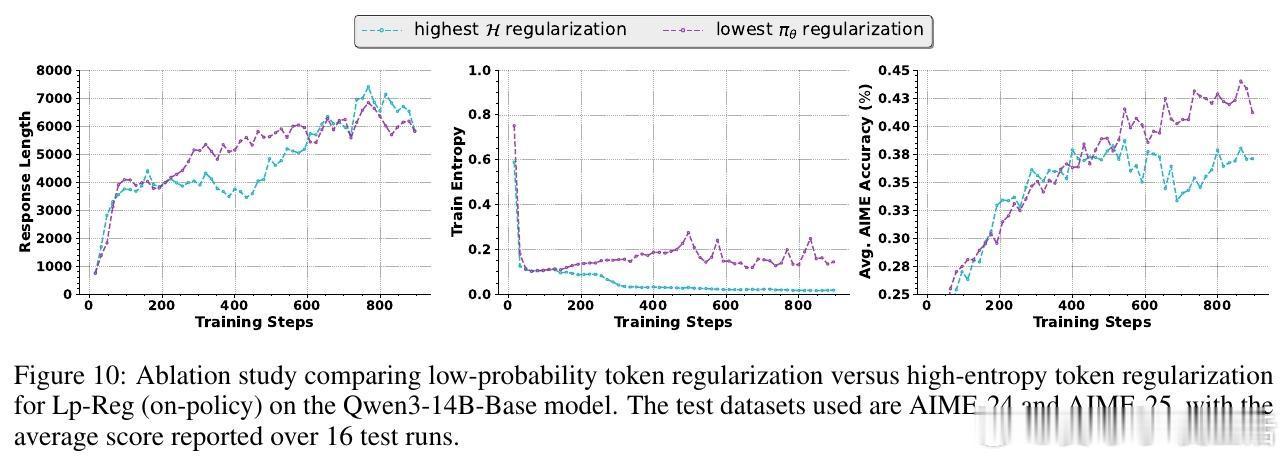
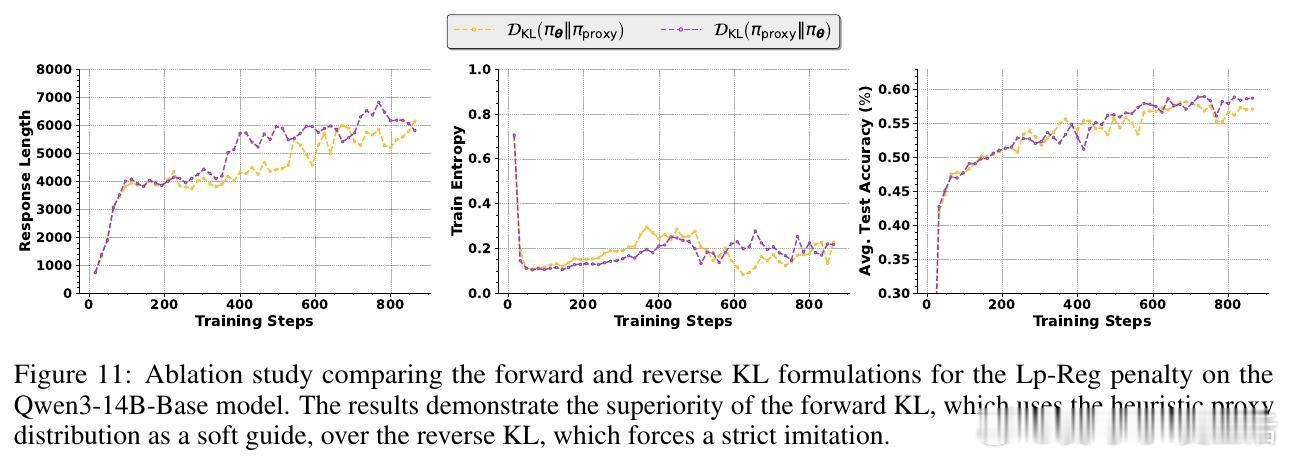
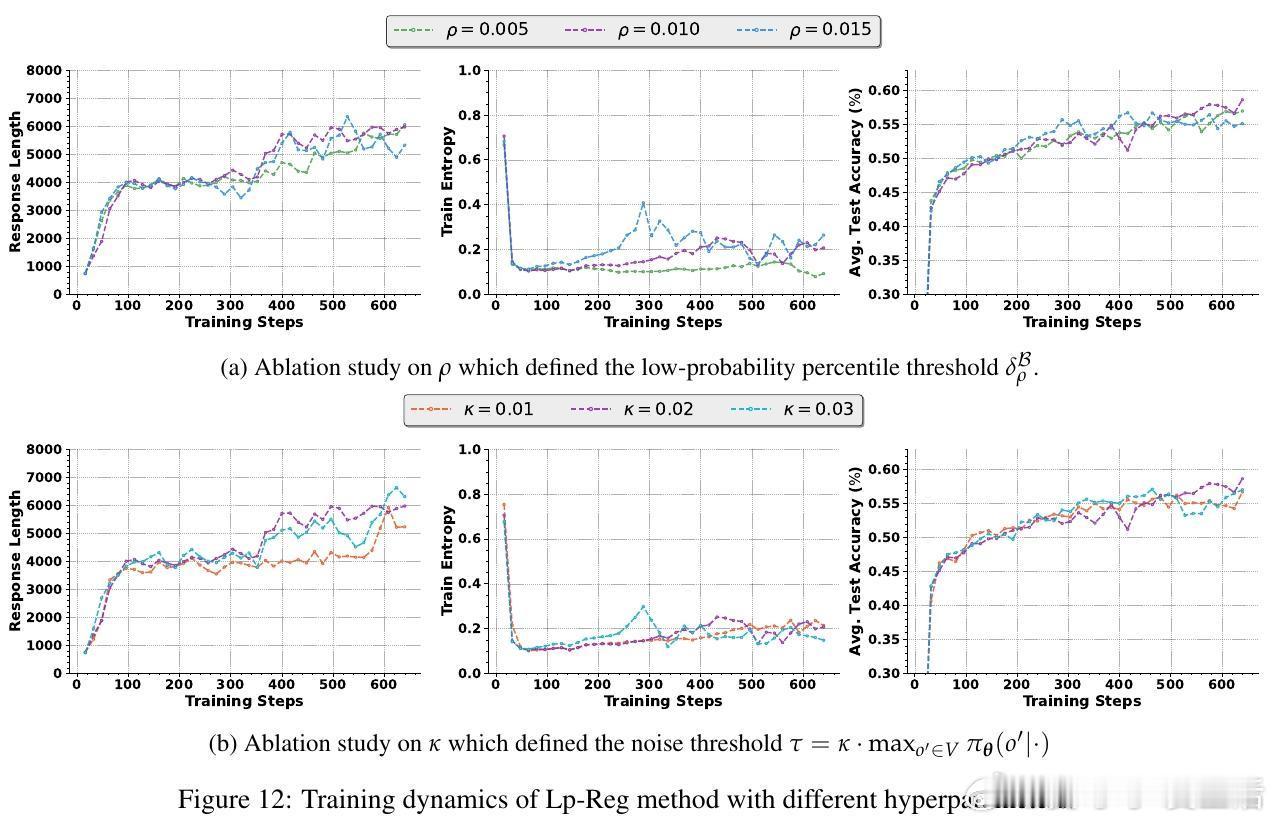
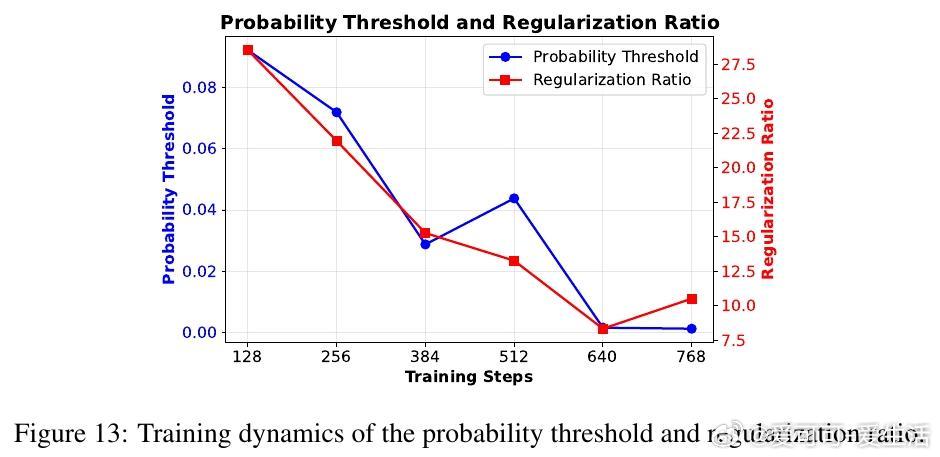
