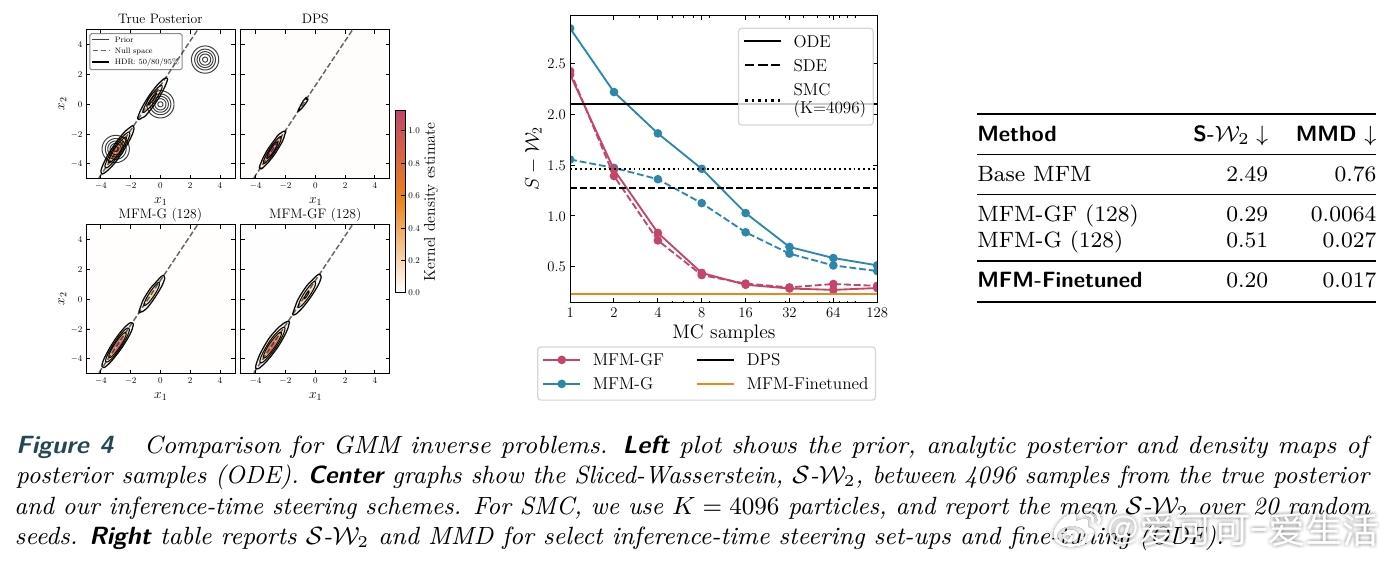
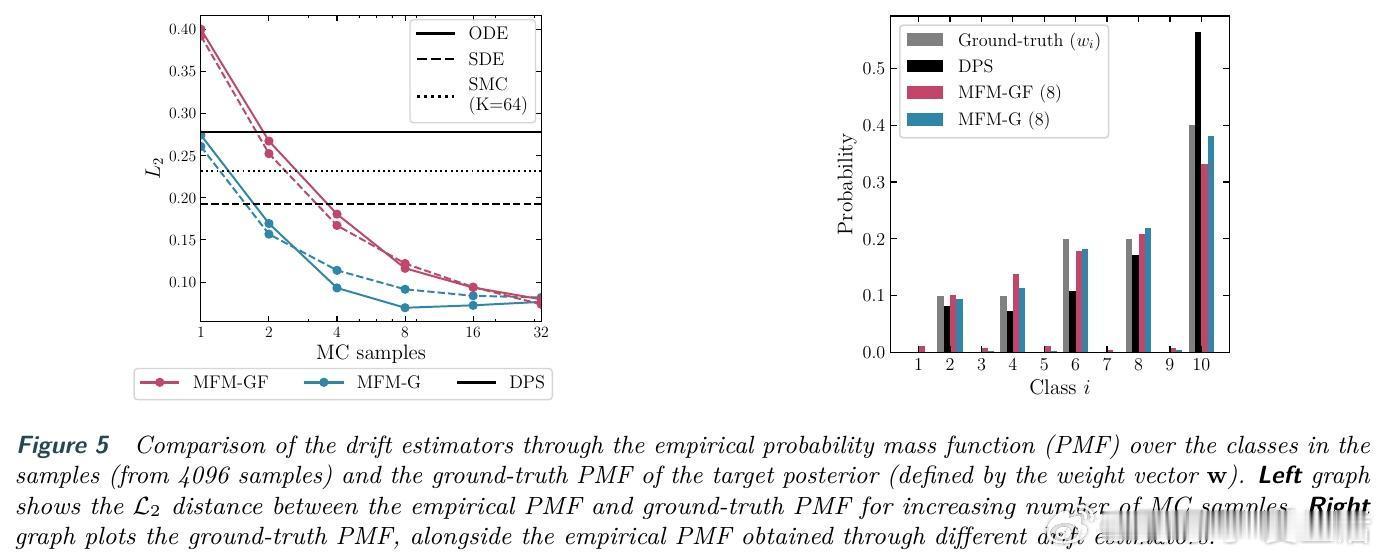
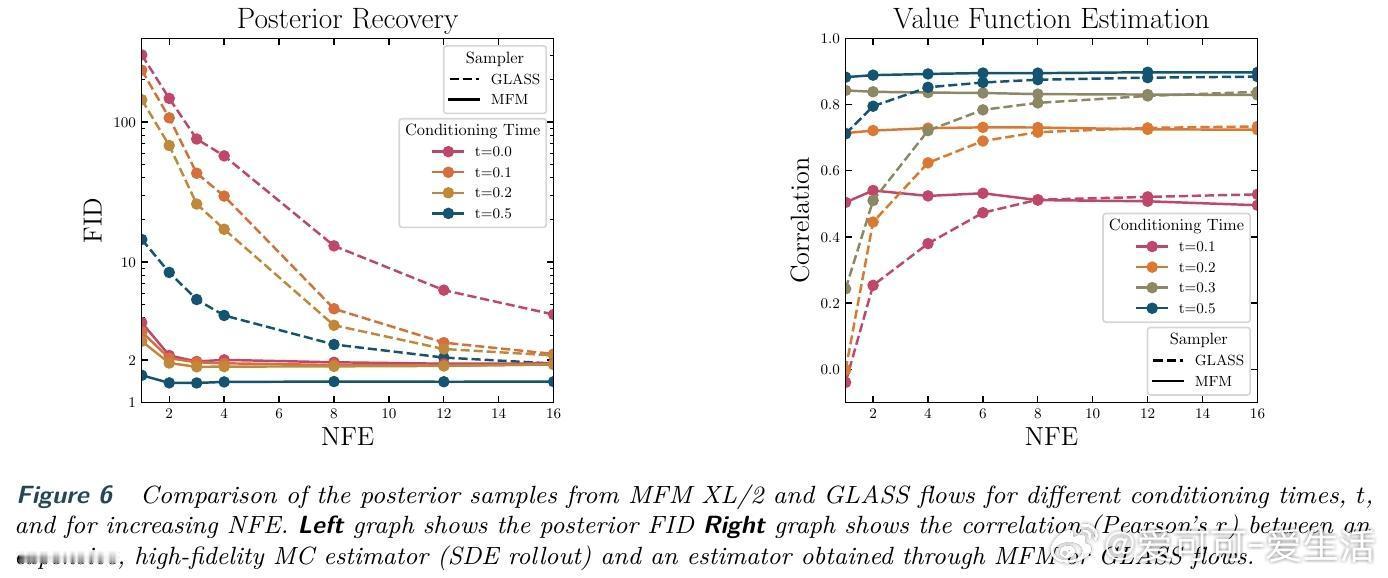
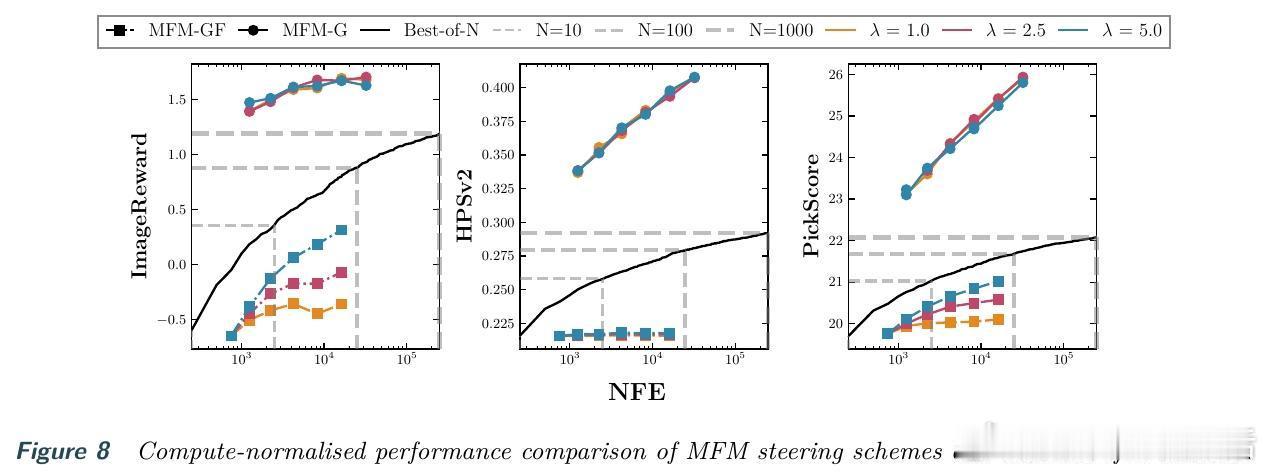
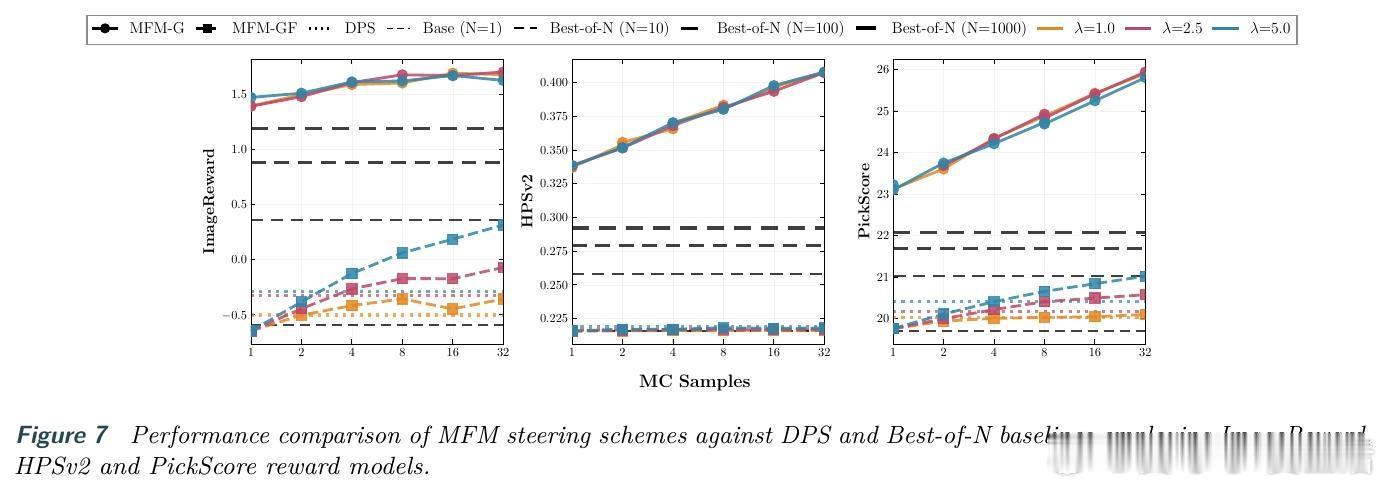
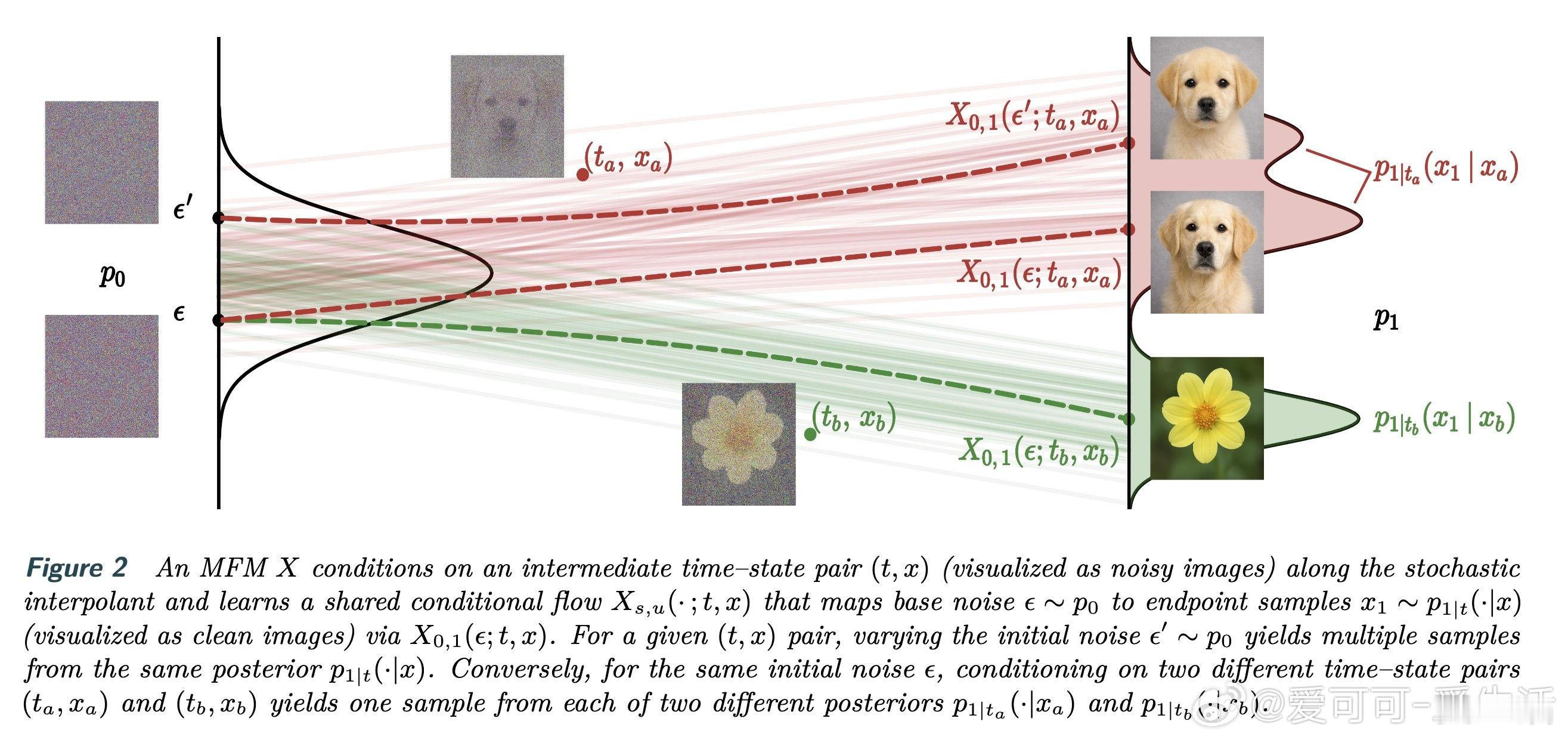
[LG]《Meta Flow Maps enable scalable reward alignment》P Potaptchik, A Saravanan, A