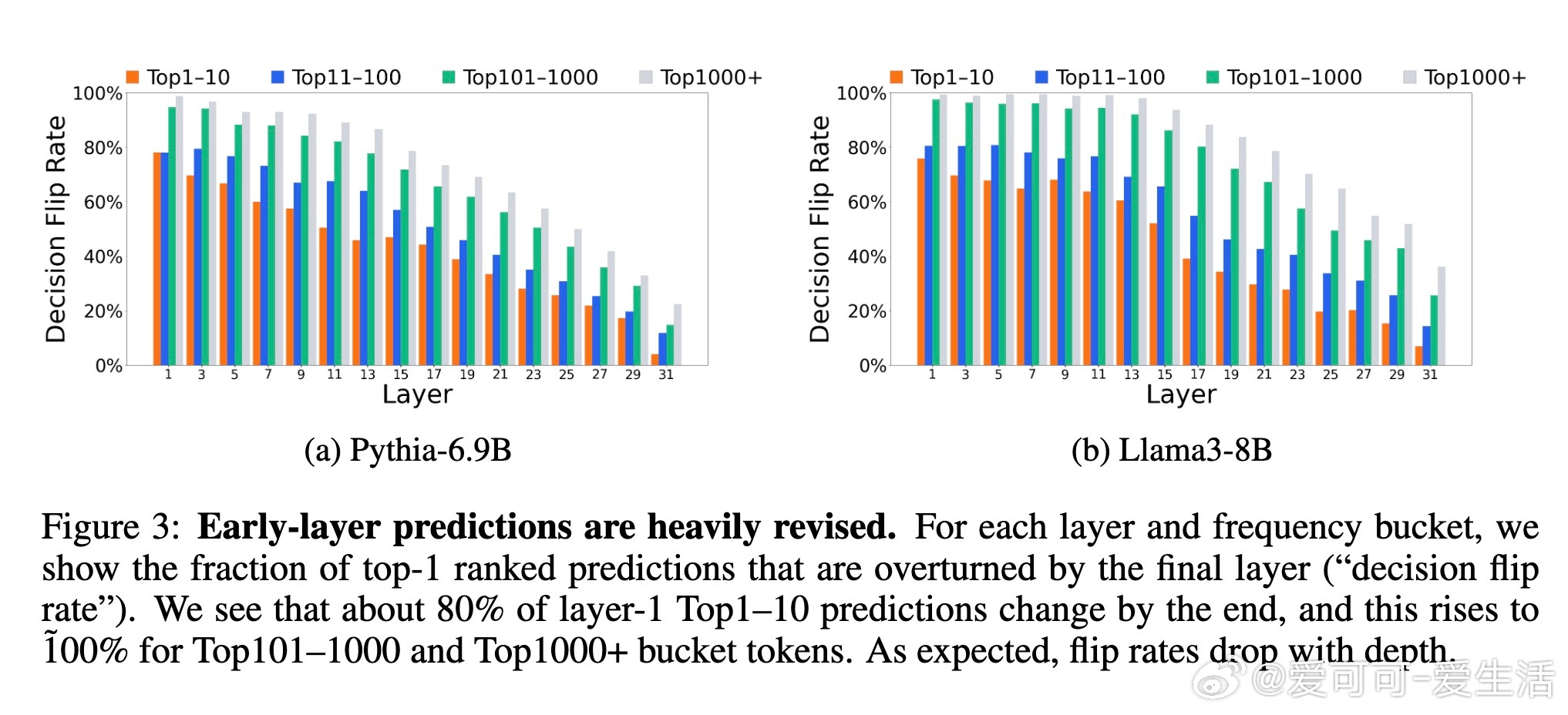
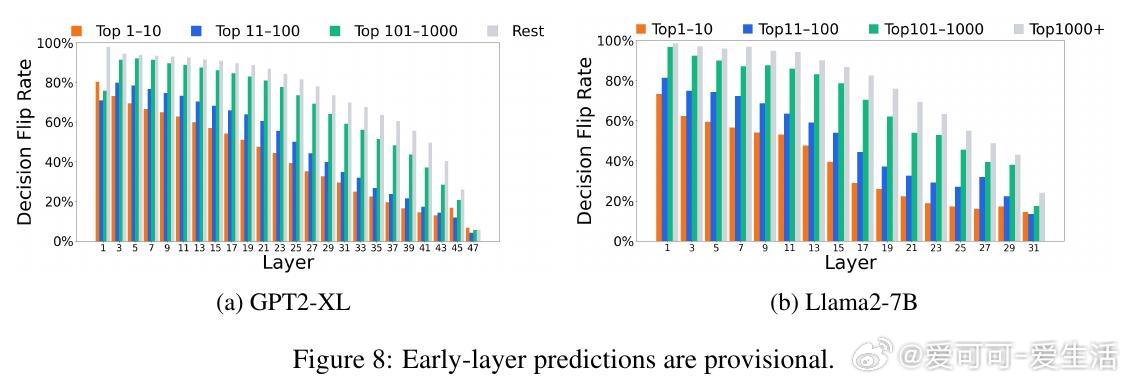
浅层猜测高度临时:超过70%的高频预测会被深层修改,甚至100%的低频token猜测也会重塑。精炼率随深度下降,表明预测并非“一劳永逸”。例如,Top1000+低频token在浅层仅占10%,到最终层升至30%以上。
*思考*:这强调深度不是冗余,而是迭代优化过程。精炼机制类似于渐进式推理,能解释为什么LLM在复杂任务中表现强劲,但也暗示早期退出(early