[LG]《Low-probability Tokens Sustain Exploration in Reinforcement Learning with Verifiable Reward》G Huang, T Xu, M Wang, Q Yi... [Tencent] (2025)
《低概率Token助力可验证奖励强化学习中的探索》
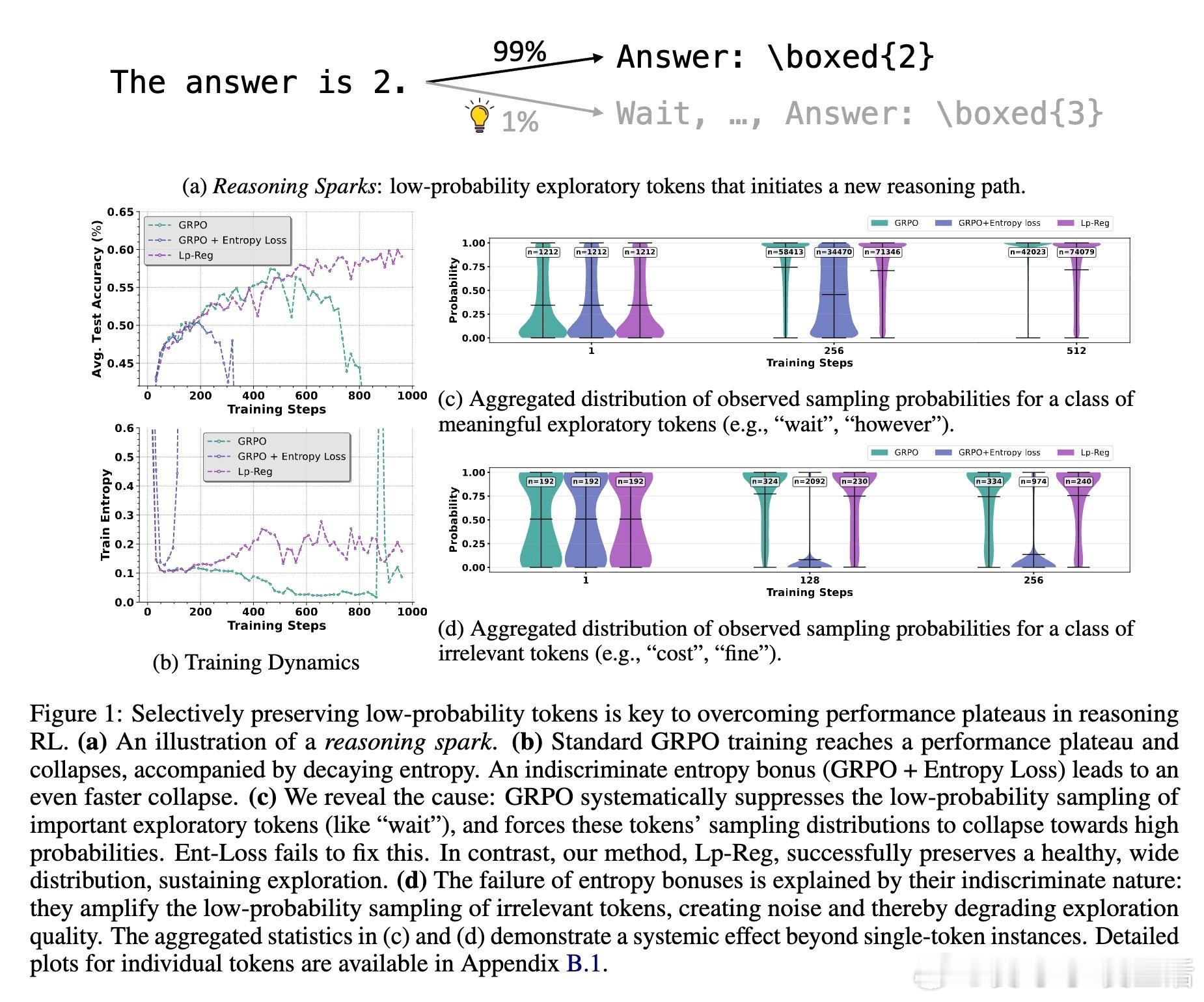
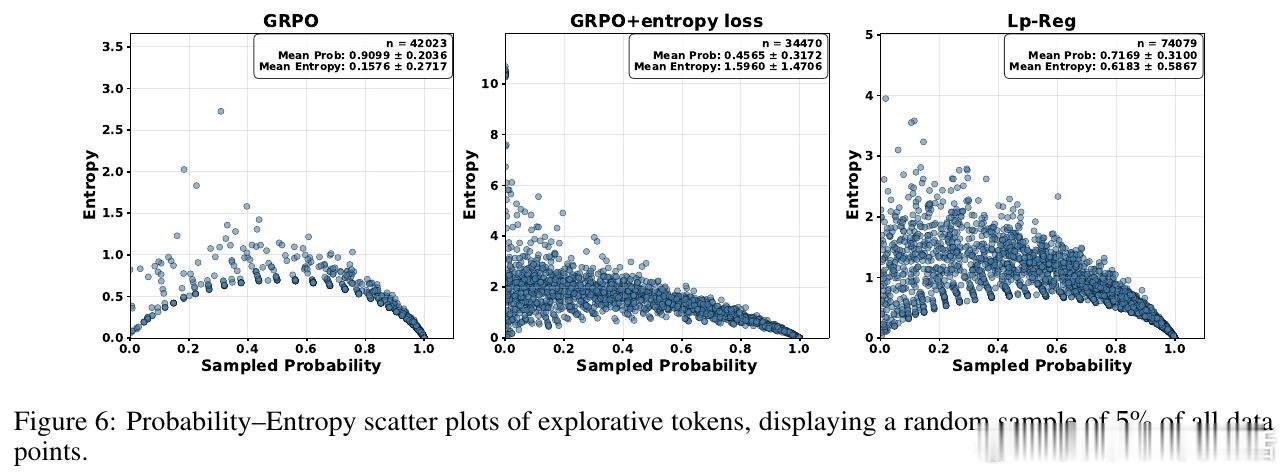
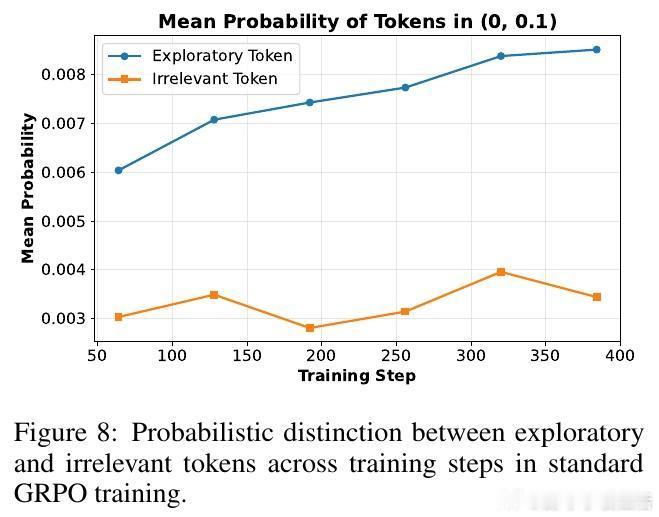
传统方法维护高策略熵以防止探索崩溃,却忽视了“推理火花”——那些低概率但关键的探索令牌。论文首次揭示这些令牌在训练中被过度惩罚,导致性能瓶颈。
