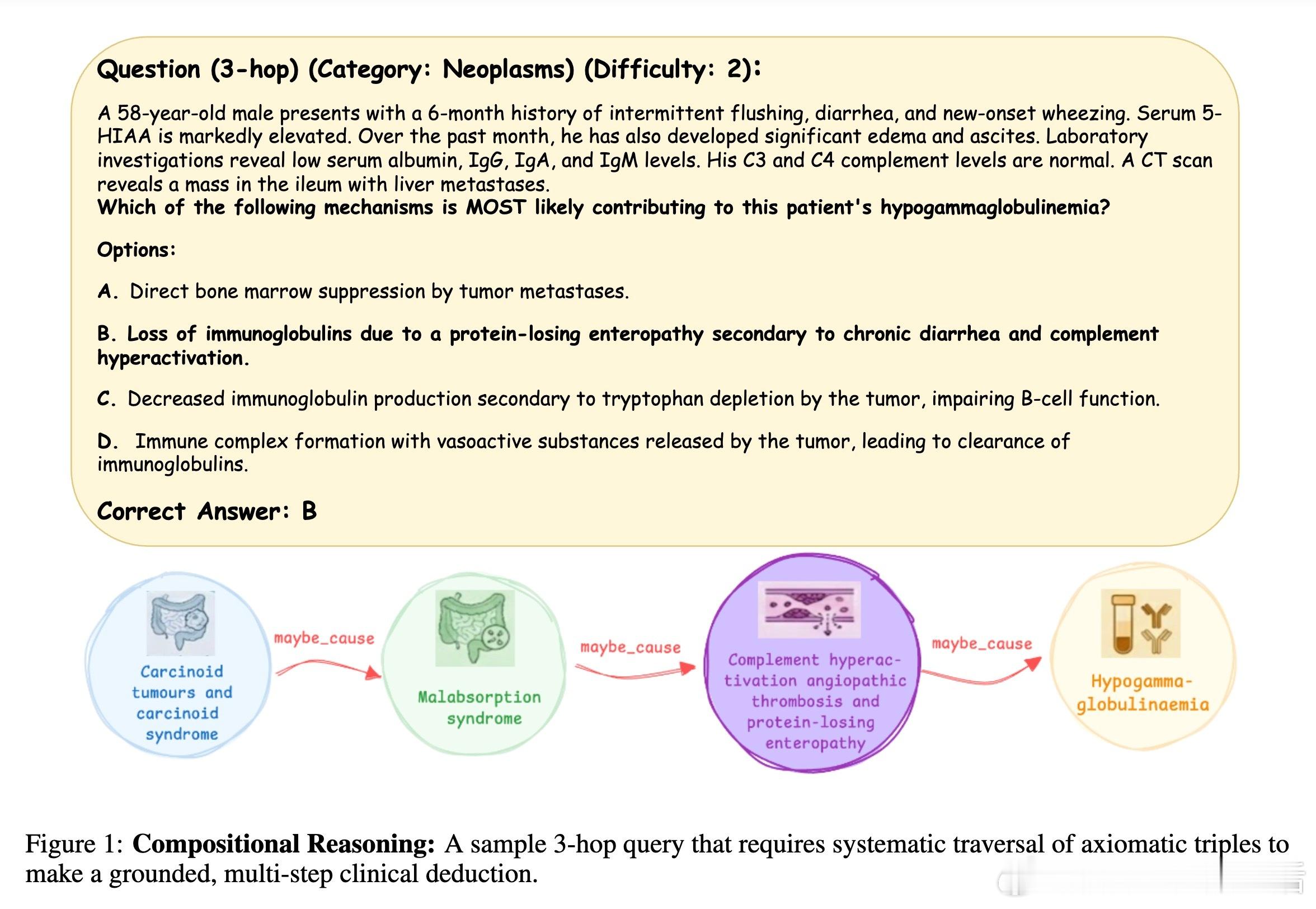
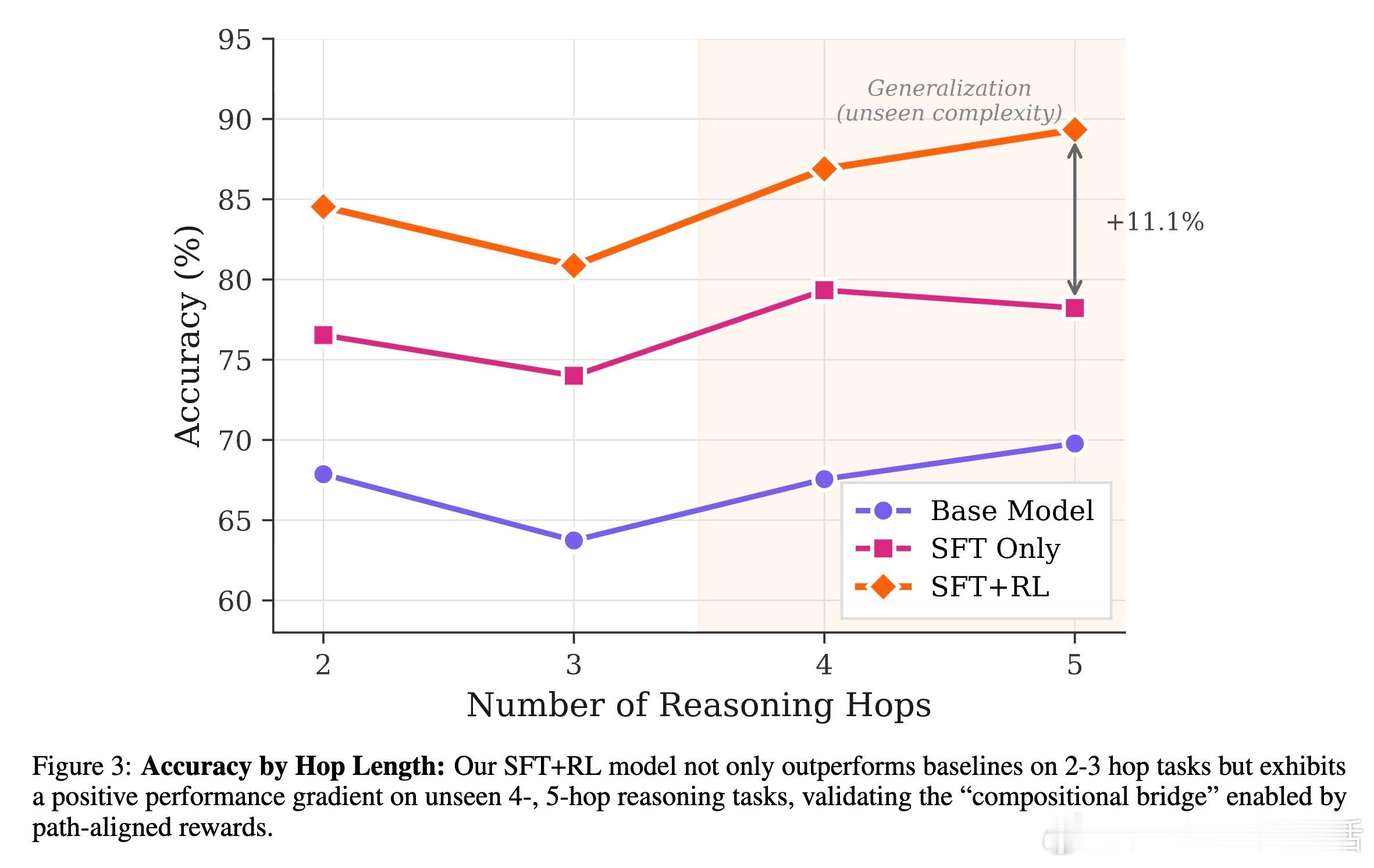
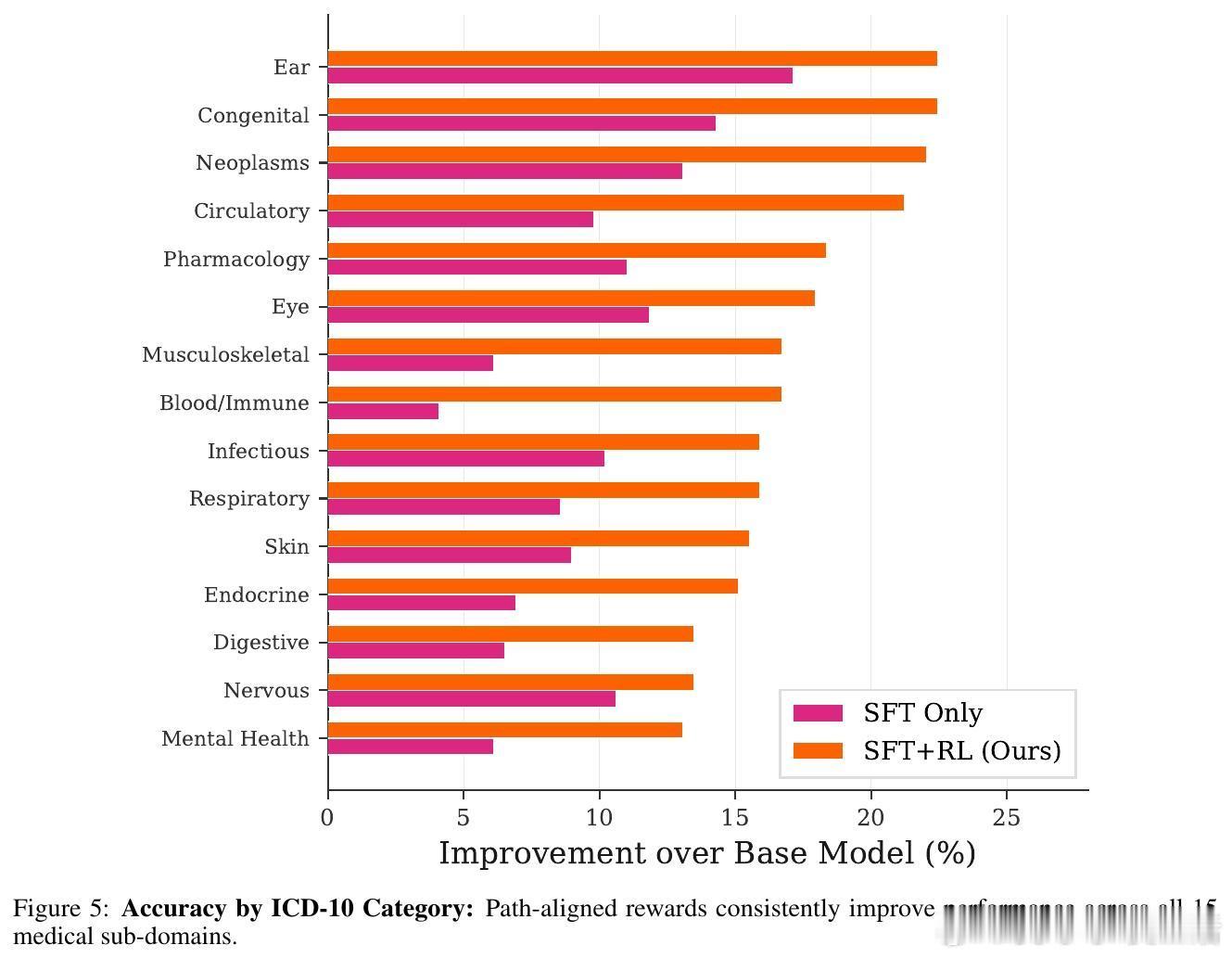
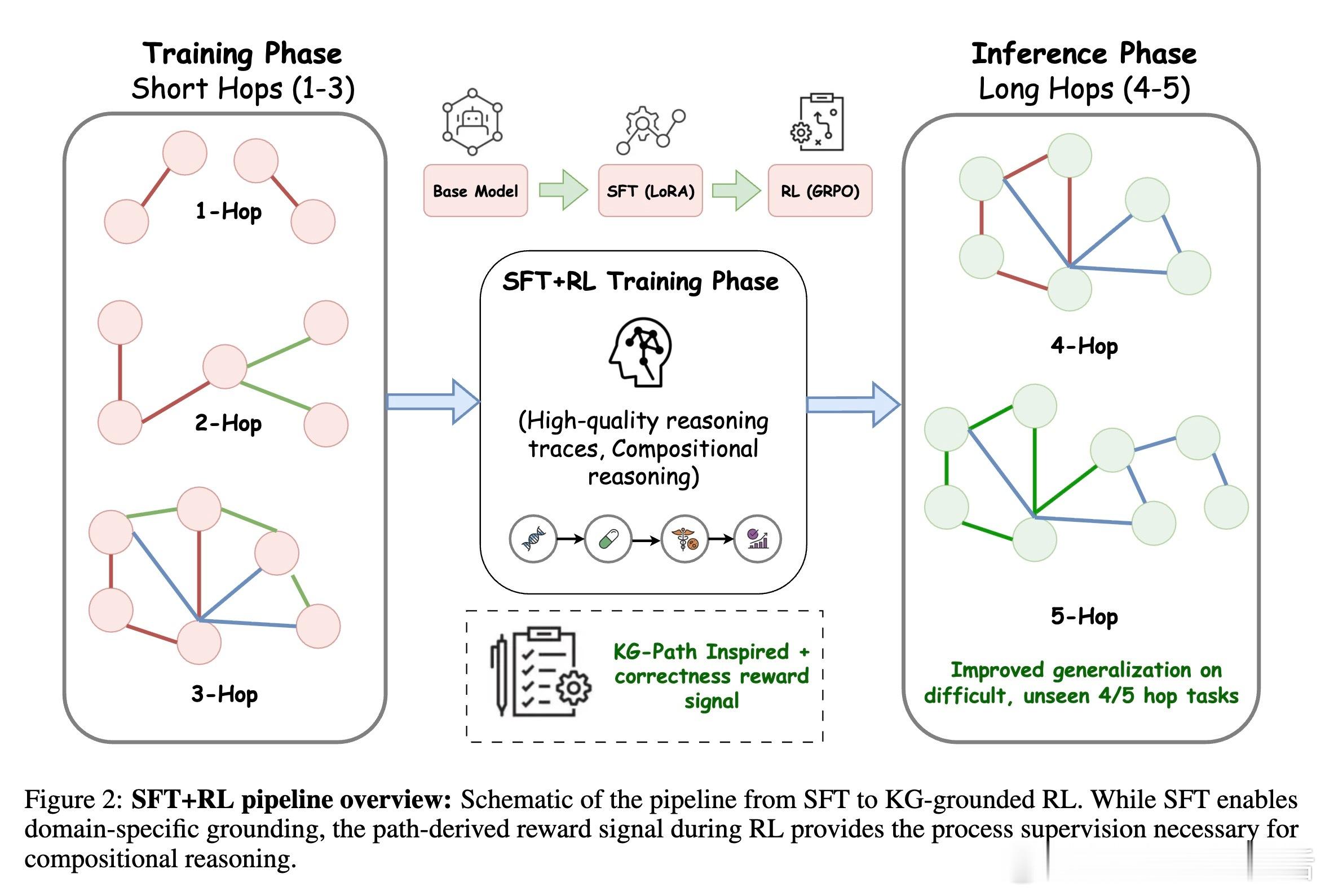
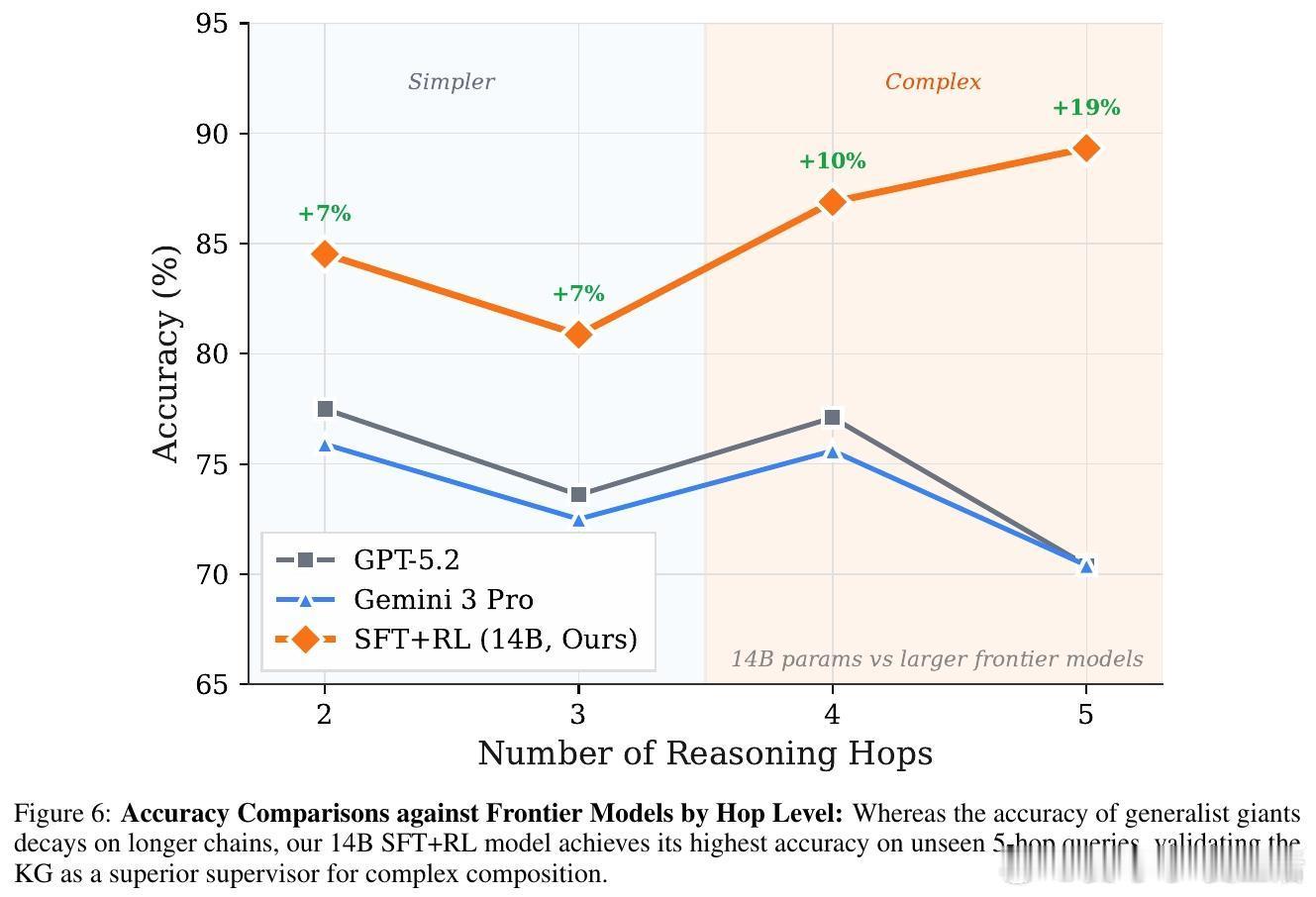
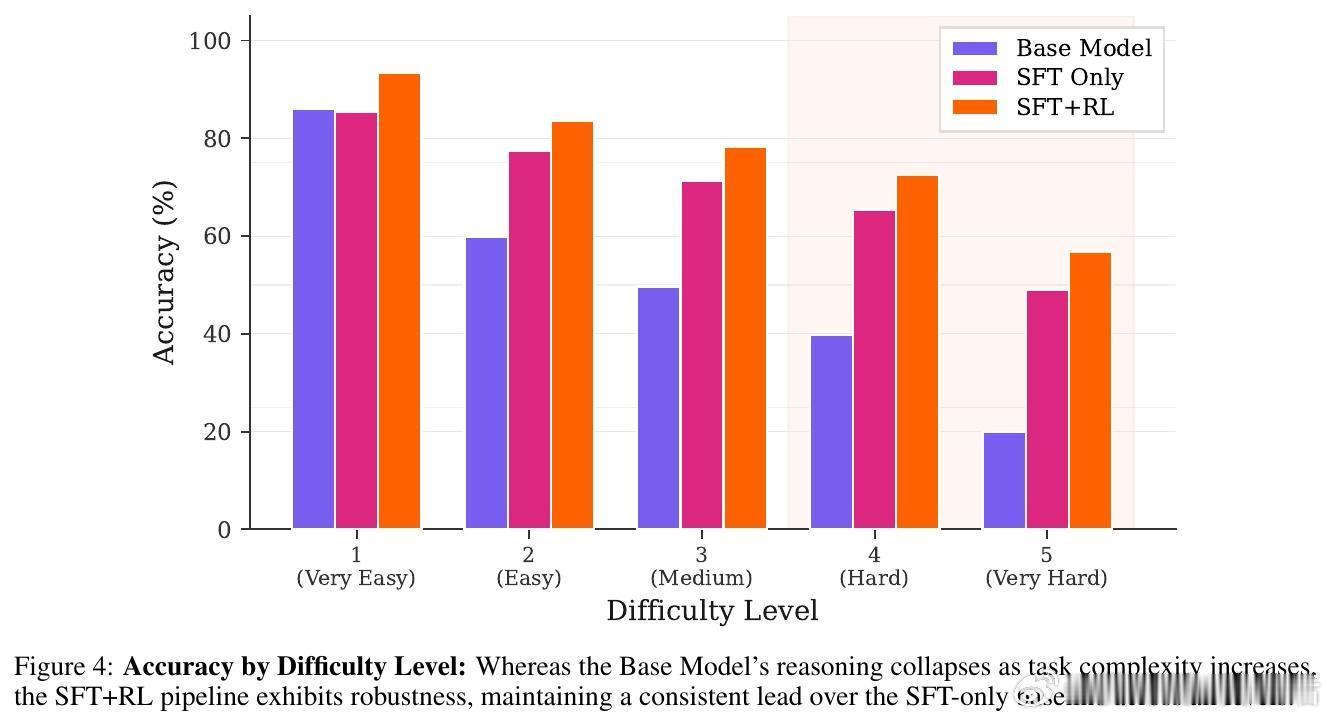
