[LG]《Polychromic Objectives for Reinforcement Learning》J I Hamid, I H Orney, E Xu, C Finn... [Stanford University] (2025)
【论文解读】《Polychromic Objectives for Reinforcement Learning》来自斯坦福,探讨了强化学习微调(RLFT)中探索多样行为的重要性及挑战。传统RLFT往往导致“熵坍缩”,策略过早集中于少数高回报行为,丧失多样性和探索能力,限制了策略的泛化和扩展能力。
💡核心贡献:
1️⃣ 提出“集合强化学习”(Set RL)框架,目标不再是单条轨迹最大化回报,而是优化一组轨迹的综合表现,兼顾成功率和多样性。
2️⃣ 引入“多彩目标”(Polychromic Objective),结合奖励和多样性指标,鼓励策略保持并挖掘多样的高质量行为。
3️⃣ 设计“多彩PPO”(Polychromic PPO),在PPO基础上利用vine采样收集多组轨迹,并调整优势函数,实用高效优化多彩目标。
🔬实验验证:
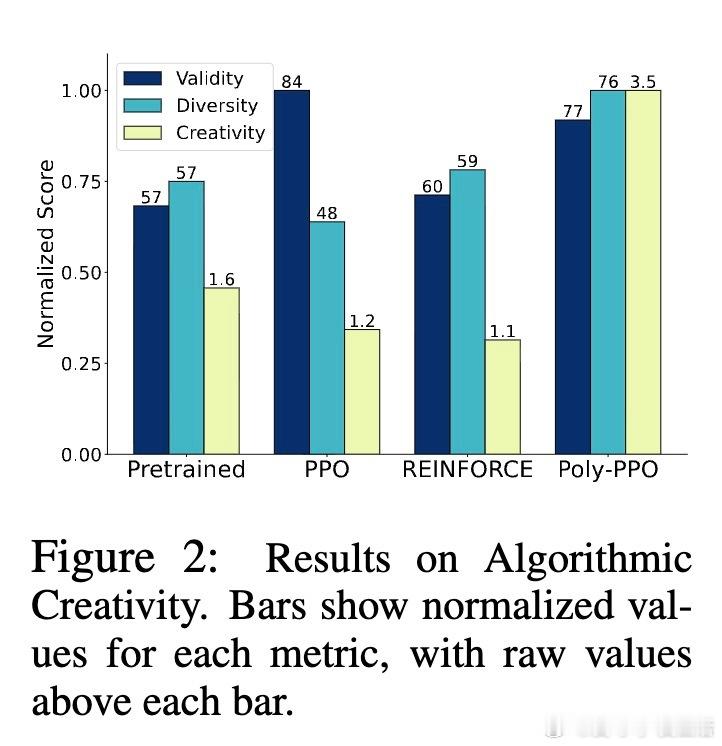
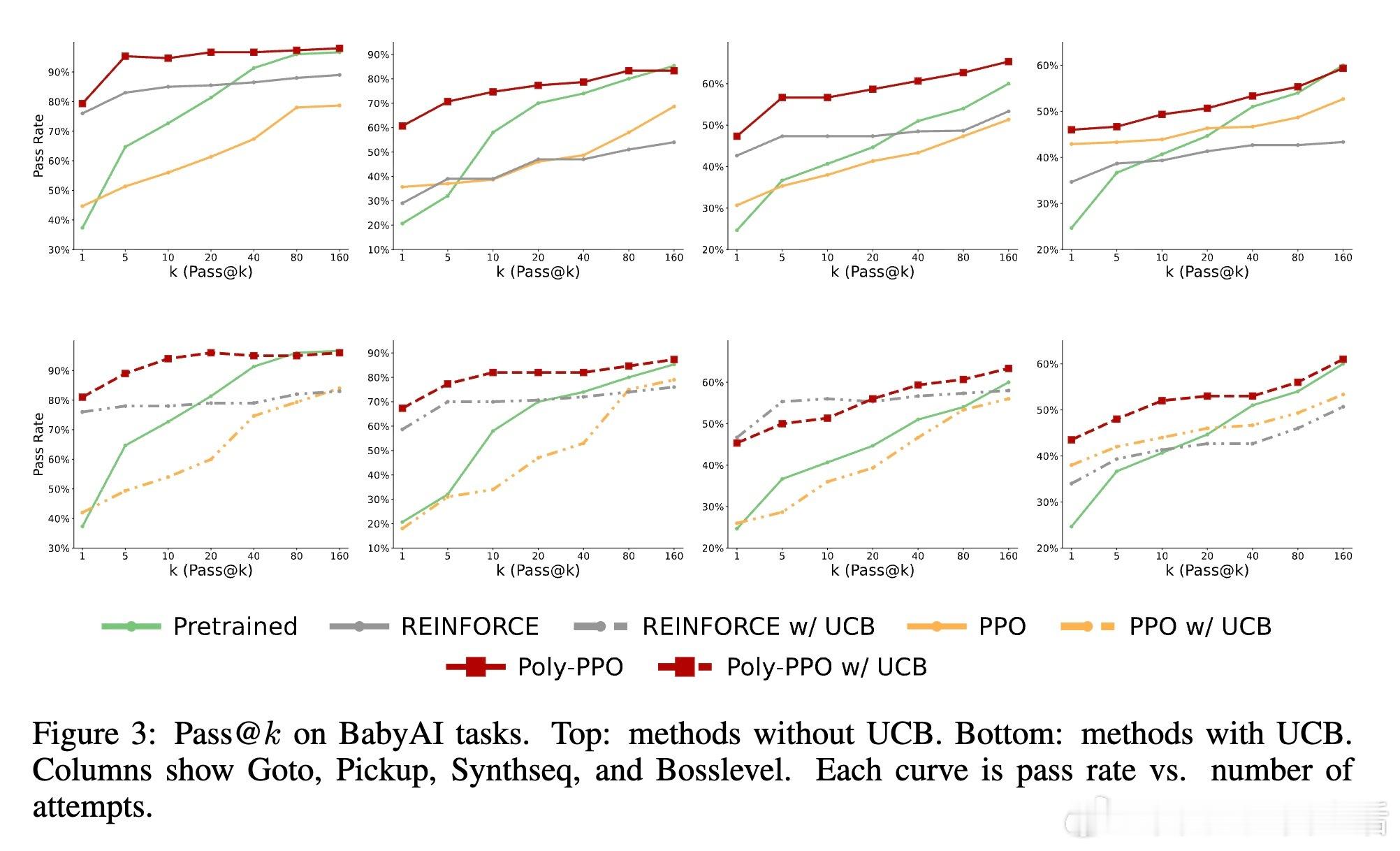
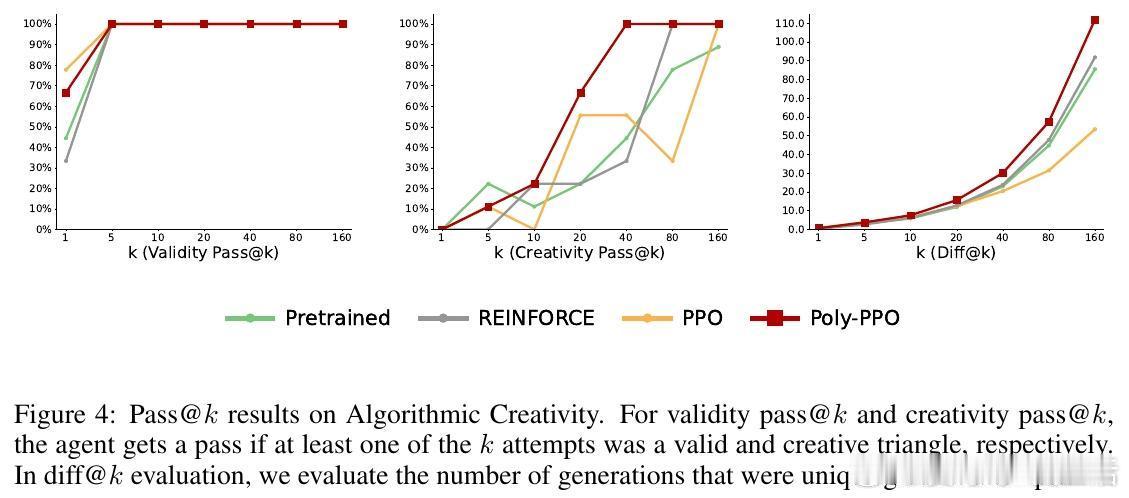
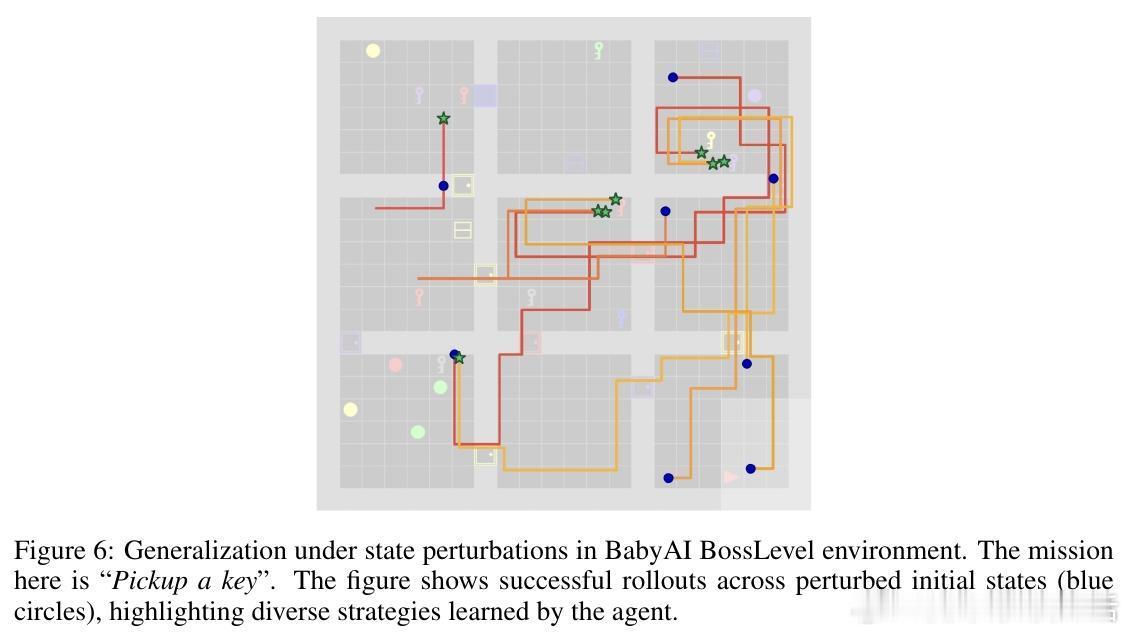
- 在BabyAI、MiniGrid和Algorithmic Creativity任务中,多彩PPO显著提升成功率和任务覆盖率,尤其在pass- 多彩PPO在状态扰动下泛化能力更强,显示出更鲁棒的探索策略。
- 通过熵分析理论证明,多彩目标自动避免策略向单一行为坍缩,反而引导策略关注含有多样成功动作的轨迹集。
🧩方法优势:
- 统一框架兼顾探索与利用,解决了传统熵正则无法有效促进语义或轨迹级多样性的问题。
- 适用性强,可配合不同多样性度量指标,灵活调整。
- 结合vine采样,样本利用率高,适合环境可重置的任务。
⚠️局限与未来方向:
- 依赖环境可重置以实现vine采样,限制适用范围。
- 长时序任务中保证足够vine覆盖难度较大。
- 多样性函数设计依赖任务知识,连续动作空间扩展尚需探索。
- 目前优势估计为蒙特卡洛,存在方差问题,未来可开发更高效估计器。
总结:本文提出的多彩目标和多彩PPO为强化学习微调中保持探索多样性提供了新的理论视角和实用算法,促进策略在复杂任务中实现更广泛的成功和更强的泛化能力,具有重要的理论意义和应用价值。
论文链接:arxiv.org/abs/2509.25424
强化学习 多样性探索 PPO 策略微调 机器学习