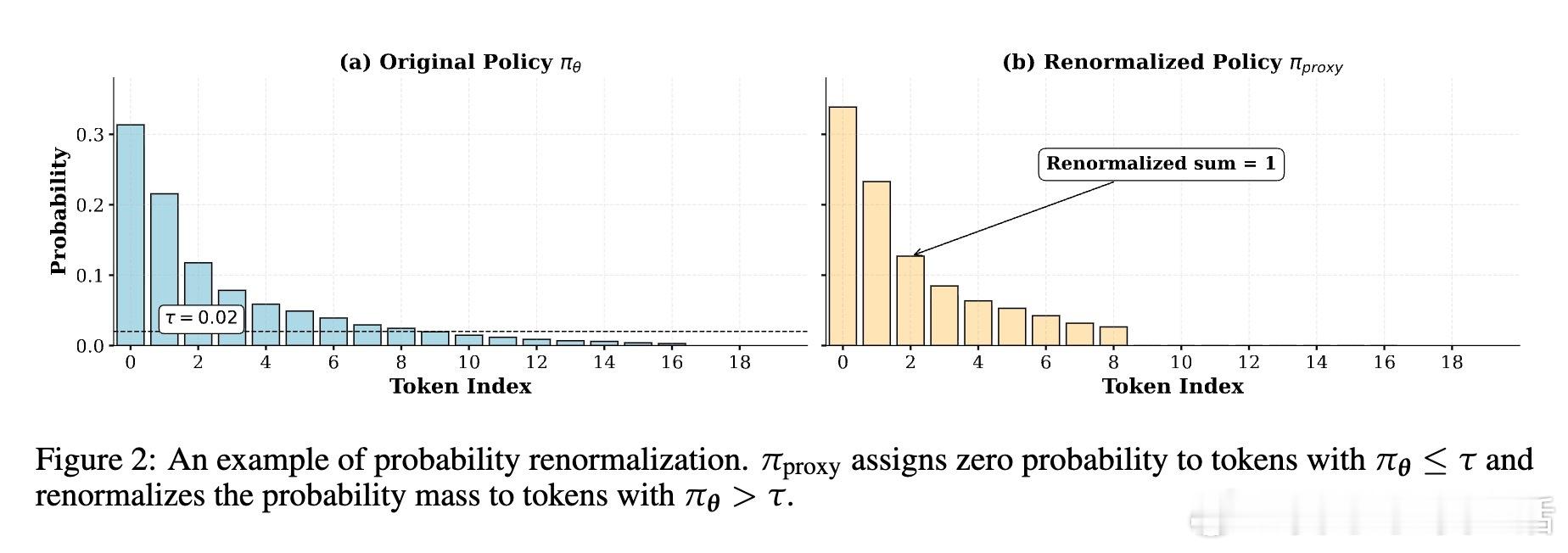
🔍核心创新:提出“低概率正则化”(Lp-Reg)方法,通过构建过滤噪声后的代理分布,保护这些宝贵的低概率令牌不被抹杀。此方法避免了盲目提升熵带来的噪声放大,稳定训练过程。
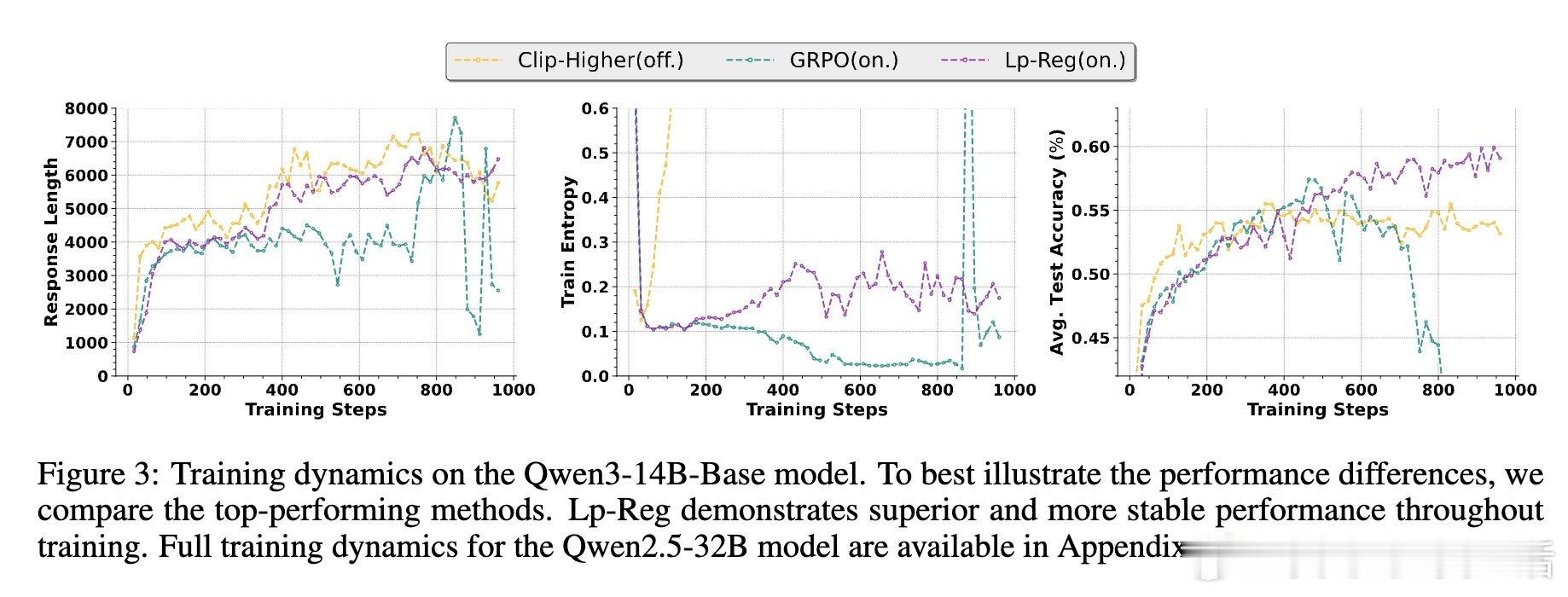
