[LG]《Asking Clarifying Questions for Preference Elicitation With Large Language Models》A Montazeralghaem, G Tennenholtz, C Boutilier, O Meshi [Google] (2025)
用扩散模型思路训练大语言模型(LLM)提问,精准挖掘用户偏好
推荐系统中,如何在缺少用户历史数据时准确获取用户偏好,是个难题。最新研究《Asking Clarifying Questions for Preference Elicitation With Large Language Models》提出了创新方法,借鉴图像扩散模型思路,训练LLM通过「递进式漏斗提问」逐步还原完整用户画像。
核心思路:
1️⃣ 将用户文本画像转为结构化JSON数据,按从具体到抽象排序。
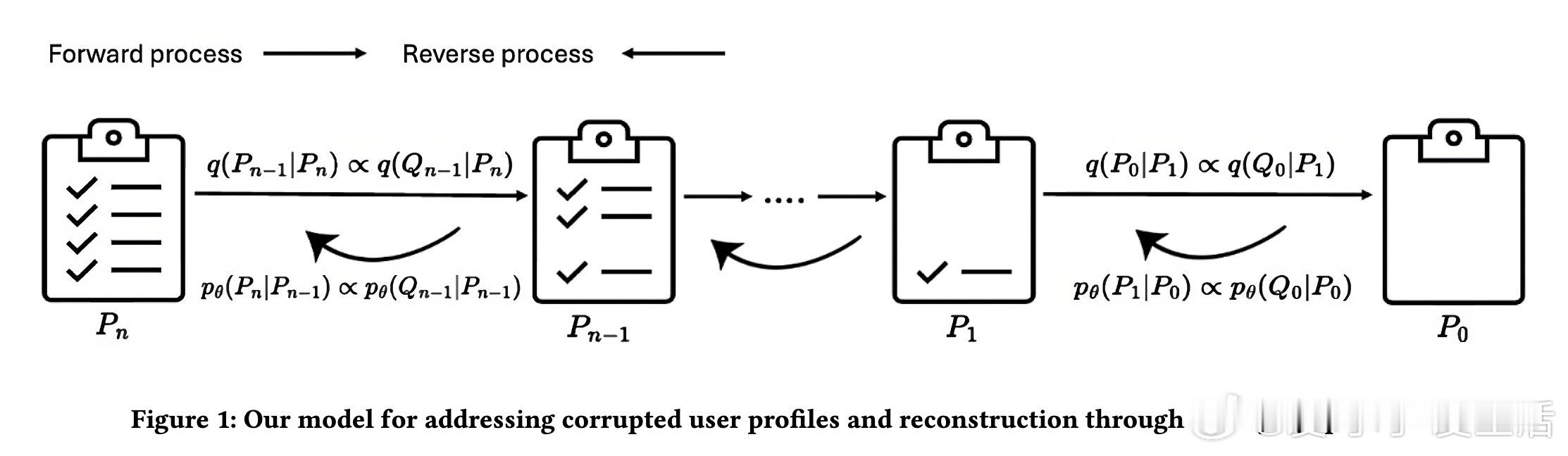
2️⃣ 正向过程:逐步删除画像信息,并为每条被删信息生成对应的澄清问题,形成训练数据。
3️⃣ 逆向过程:训练LLM根据局部画像生成有效的澄清问题,逐步“去噪”恢复完整用户画像。
4️⃣ 训练中还配备了用户模拟器(同为LLM),用以自动回答问题,模拟真实对话环境。
亮点与贡献:
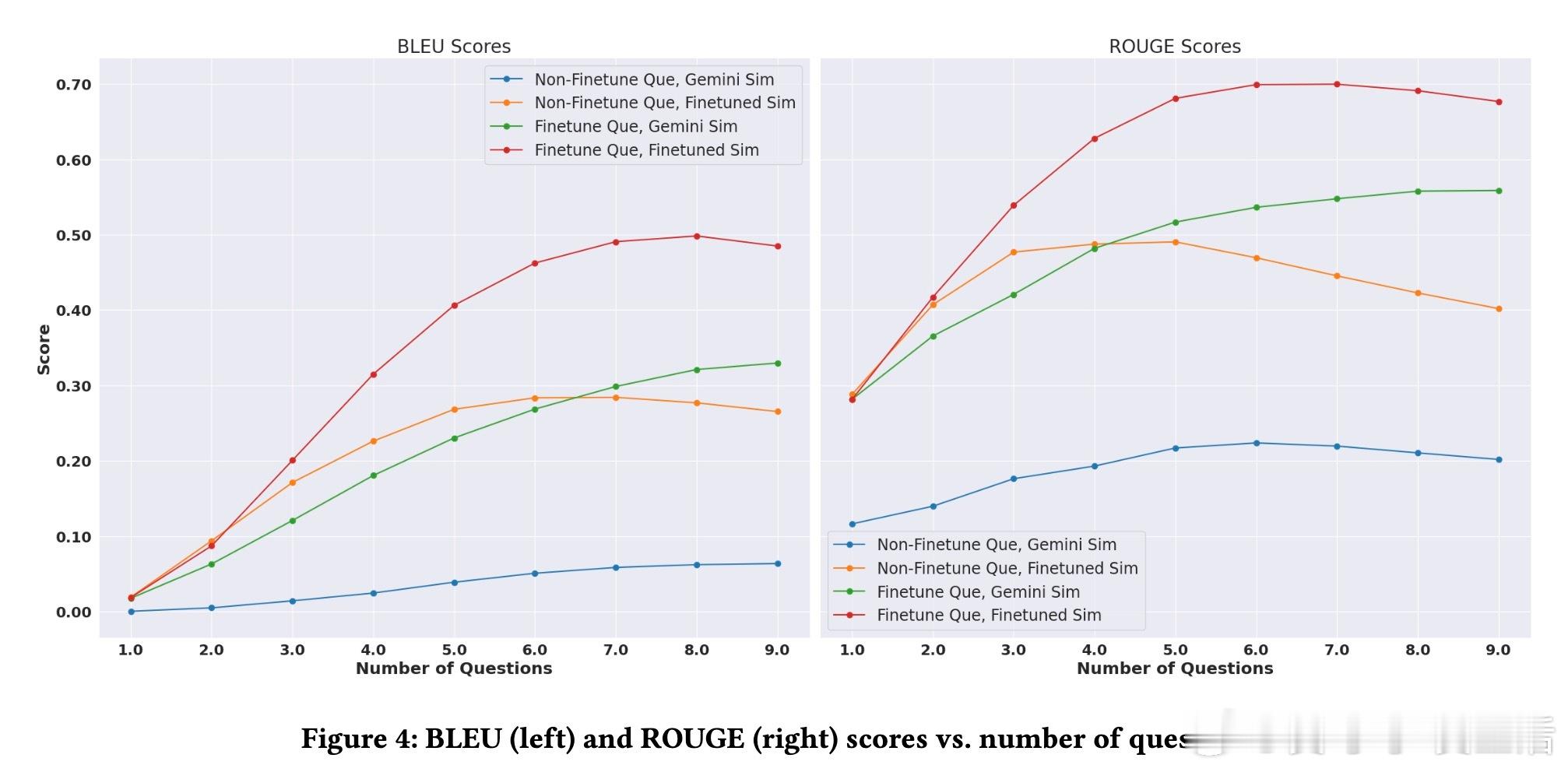