-exiting)策略可能中断关键整合,导致错误率上升——未来效率优化需谨慎设计动态深度模型。
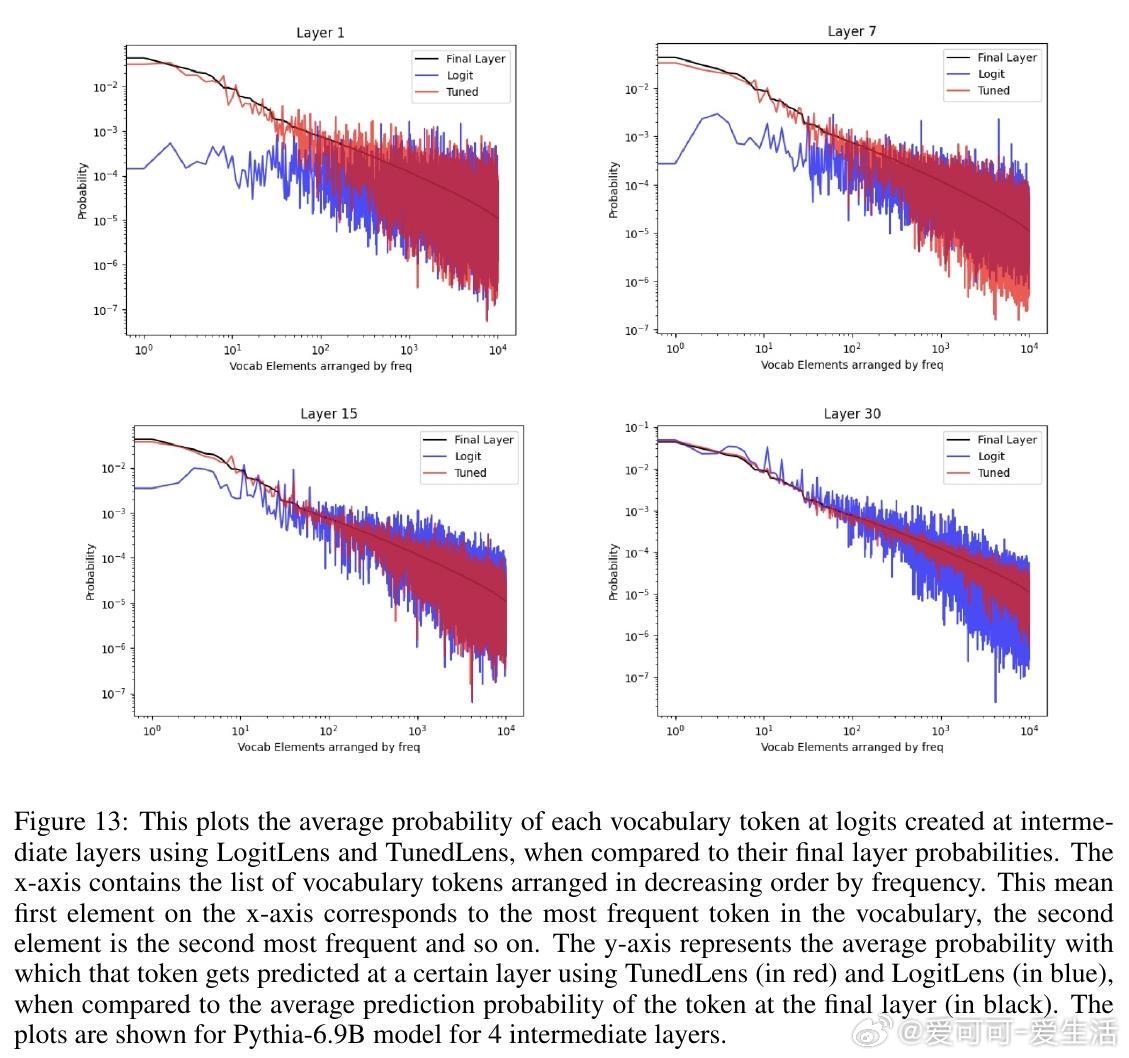
论文使用TunedLens工具(线性变换解码中间层)验证这些模式,并通过消融实验确认结果反映模型真实表示,而非probe偏差(如KL散度频率偏置)。
2. 复杂性感知的深度使用(Complexity-Aware Depth Use)
LLM像“自然动态深度模型”,根据任务复杂度灵活分配层级:简单子任务浅层完成,复杂部分推迟深层。三项案例研究展示了这一“智能”分配,超越单纯频率效应。