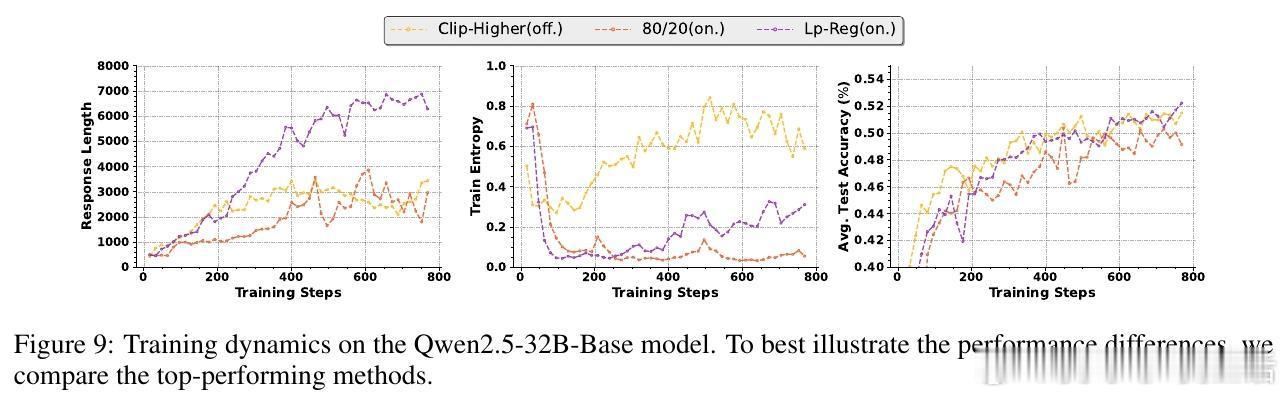
🎯实验结果:Lp-Reg在五个数学推理基准上,将Qwen3-14B模型的平均准确率提升至60.17%,较前沿方法提升2.66%。不仅性能领先,还显著延长训练稳定期,突破了以往方法1000步即崩溃的瓶颈。