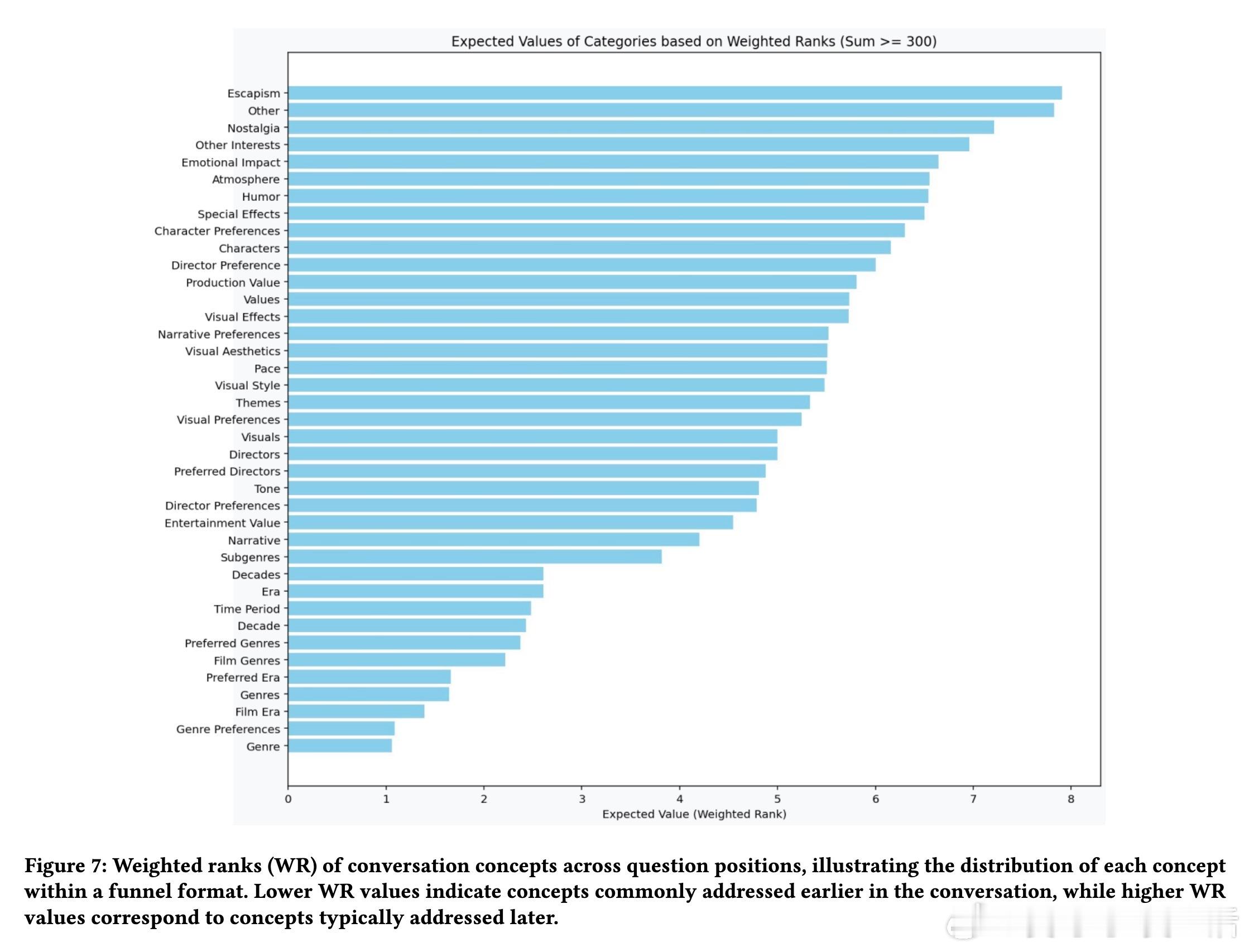
✔️ 生成的澄清问题遵循漏斗顺序,先问广泛概念(如“偏好哪类电影?”),后逐渐细化(如“喜欢导演X的作品吗?”),对话更自然高效。
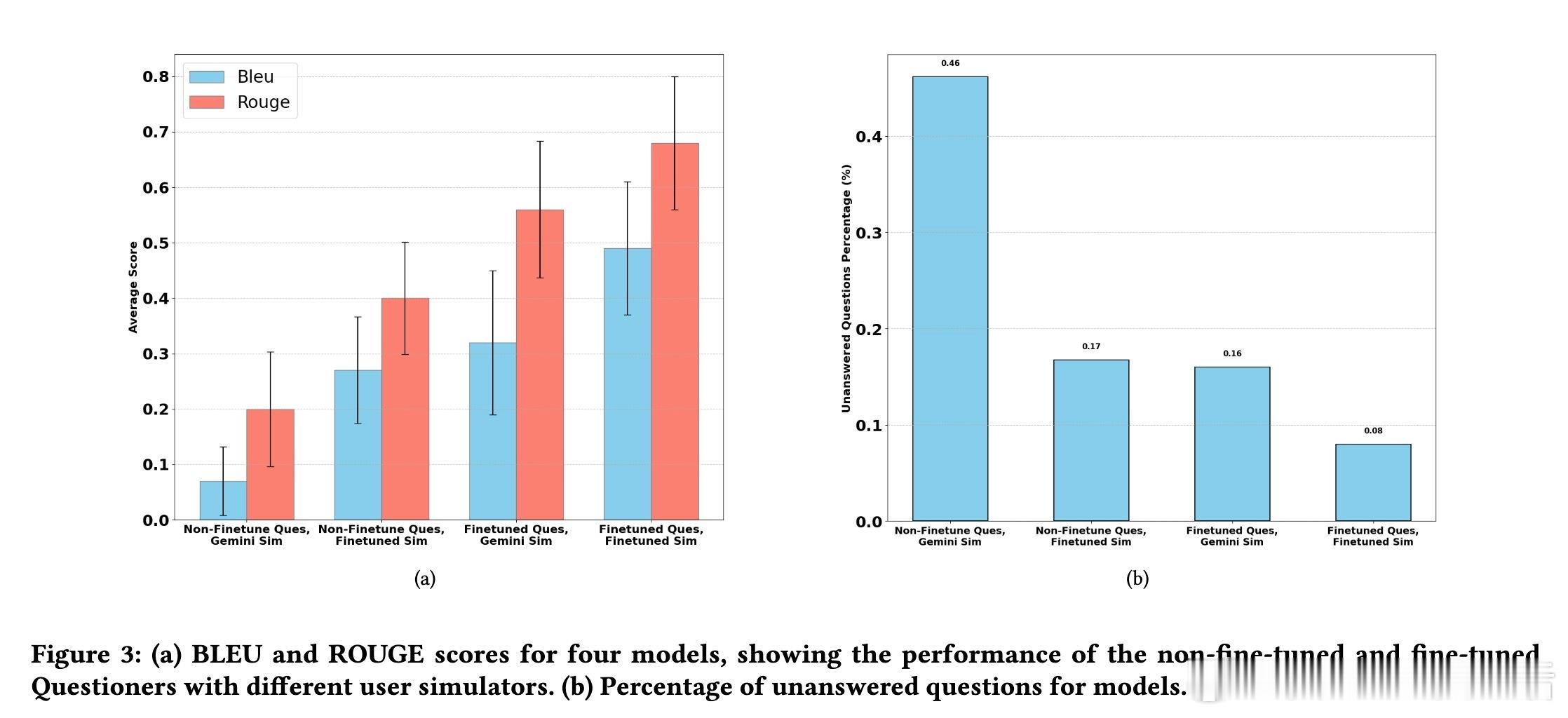
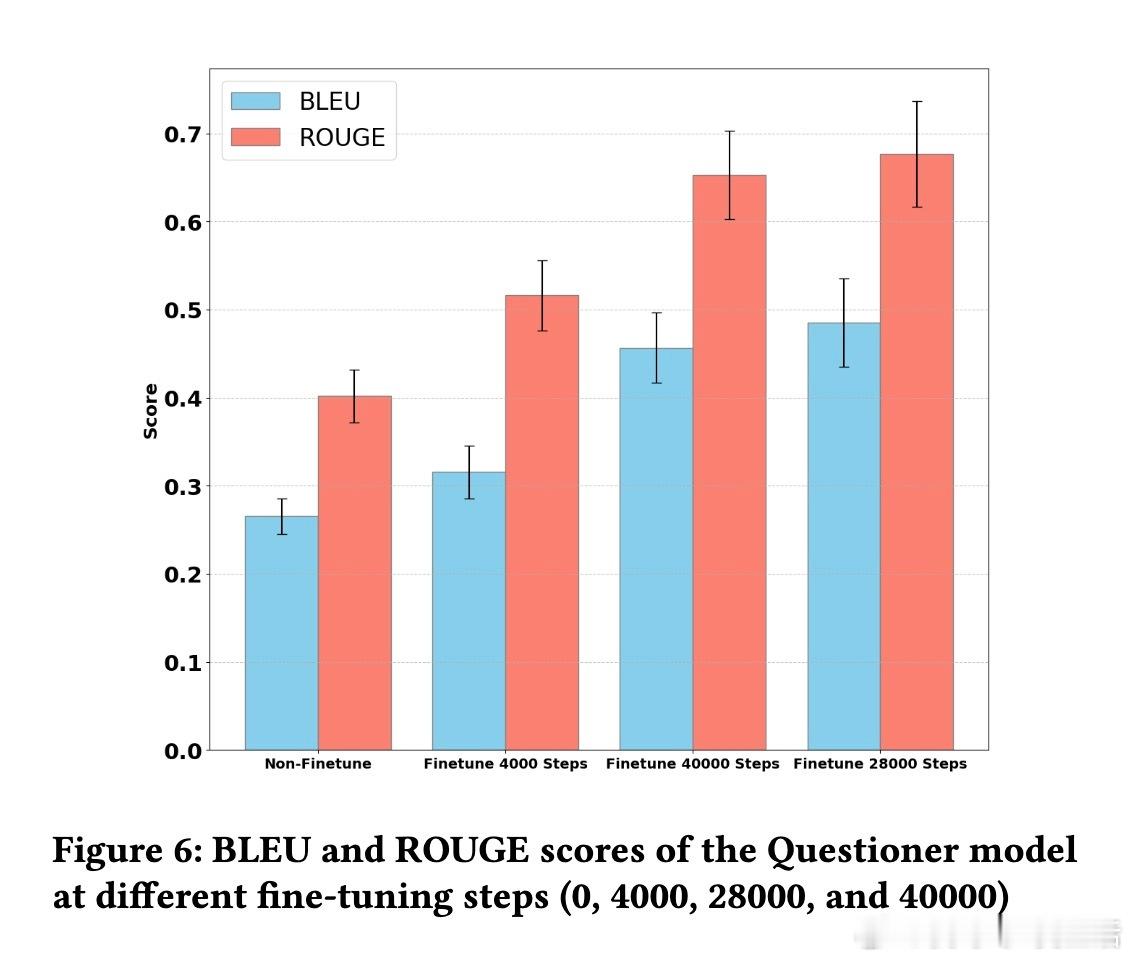