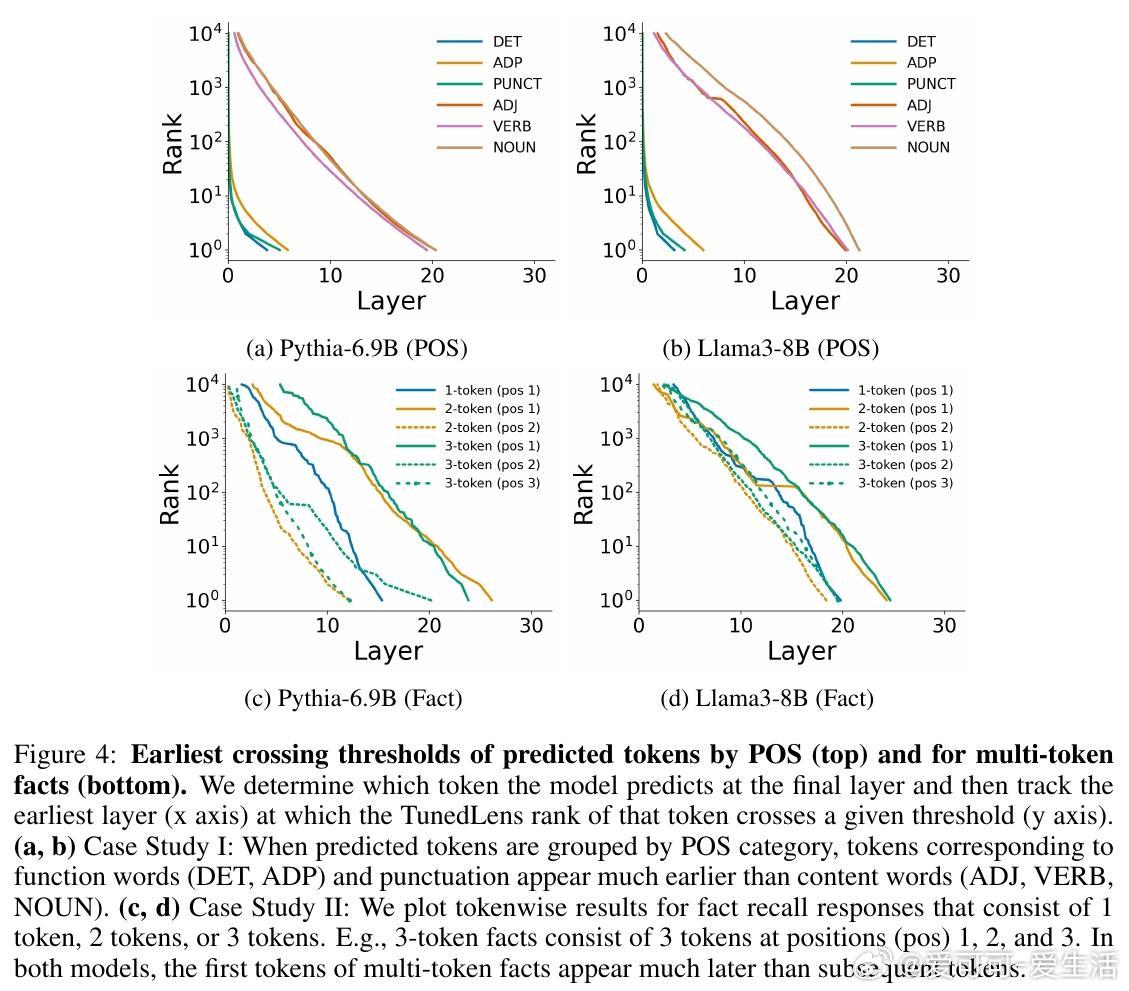
- 案例一:词性(POS)类别深度使用
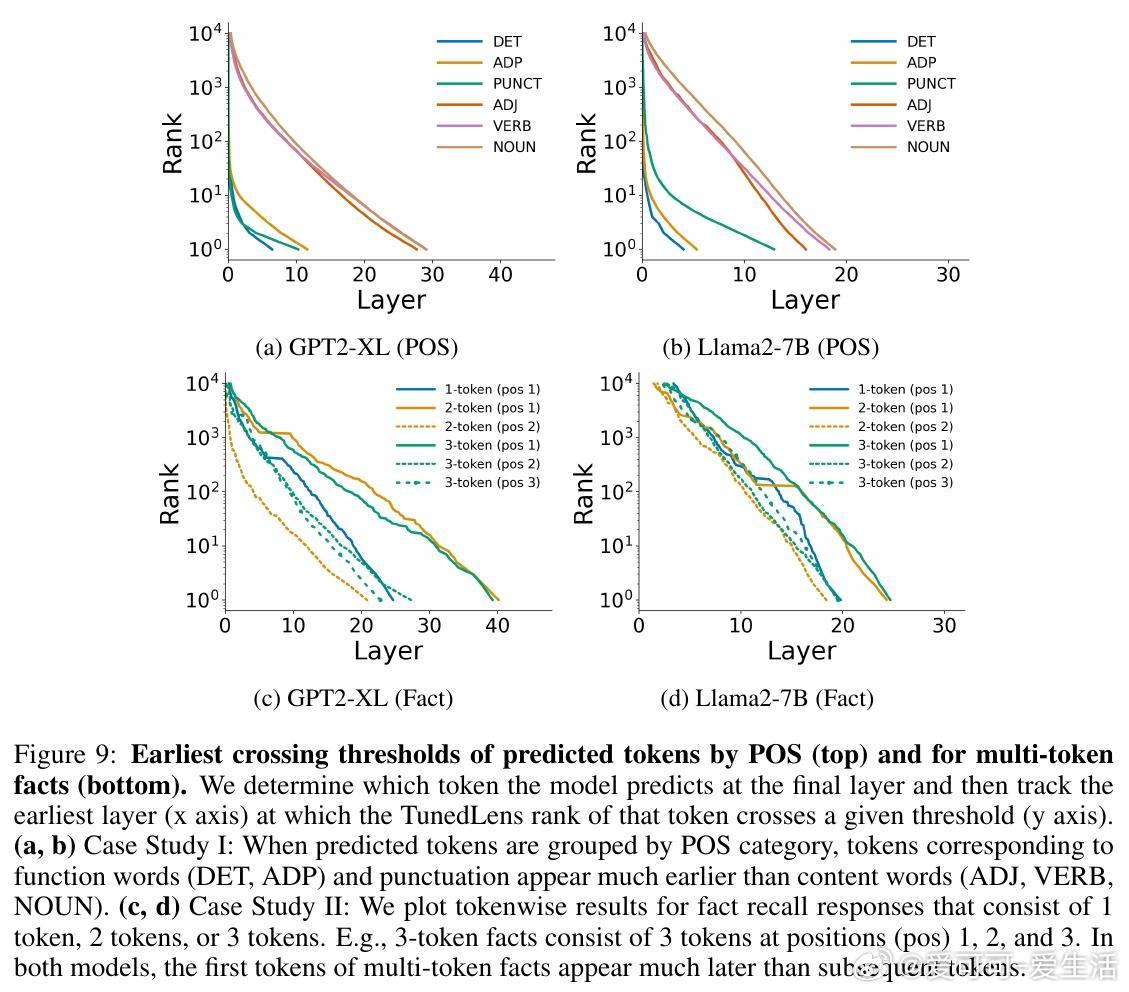
在下一token预测中,功能词(限定词DET、介词ADP)和标点(PUNCT)最早正确预测(约第5层达top-1),而内容词(形容词ADJ、动词VERB、名词NOUN)需更深层(约第20层)。这因功能词多为高频,易于猜测;内容词依赖上下文推理。