[LG]《Knowledge Graphs are Implicit Reward Models: Path-Derived Signals Enable Compositional Reasoning》Y Kansal, N K. Jha [Princeton University] (2026) 大模型在医疗、法律等深水区总是“幻觉”不断?或许是因为我们一直试图用“大力出奇迹”的规模化思维,去解决需要“严谨逻辑”的组合推理问题。本文提供了一个极具启发性的新范式:将知识图谱(KG)转化为强化学习中的“隐式奖励模型”,让模型从底层公理开始,学会真正的逻辑构筑。以下是这项研究的核心洞察与深度解析:1. 规模的瓶颈:SFT 记住了知识,但 RL 才能学会泛化目前的后训练(Post-training)大多依赖人类偏好。但在医学等高门槛领域,人类标注不仅昂贵,且往往只能评价“结果好不好看”,无法评价“逻辑对不对”。研究发现,单纯的监督微调(SFT)更像是在给模型灌输“标准答案”的记忆,而强化学习(RL)才是让模型在未知领域实现逻辑迁移的“手术刀”。2. 知识图谱:不仅是数据库,更是过程验证器这项研究的神来之笔在于:不再把知识图谱仅仅当作检索工具,而是将其作为 RL 过程中的“裁判”。研究者设计了一种基于路径驱动的奖励信号(Path-Derived Signals)。当模型在思考过程中,其推理路径与知识图谱中的公理三元组(头实体、关系、尾实体)吻合时,就给予奖励。这意味着模型不仅要答对,还必须“走对路”。3. 组合能力的跨越:从短程训练到长程推理最令人惊叹的实验结果是:模型在 1-3 跳(Hops)的简单推理路径上进行训练,却在从未见过的 4-5 跳复杂临床问题上展现了极强的泛化能力。