✔️ 实验采用Movielens电影数据集,基于Gemma和Gemini大语言模型,结果显示该方法显著提升了提问的针对性和用户画像还原度(ROUGE、BLEU指标均大幅提升)。
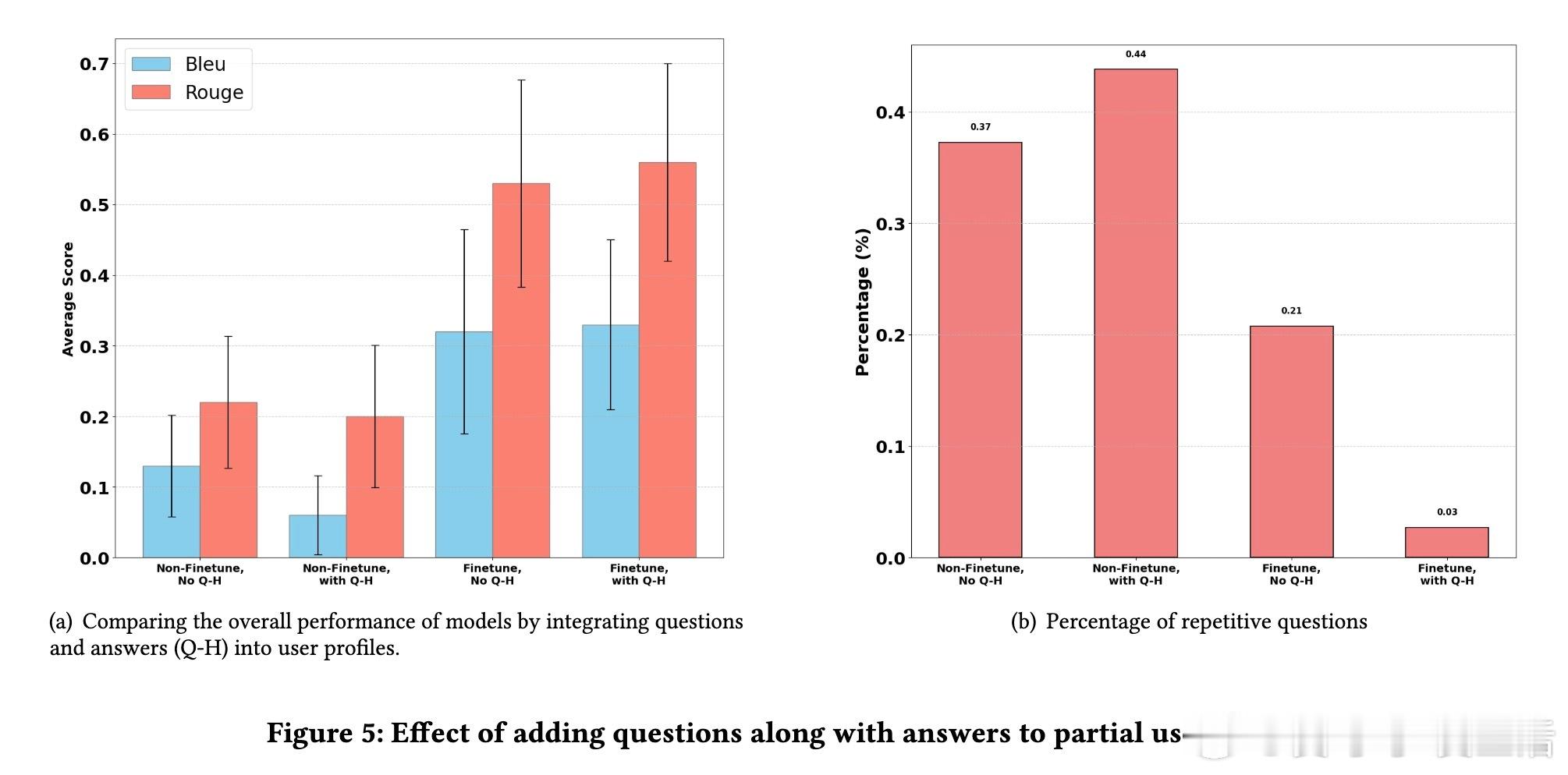
✔️ 细节优化:在用户画像中同时加入提问和回答,避免重复提问,提高问答质量。
✔️ 该框架可拓展至多领域、隐私受限、无历史数据等多种现实推荐场景。
研究意义:
✅ 通过引入扩散模型的“正向破坏—逆向还原”理念,开辟了LLM主动式偏好采集的新路径。
✅ 促进推荐系统与对话系统的深度融合,提升个性化推荐的精准度与用户体验。
✅ 为未来自适应学习和多轮交互的智能系统提供理论和实践基础。
全文链接:arxiv.org/abs/2510.12015
这项研究为如何让大语言模型更聪明地提问、理解用户需求带来了新思路,值得推荐系统和对话AI领域的同学深入关注!
大语言模型 扩散模型 推荐系统 用户偏好 对话系统 AI研究