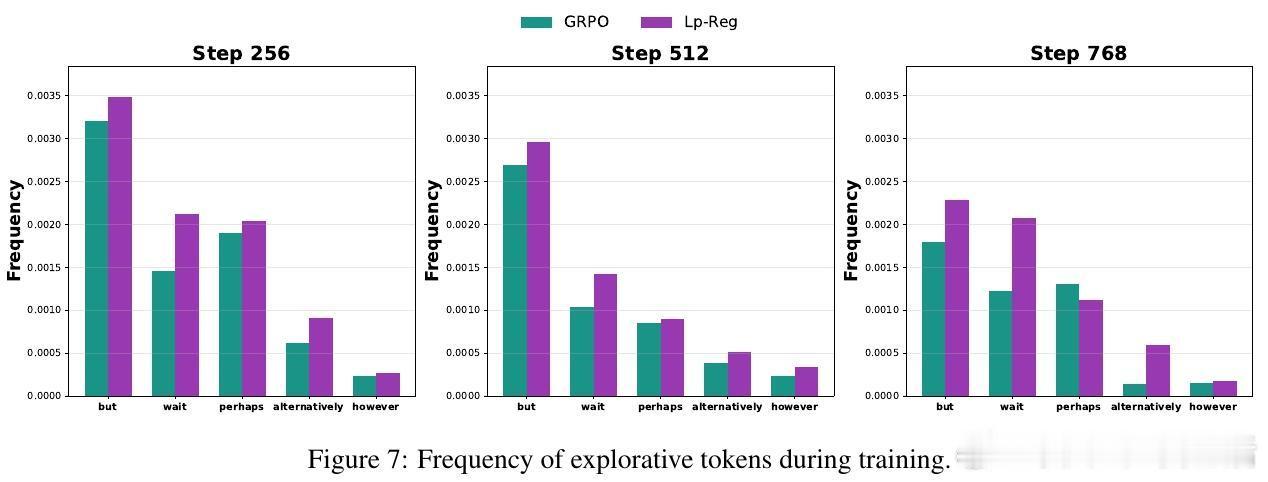
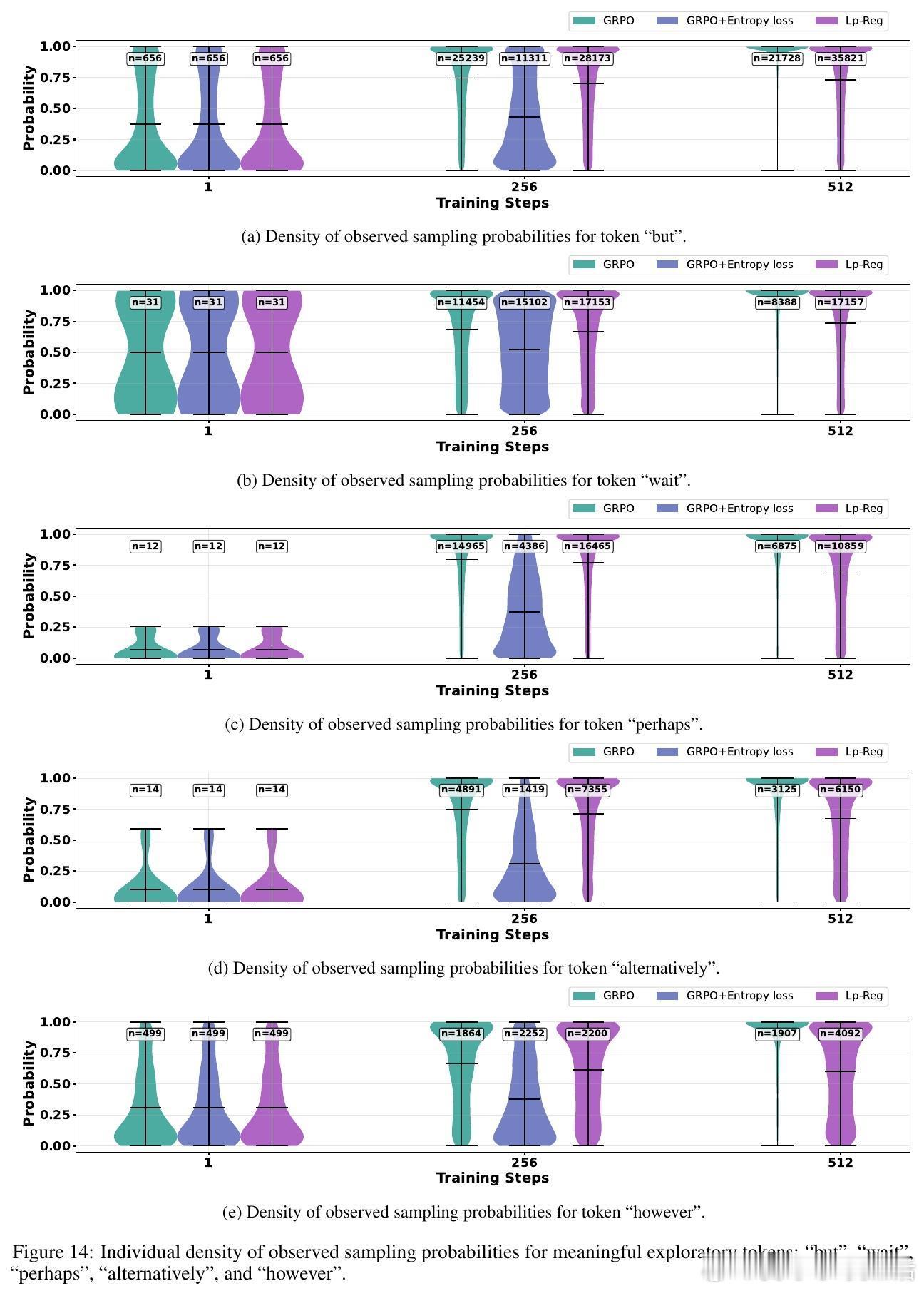
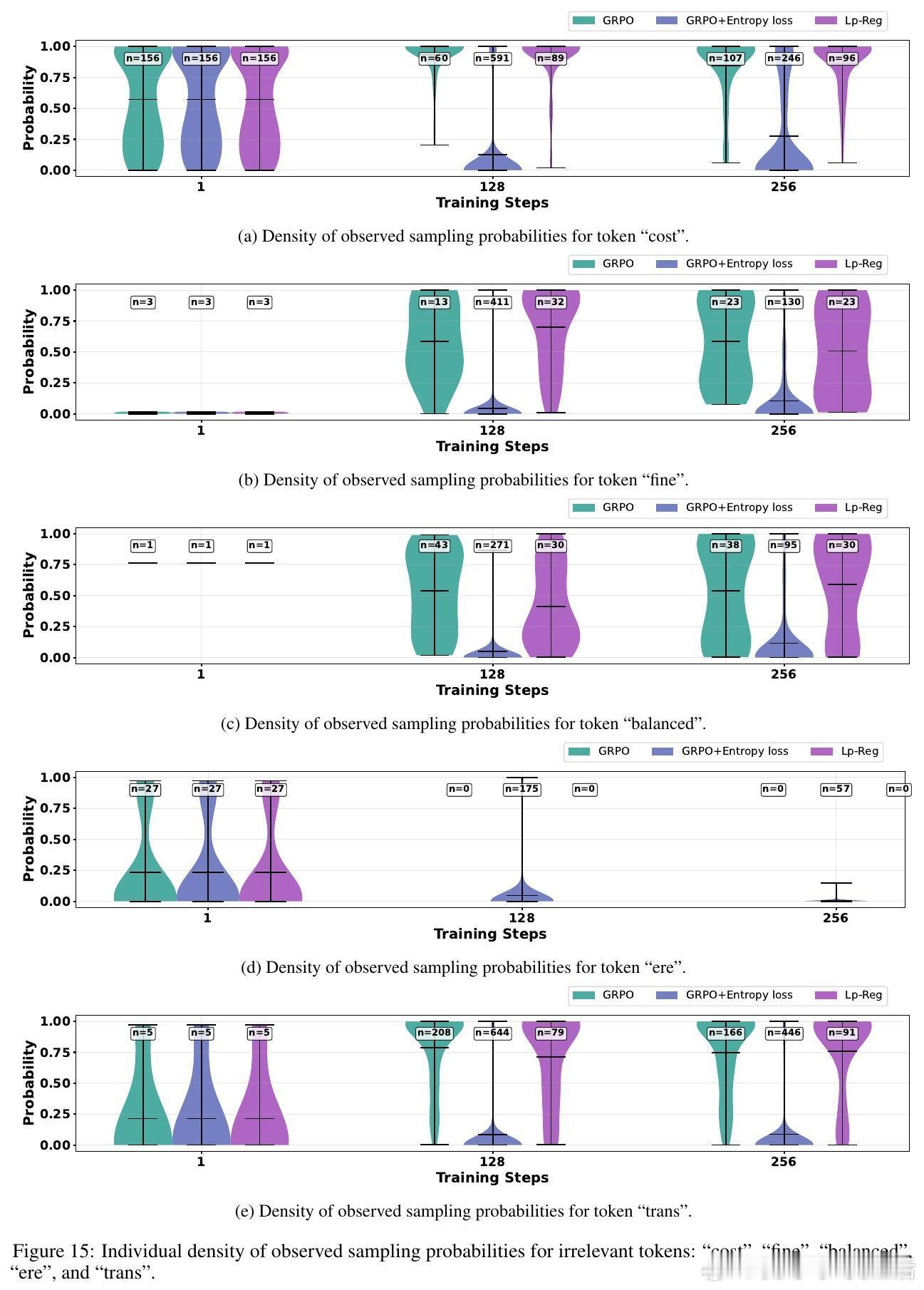
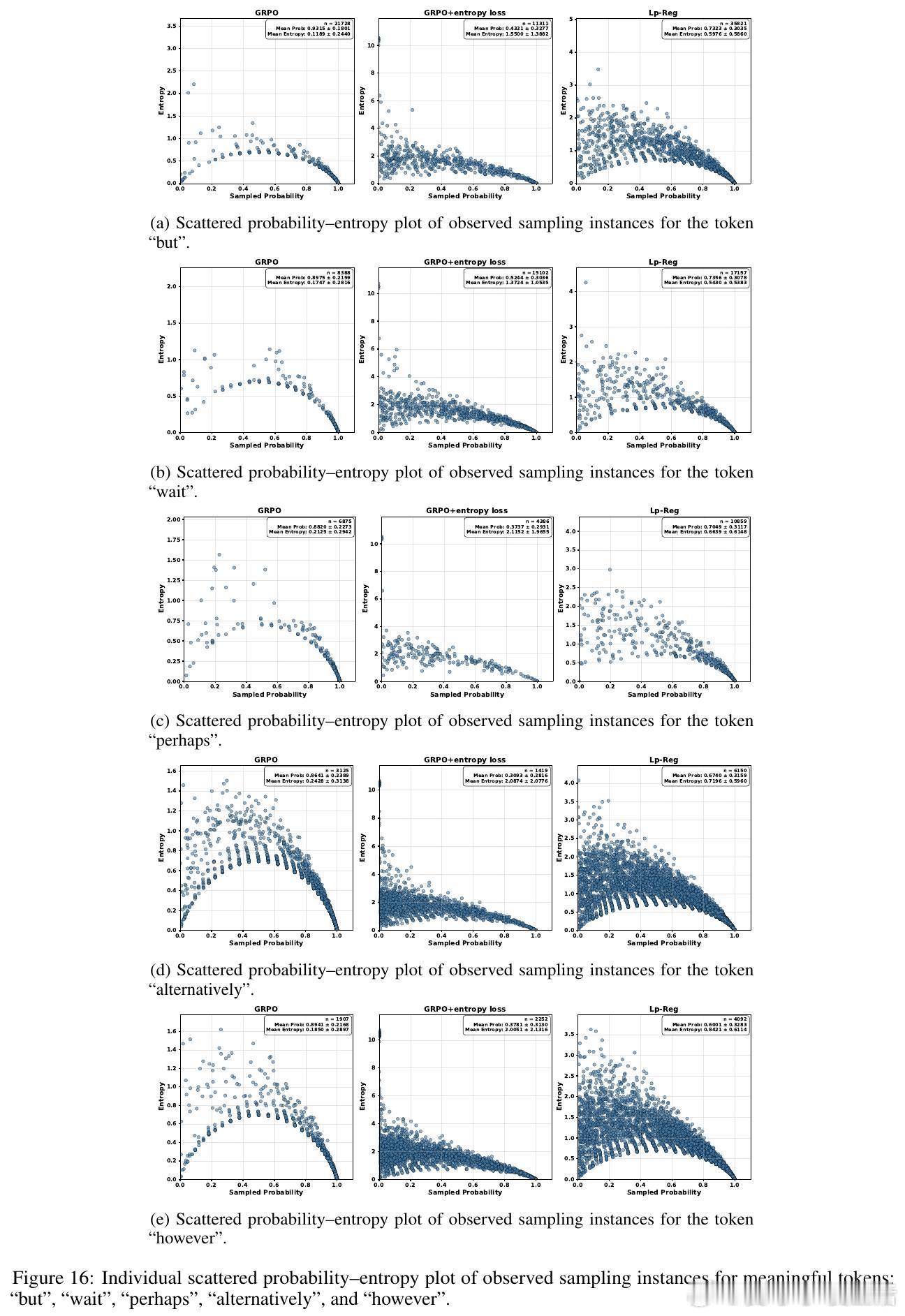
