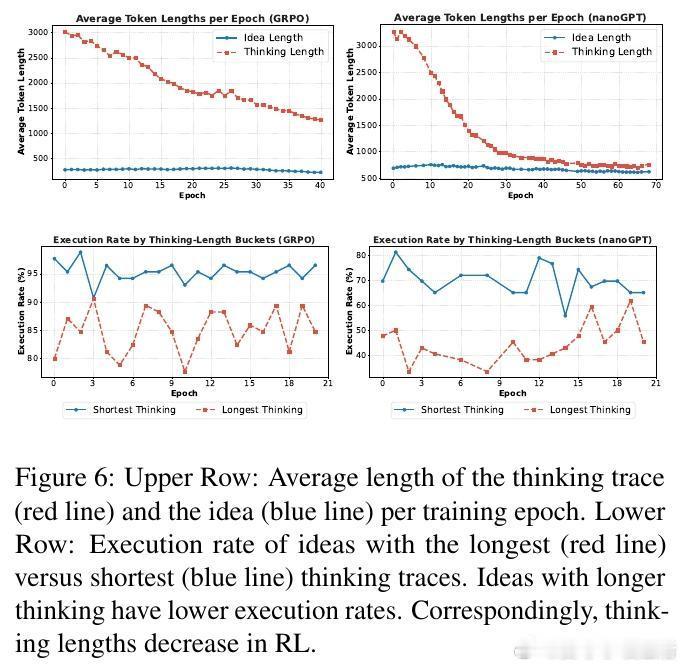
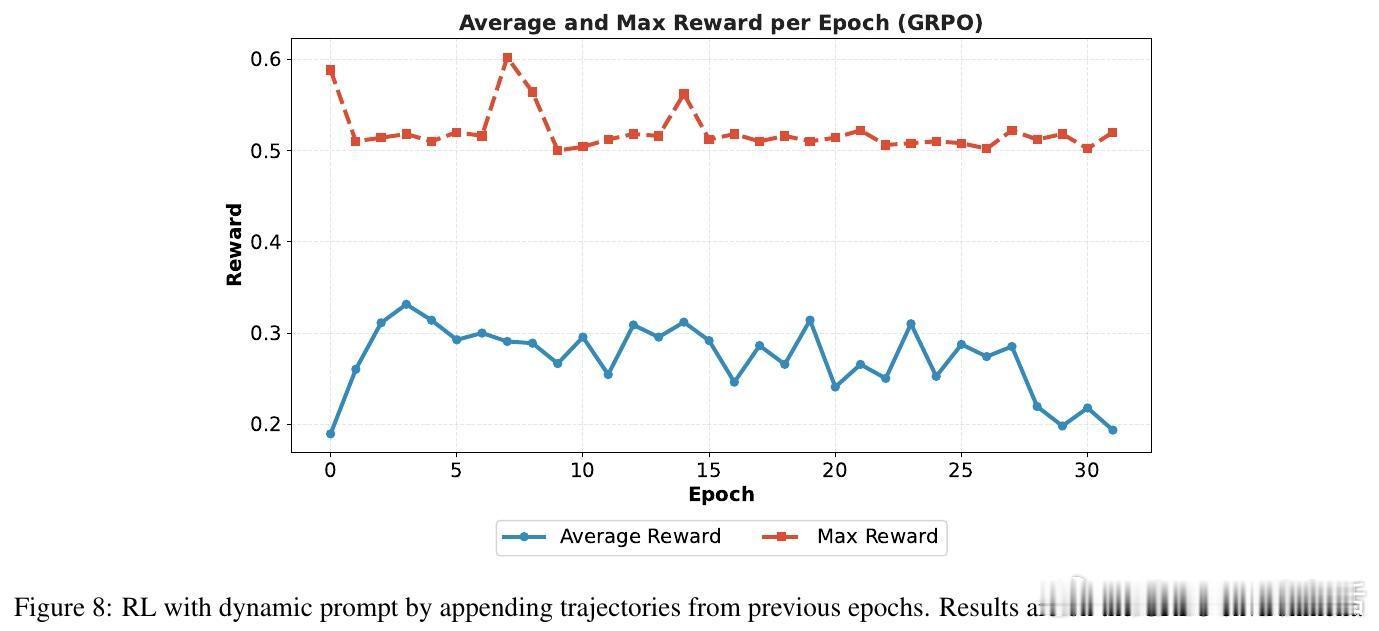
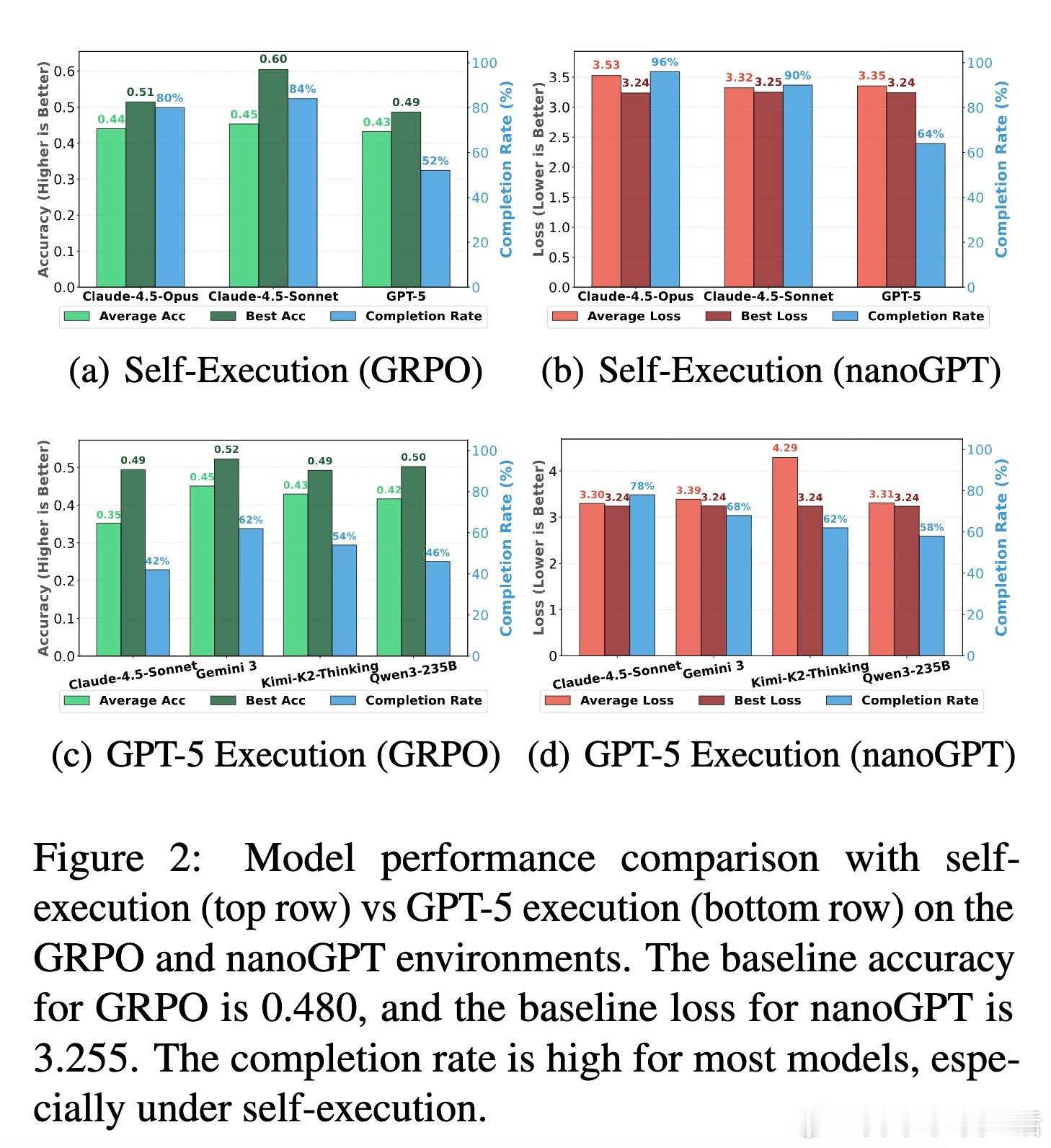
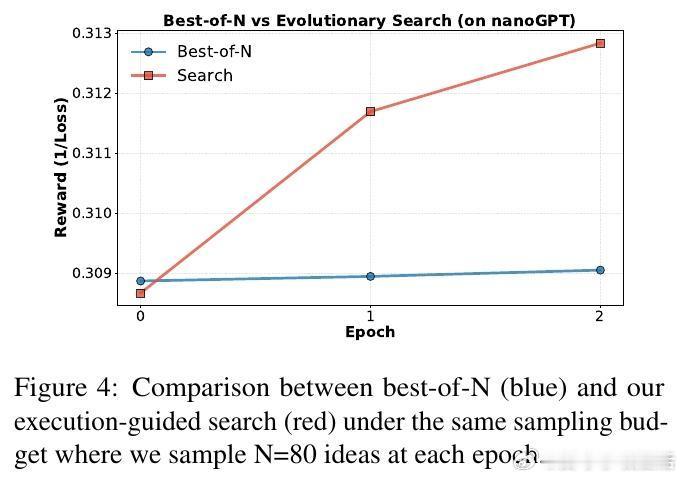
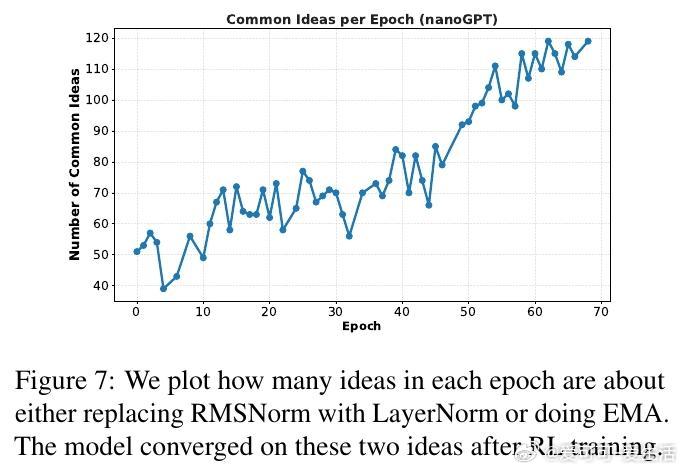
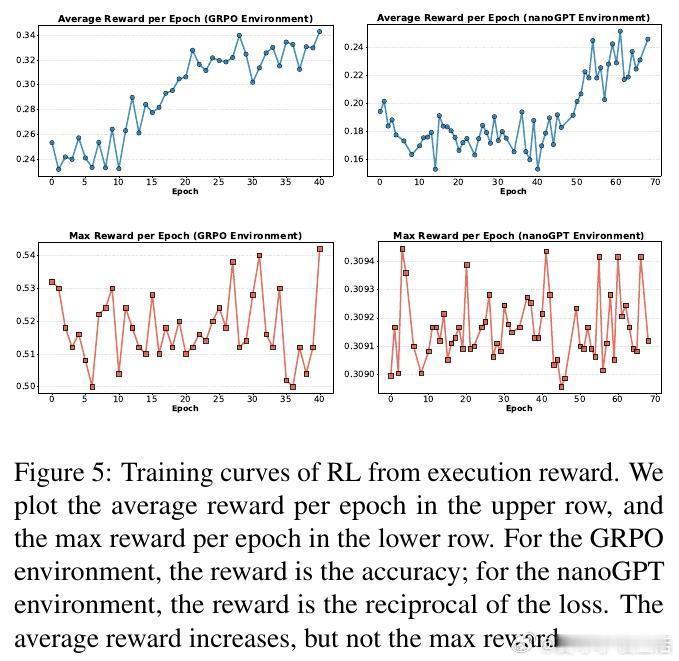
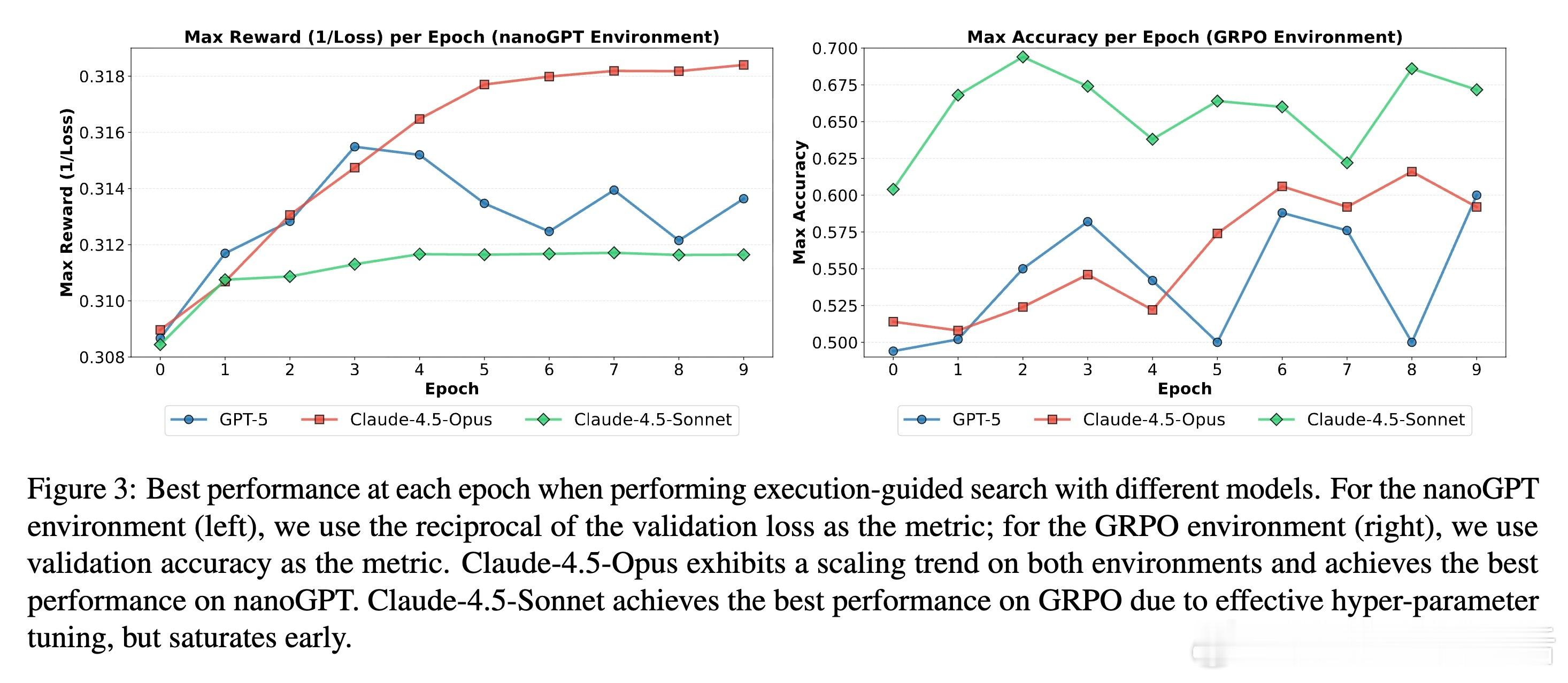
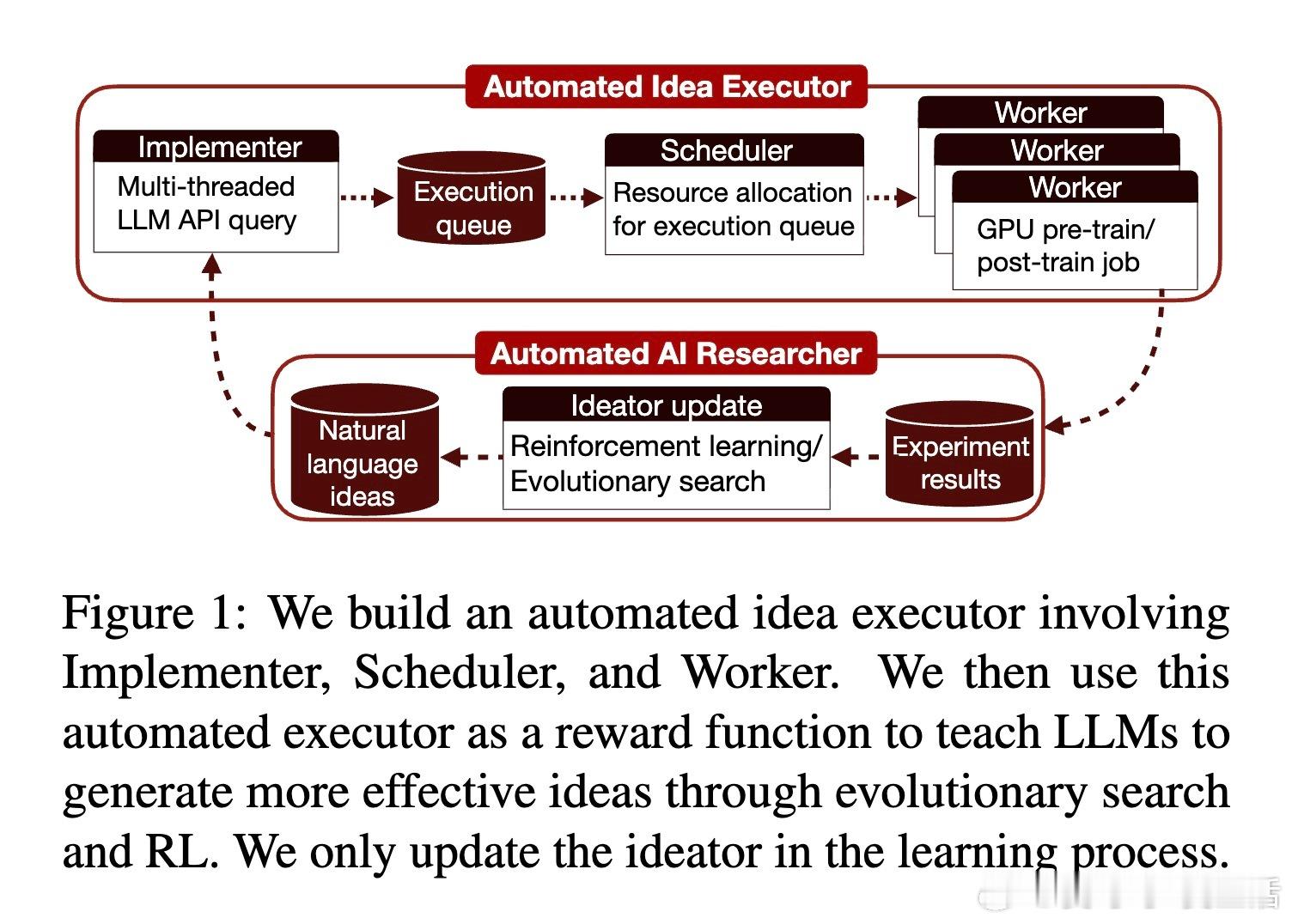