*思考*:这区分了“易预测性”与频率:即使控制频率,简单结构仍优先浅层处理,体现了LLM的层次化语言建模能力。启发:微调时,可针对内容词强化中层知识提取。
- 案例二:多token事实回忆
使用MQuAKE数据集,在正确回忆多token事实时(如“The Statue of Liberty is located in New York City”),首个token需最大深度(Pythia中约第27层),后续token更早出现(第20层和第12层)。单token事实也比多token易(第15层 vs. 第25层)。这表明首token涉及“方向选择”和前瞻规划(lookahead),计算负载更高。
*思考*:与现有研究(如事实存储在中层MLP)结合,这暗示LLM在回忆时进行隐式规划——后续token“条件易化”。但也暴露局限:多token任务易卡在首token,未来可探索层级解耦来提升长序列生成效率。
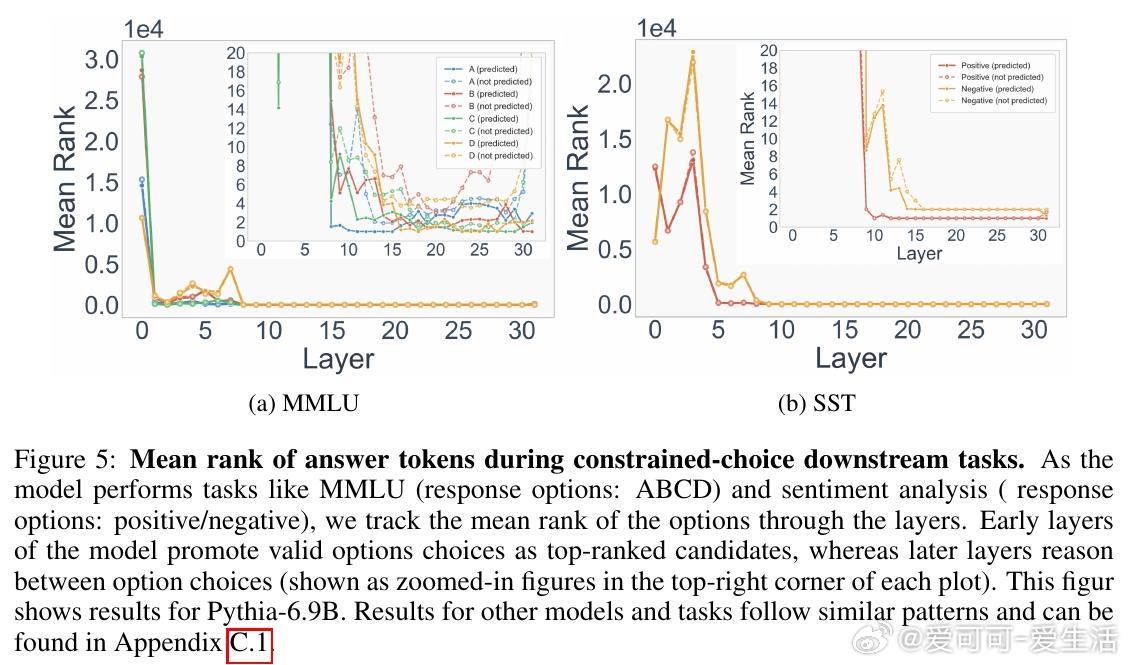
- 案例三:下游任务深度动态
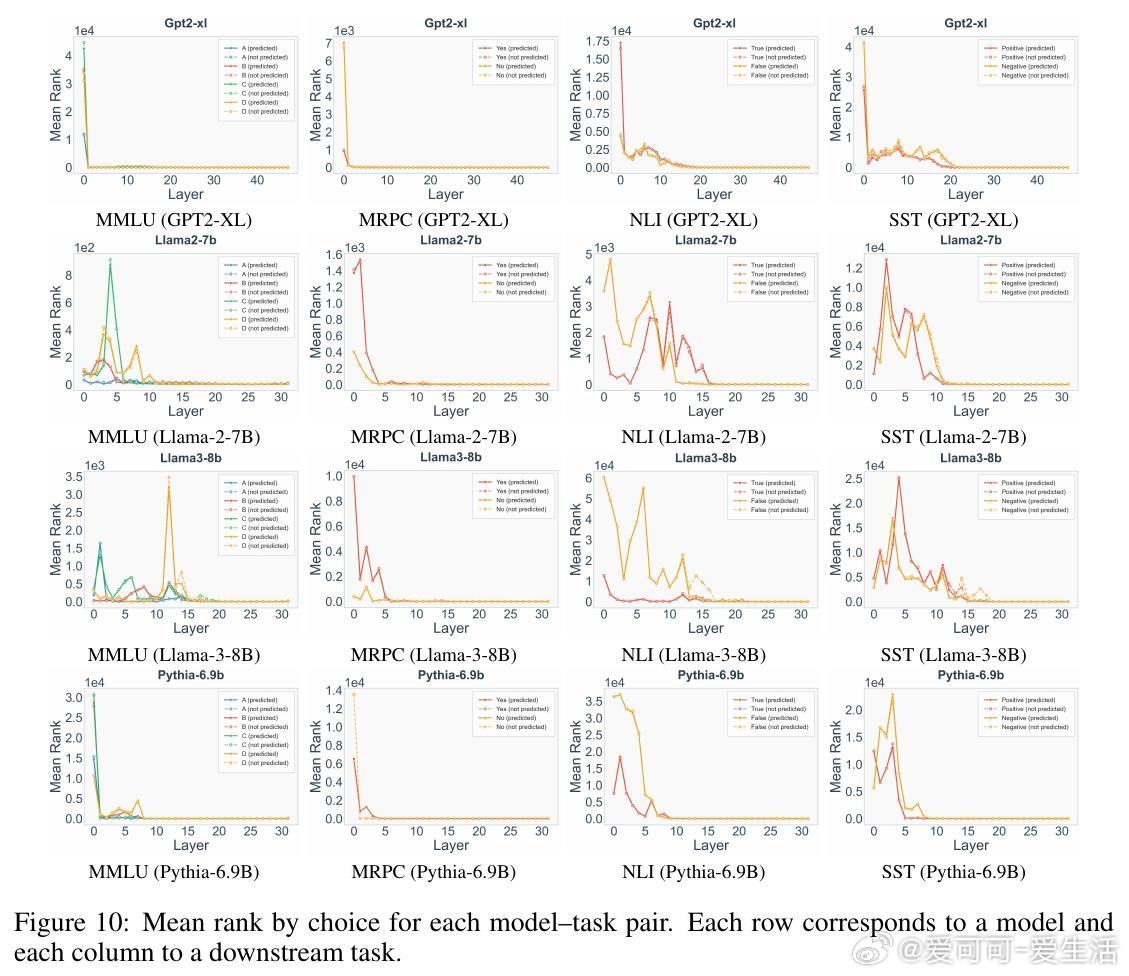
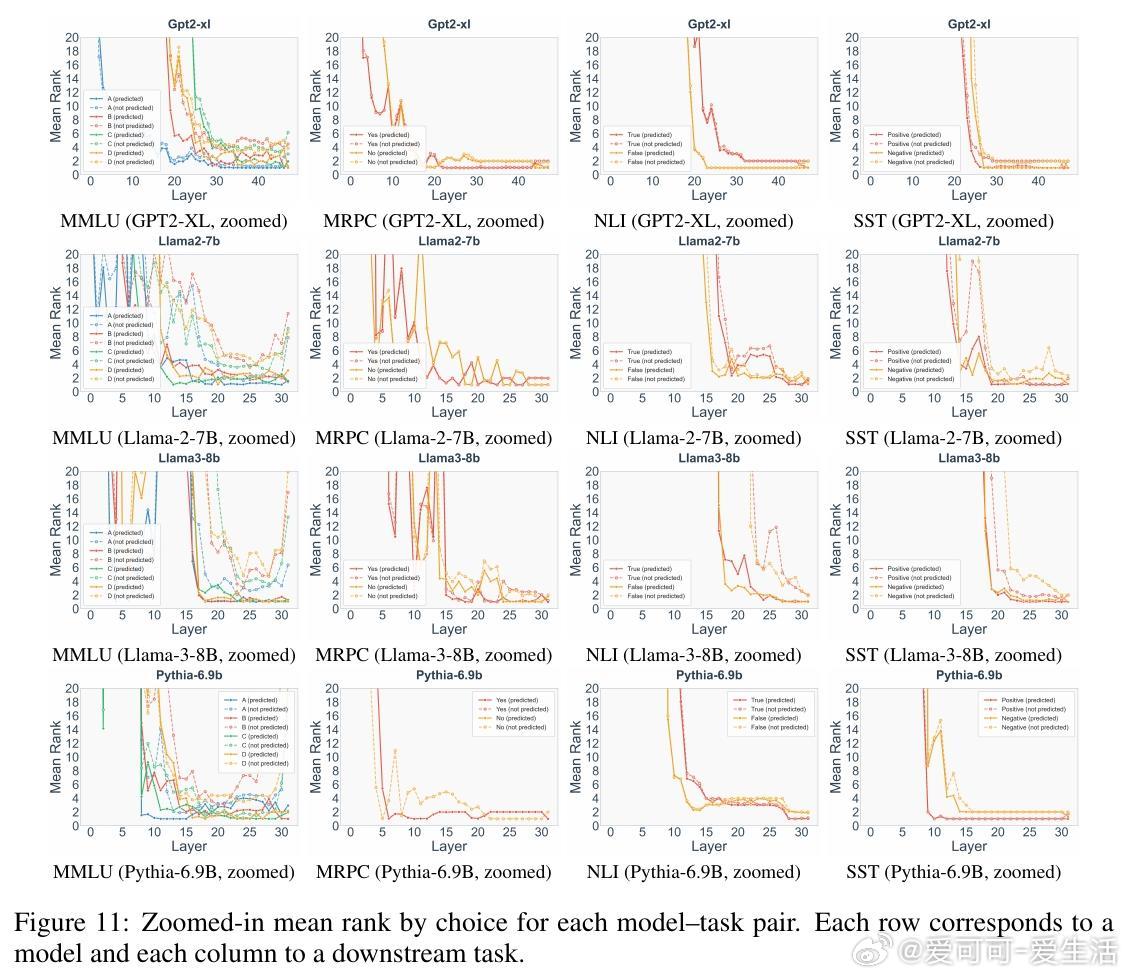