Mammadov, A Prat... [University of Oxford] (2026) 生成模型如何实现高效的奖励对齐?这在过去一直是一个计算昂贵且难以平衡的难题。本文提出了 Meta Flow Maps(MFM),通过一种全新的随机流映射机制,彻底打破了对齐过程中的计算瓶颈。以下是关于这项研究的深度解析:1. 昂贵的代价:对齐的计算税在生成模型中,无论是推理时的引导还是训练时的微调,核心挑战都在于估算价值函数。为了知道当前状态是否通往高奖励的终点,传统方法必须进行大量的内部模拟。这种反复迭代的模拟就像是在每走一步前都要预演一千种人生,计算成本极高。2. 破局者:Meta Flow MapsMFM 的核心贡献是将一致性模型和流映射扩展到了随机领域。它不再只是预测一个确定的终点,而是学习了一个随机流映射。这意味着从任何中间状态出发,MFM 都能通过一步采样,直接生成无数个符合后验分布的清晰样本。3. 从确定性到随机性的跨越传统的流映射是确定性的,会将输出坍缩到单个点,因此无法捕捉后验分布的多样性。MFM 则引入了随机性,它像是一个元学习器,同时掌握了无数个通往后验分布的概率流。这种可微的重参数化能力,让价值函数的梯度估算变得前所未有的简单。4. 推理引导:不再需要内部演练借助 MFM 提供的单步后验采样,我们可以在推理阶段直接进行高效引导。实验证明,在 ImageNet 任务上,基于 MFM 的单粒子引导采样器,仅需极小的计算量,就能在性能上超越传统的 Best-of-1000 基线。5. 微调的新范式:无偏且离策在微调方面,MFM 实现了无偏的离策学习。由于它能直接提供后验分布的梯度信息,模型可以永久性地吸收奖励函数的偏好,而不需要昂贵的在线模拟。这为通用奖励函数的对齐提供了一种可扩展的工业级方案。6. 深度思考:计算的摊销与控制的本质MFM 的成功告诉我们,控制的本质是对未来的高效预测。通过在基础模型训练阶段摊销掉昂贵的模拟成本,我们实际上赋予了模型一种即时的直觉。这种将复杂动力学压缩进单步映射的能力,正是实现大规模智能对齐的关键。7. 总结与启示Meta Flow Maps 不仅仅是一个加速工具,它重新定义了我们与生成模型交互的方式。当预测未来的代价降为零,精准的控制将变得触手可及。arxiv.org/abs/2601.14430