[CL]《Towards Execution-Grounded Automated AI Research》C Si, Z Yang, Y Choi, E Candès... [Stanford University] (2026) 长期以来,AI 领域一直梦想着实现“自动化科研”:让模型自己提出想法、写代码验证、跑实验,并根据结果自我进化。然而,目前的 LLM 往往只能产出“看起来很有道理”但实际无效的幻觉想法。本文试图打破这一僵局。他们构建了一个全自动的执行系统,让 AI 研究不再停留在纸上谈兵,而是真正落地于代码与算力。科研的本质不是辞藻的堆砌,而是对真理的实证。研究团队开发了一个自动化执行器,包含实现者、调度器和工作站。它能将自然语言构思转化为代码补丁,并在 H100 集群上并行运行。这种“闭环”设计解决了科研中最难的一环:从构思到执行的鸿沟。当 AI 拥有了实验权,它就从一个诗人变成了一个工程师。在实验环境中,AI 挑战了两个硬核课题:nanoGPT 预训练优化和 GRPO 后训练增强。结果令人振奋。在进化搜索的驱动下,AI 发现的后训练方案将数学推理准确率从 48% 提升至 69.4%,超越了斯坦福研究生的水平。在预训练任务中,AI 将达到目标损失的时间从 35.9 分钟缩短至 19.7 分钟。这证明了:只要反馈回路足够快,AI 确实能通过自主探索发现人类尚未察觉的算法优化。进化搜索(Evolutionary Search)展现了惊人的样本效率。通过不断在成功的尝试上进行“变异”和“杂交”,Claude-4.5-Opus 等模型展现出了清晰的性能增长曲线。