DeepSeek打破上下文魔咒!AI“记性”暴涨的秘诀太绝了 大模型终于能完整“读”完一本书了?DeepSeek刚甩出的新突破,直接砸破了长文本处理的“紧箍咒”! 以前用AI处理长文档简直是折磨:200页的年报得切成十几段喂进去,前半段的数据到后半段就“忘光”;学术论文里的公式和图表更是乱成一团,关联信息丢得稀里哗啦。这就是大模型的“上下文限制”——像给记忆装了容量锁,多一点信息就溢出来。 这次DeepSeek玩了个反常规操作:不硬扩容量,而是给信息“榨干水分”!新出的DeepSeek-OCR模型把文本转成图像压缩,就像把厚书做成精致索引卡,10倍压缩后还能保持97%的解码精度,几乎无损。 这招有多神?处理286页的上市公司年报,以前得切6段耗时29分钟,现在单轮4分12秒就搞定,表格数据误差还不到0.3%。连带45个复杂公式的Nature论文,都能精准转成可复制的格式,比传统工具准确率高16个百分点。更关键的是,普通A100显卡就能跑,显存占用直接省了68%。 别以为这只是“认字工具”,它本质是给大模型装了“超级大脑”。通过“文本转图像-压缩-解码”的流水线,原本只能装32K tokens的设备,现在能塞下320K,相当于600页PDF。律师审合同、分析师扒财报、研究员读论文,都不用再跟“断档记忆”较劲了。 你以前用AI处理长文本时,是不是也被“记不住前文”坑过?这波技术突破,你觉得最先能帮到哪个行业?来评论区聊聊你的经历!

这下我知道为啥AI取代不了医护了
【2评论】【8点赞】
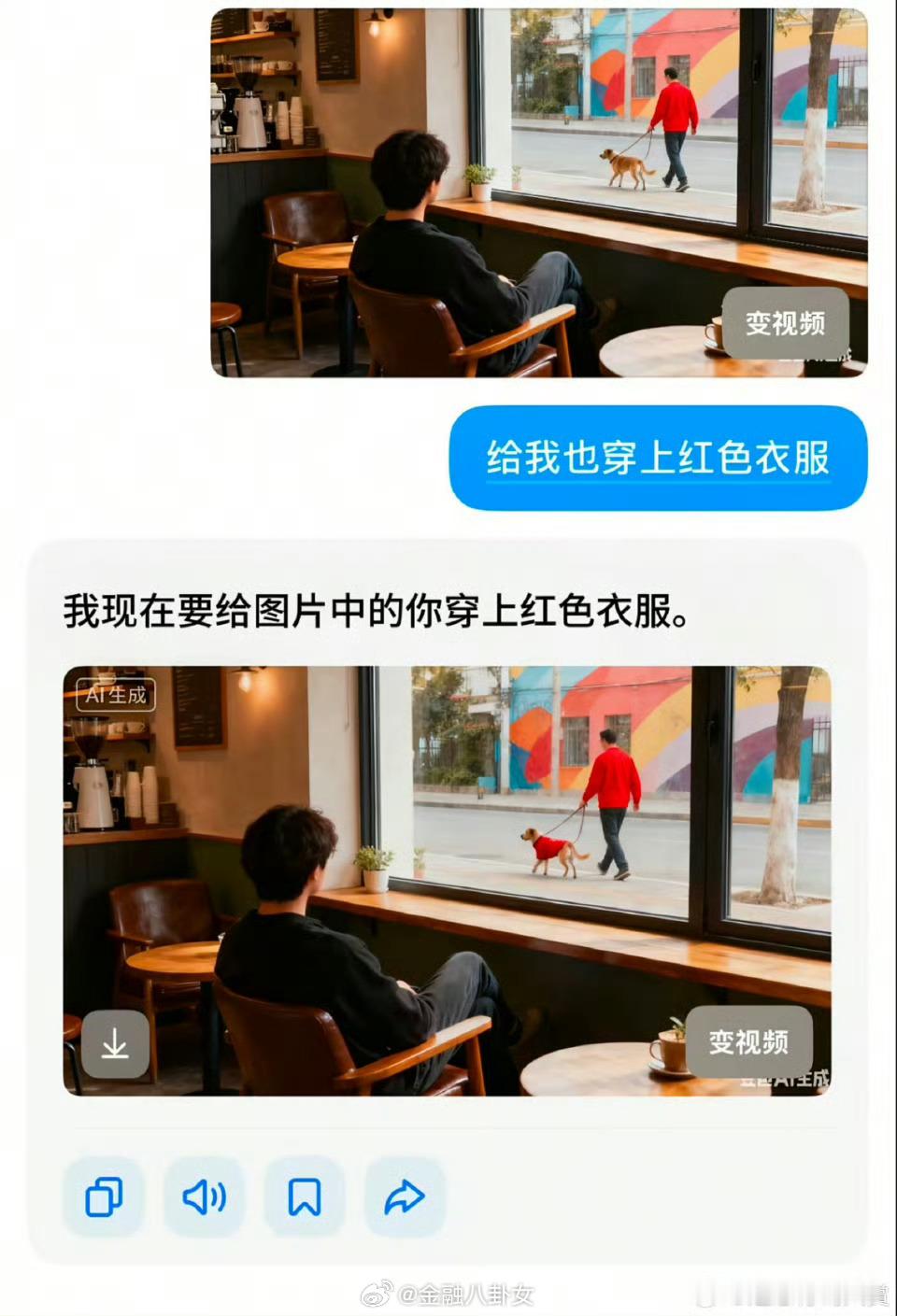





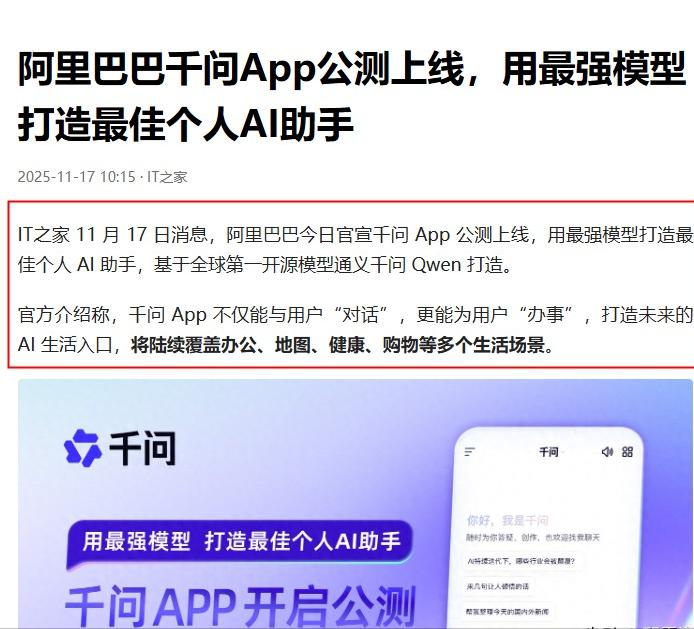

舒逸飞
那就很厉害了,那些问四大名著的细节问题的。就难不倒人了。