在多选题(MMLU)、情感分析(SST)等受限选项任务中(4-shot设置),浅层(前半模型)快速收集有效选项至top-rank(如ABCD选项排名急降),深层则在选项间推理(至最后一层)。例如,MMLU中浅层偏A,中层切换,深层定C/D;SST中默认“positive”直到末尾。
*思考*:任务分解为“收集-推理”两步,体现了复杂性驱动:浅层处理格式识别(易),深层做决策(难)。这为in-context learning提供新解释——浅层提升标签语义,深层检索与选择。实际应用中,可据此设计自适应推理,减少不必要计算,尤其在资源受限场景。
3. 验证与启示
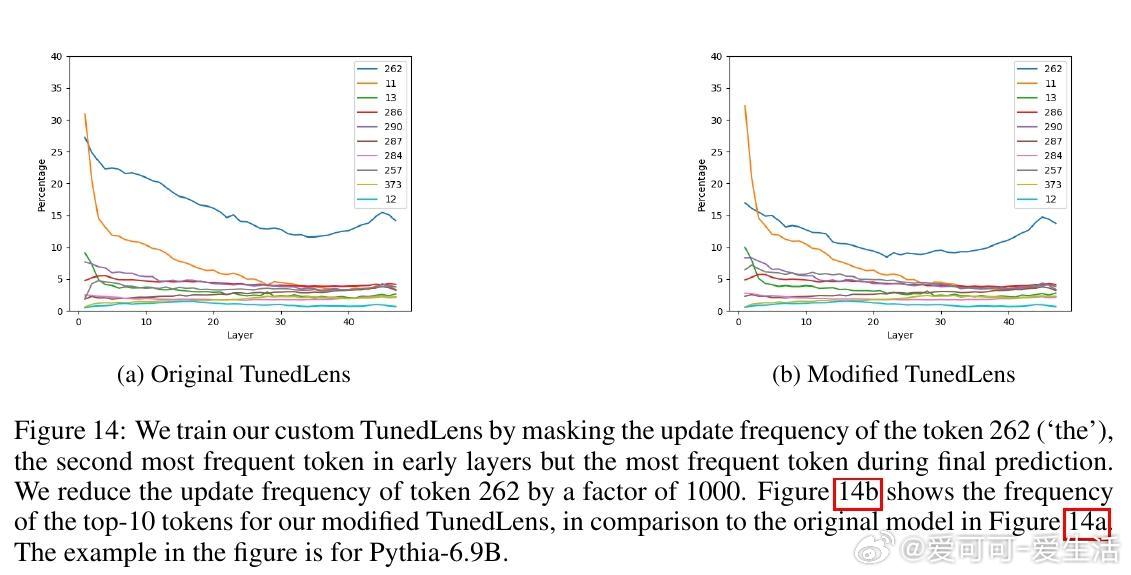
论文通过自定义TunedLens训练(降低高频token更新频率1000倍)和概率质量比较,证实结果忠实于模型内部,而非工具 artifact。与LogitLens对比,TunedLens更可靠,尤其浅层。相关工作链接了层级解码、事实回忆和动态深度研究,强调早期退出可能干扰精炼。
总体而言,这项工作展示了LLM的深度使用是结构化的、任务自适应的:浅层高效猜测,深层精准整合。更深层思考:这不仅深化了对transformer机制的理解,还为高效AI(如移动端LLM)指明方向——开发“复杂度感知”退出机制,能显著降低能耗而不牺牲准确性。代码开源:github.com/akshat57/how-do-llms-use-their-depth。
原论文链接:arxiv.org/abs/2510.18871



![全智贤在复制粘贴的时代,你是手写的诗[玫瑰]](http://image.uczzd.cn/12064986133026187123.jpg?id=0)