这种“组合桥梁”效应证明了:一旦模型掌握了公理组合的底层逻辑,它就能像玩乐高一样,将简单的知识块拼凑成复杂的诊断链条。4. 降维打击:14B 模型超越 GPT-5.2 等巨头实验显示,经过知识图谱路径奖励优化的 Qwen 14B 模型,在医学推理任务 ICD-Bench 上的表现显著优于 GPT-5.2 和 Gemini 3 Pro 等参数量大得多的通用旗舰模型。这说明在专业领域,精准的“逻辑约束”比盲目的“参数规模”更有效。5. 抵御“幻觉”的韧性通过对选项随机打乱的压力测试发现,这种基于路径支撑的模型表现极其稳定。它不是在通过概率预测寻找“长得像答案”的选项,而是通过验证推理链条来推导结论。这种从第一性原理出发的推理,才是安全敏感领域最需要的智能。启发与思考:- 智能的本质不仅是联想,更是公理的组合。- 知识图谱这种“老派”的符号逻辑,正在通过奖励模型的方式,成为神经网络最坚实的骨架。- 未来的超级智能或许不是一个通晓万物的庞然大物,而是由无数个在特定领域掌握了“组合逻辑”的专业模型构成的矩阵。底层公理是智能的砖块,而路径奖励则是将它们砌成大厦的粘合剂。arxiv.org/abs/2601.15160v1