💡深度洞察:低概率令牌多为“不过”、“或许”等引导多样思路的连接词,而无辨别的高熵正则会放大无关噪声如“费用”等,反而加速性能崩溃。Lp-Reg依赖模型内在信心区分有用探索与噪声,精准保护探索质量。
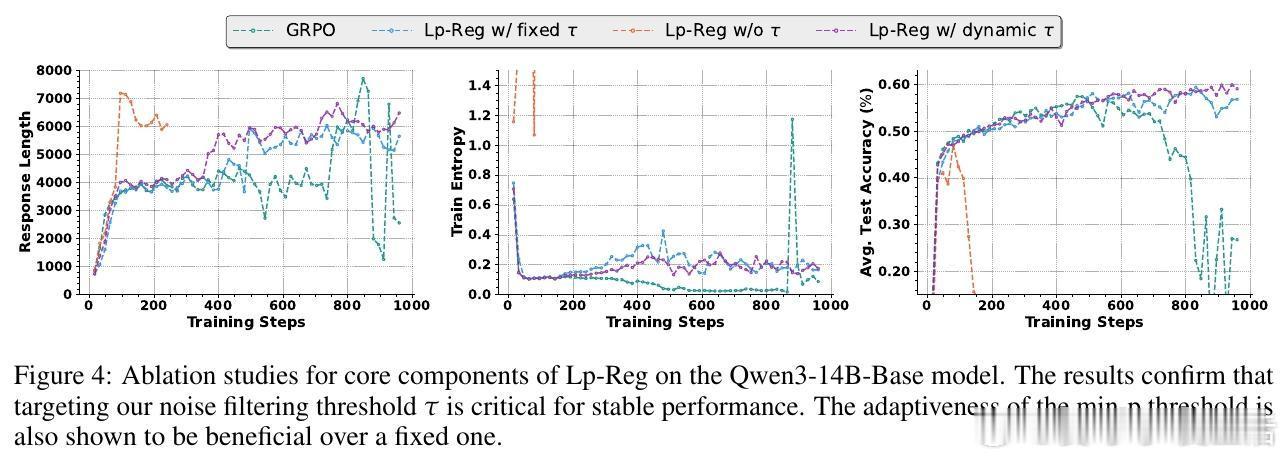
📈技术优势:该方法兼容多种训练范式(on-policy/off-policy),无需复杂调参,适应性强。且基于前向KL散度的软正则设计,使模型既能稳定保留关键探索令牌,也保持一定自由度。
🌐开源地址:
此研究不仅推动了可验证奖励强化学习的探索机制理解,也为复杂推理任务中LLM的训练稳定性和性能提升提供了新范式。探索不止,智慧长存!
原文链接:arxiv.org/abs/2510.03222
强化学习 大语言模型 探索机制 可验证奖励 机器学习 人工智能