有趣的是,AI 并非只会调参数,它产出了大量原创算法构思,甚至在没有外部检索的情况下,独立“重现”了过去三个月内人类顶尖论文中的核心思想,如多样性奖励和上下文压缩。这说明 AI 已经具备了在已有知识边界进行逻辑外推的能力。然而,强化学习(RL)在科研发现中却遭遇了“平庸之陷阱”。研究发现,虽然通过 RL 训练可以提高构思的平均奖励,但却无法提升上限(Max Reward)。原因在于“多样性崩溃”:为了获取稳定的奖励,模型学会了走捷径,反复生成简单、易实现且稳赚不赔的平庸想法。科研的本质是寻找那 1% 的突破,而标准的 RL 算法却在鼓励 99% 的顺从。另一个深刻的洞察是“思维长度的萎缩”。在 RL 过程中,模型的思考过程(Thinking Trace)变得越来越短。数据分析揭示了残酷的现实:思考越深入、构思越复杂的想法,往往越难被自动化系统完美执行。模型为了规避执行失败带来的零分惩罚,主动选择了“思想懒惰”。这警示我们:如果评价体系只看结果,AI 可能会为了成功率而放弃对深奥真理的探索。真正的科研自动化,不只是算力的堆砌,更是对“失败”的重新定义。这项研究为我们揭示了自动化科研的未来图景:我们需要更强大的执行代理,以及能够鼓励探索、容忍失败的学习算法。当 AI 能够从失败的实验日志中汲取灵感,而不仅仅是追逐成功的奖励分数时,递归式的自我改进(Recursive Self-improvement)才真正开启。科研是人类最后的堡垒,而现在,AI 已经拿到了通往实验室的钥匙。arxiv.org/abs/2601.14525